从 CVPR 2019 一览小样本学习研究进展

内含 19 篇小样本学习论文介绍!
编译:MrBear
编辑:Pita
AI 科技评论按:随着研究者们对样本利用效率的要求日益提高,小样本学习逐渐成为了 AI 领域以及相关顶会最热门的话题之一。色列特拉维夫大学的在读博士研究生 Eli Schwarts 参加完 CVPR 2019 后,针对今年 CVPR 2019 的热点之一——小样本学习整理出了一份论文清单,供大家从 CVPR 的维度一览小样本学习在目前的研究进展。
背景
最近,小样本物体识别成为了一个热门的研究课题(CVPR 2018 收录了 4 篇关于小样本学习的论文,而到了 CVPR 2019,这一数量激增到了近 20 篇)。通常情况下,在训练时你有许多可以使用的各类样本;然后,在测试时,你会面对新的类别(通常为 5 类),其中每个类别仅有极少量的样本(通常每类只有 1 个或 5 个样本,称为「支持集」),以及来自相同类别的查询图像。
接下来,本文将把小样本方法划分为 5 个不同的类别(尽管这些类别并没有明确的界定,许多方法同时属于不止一个类别)。
「Older」指的是基于度量学习的方法,其目标是学习一个从图像到嵌入空间的映射,在该空间中,同一类图像彼此间的距离较近,而不同类的图像距离则较远。我们希望这种性质适用于那些没有见过的类。
在这之后,就到元学习方法了。这类模型建立在当前所面对的任务的基础上,因此使用不同的分类器作为支持集的函数。其思路是寻找模型的超参数和参数,这样一来在不对使用的小样本过拟合的条件下可以很容易地适应新的任务。
与此同时,数据增强方法也十分流行。其思想是学习数据增强的方式,从而可以通过少量可用的样本生成更多的样本。
最后,基于语义的方法正在逐渐兴起。这类方法受到了零样本学习(zero-shot learning)的启发,其中分类任务的完成仅仅基于类别的名称、文本描述或属性。当视觉信息稀缺时,这些额外的语义信息也可能很有用。
本文涉及到的论文
度量学习方法
论文:Revisiting Local Descriptor based Image-to-Class Measure for Few-shot Learning,Li et. Al
论文地址:https://arxiv.org/abs/1903.12290?source=post_page
论文:Few-Shot Learning with Localization in Realistic Settings,Wertheimer et. Al
论文地址:https://arxiv.org/abs/1904.08502?source=post_page
论文:Dense Classification and Implanting for Few-Shot Learning,Lifchitz et. Al
论文地址:https://arxiv.org/abs/1903.05050?source=post_page
论文:Variational Prototyping-Encoder: One-Shot Learning with Prototypical Images,Kim et. Al
论文地址:https://arxiv.org/abs/1904.08482?source=post_page
元学习方法
论文:Edge-Labeling Graph Neural Network for Few-shot Learning,Kim et. al
论文地址:https://arxiv.org/abs/1905.01436?source=post_page
论文:Task Agnostic Meta-Learning for Few-Shot Learning,Jamal et. al
论文地址:https://arxiv.org/abs/1805.07722?source=post_page
论文:Meta-Transfer Learning for Few-Shot Learning,Sun et. al
论文地址:http://arxiv.org/abs/1812.02391?source=post_page
论文:Generating Classification Weights with GNN Denoising Autoencoders for Few-Shot Learning,Gidaris et. al
论文地址:http://arxiv.org/abs/1905.01102?source=post_page
论文:Finding Task-Relevant Features for Few-Shot Learning by Category Traversal,Li et. al
论文地址:https://arxiv.org/abs/1905.11116?source=post_page
数据增强方法
论文:LaSO: Label-Set Operations networks for multi-label few-shot learning,Alfassy et. al
论文地址:https://arxiv.org/abs/1902.09811?source=post_page
论文:Few-shot Learning via Saliency-guided Hallucination of Samples,Zhang et. al
论文地址:https://arxiv.org/abs/1904.03472?source=post_page
论文:Spot and Learn: A Maximum-Entropy Patch Sampler for Few-Shot Image Classification,Chu et. Al
论文地址:http://openaccess.thecvf.com/content_CVPR_2019/papers/Chu_Spot_and_Learn_A_Maximum-Entropy_Patch_Sampler_for_Few-Shot_Image_CVPR_2019_paper.pdf?source=post_page
论文:Image Deformation Meta-Networks for One-Shot Learning,Chen et. al
论文地址:https://arxiv.org/abs/1905.11641?source=post_page
基于语义的方法
论文:Baby steps towards few-shot learning with multiple semantics,Schwartz et. al
论文地址:https://arxiv.org/abs/1906.01905?source=post_page
论文:Generalized Zero- and Few-Shot Learning via Aligned Variational Autoencoders,Schonfeld et. al
论文地址:https://arxiv.org/abs/1812.01784?source=post_page
论文:TAFE-Net: Task-Aware Feature Embeddings for Low Shot Learning,Wang et. al
论文地址:https://arxiv.org/abs/1904.05967?source=post_page
论文:Large-Scale Few-Shot Learning: Knowledge Transfer With Class Hierarchy,Li et. al
论文地址:http://openaccess.thecvf.com/content_CVPR_2019/papers/Li_Large-Scale_Few-Shot_Learning_Knowledge_Transfer_With_Class_Hierarchy_CVPR_2019_paper.pdf?source=post_page
物体识别之外(其它任务中的小样本学习)
论文:RepMet: Representative-based metric learning for classification and few-shot object detection,Karlinsky et. al
论文地址:https://arxiv.org/abs/1806.04728?source=post_page
论文:CANet: Class-Agnostic Segmentation Networks with Iterative Refinement and Attentive Few-Shot Learning,Zhang et. al
论文地址:https://arxiv.org/abs/1903.02351?source=post_page
度量学习方法
Revisiting Local Descriptor based Image-to-Class Measure for Few-shot Learning, Li et. al
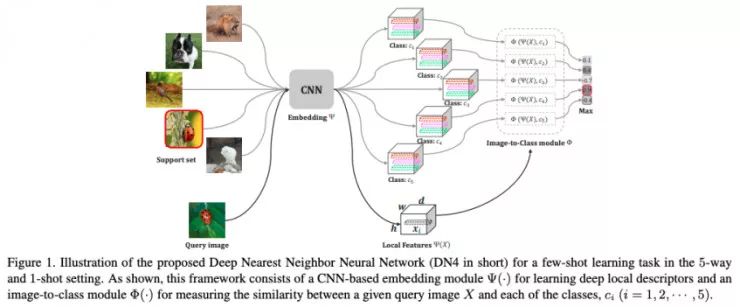
在本文中,作者稍微走起了点怀旧风,采用了词袋(bag-of-words)模型时代使用的局部描述子,但是特征则是使用一个卷积神经网络(CNN)提取到的,而整个学习框架都是端到端的。它的实验结果略微低于对比基准。
Few-Shot Learning with Localization in Realistic Settings, Wertheimer et. Al
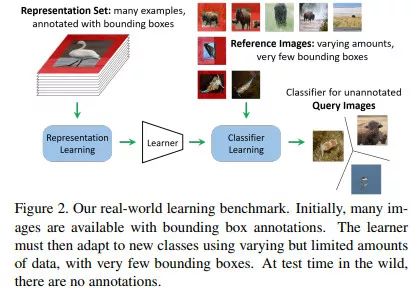
本文声称,标准的小样本学习对比基准测试是不符合现实情况的,因为它们使用的不同类别的数据是被人为设定成平衡的,而且测试时使用的是 5 类样本,因此本文作者建议使用一个新的数据集/对比基准。同时,让模型同时学习进行定位和分类;这样做显而易见的缺点是需要用到带有边界框标注的数据集。分类器是建立在原型网络之上的,但使用的特征向量是由聚合的前景和背景表征连接而成的。
Dense Classification and Implanting for Few-Shot Learning, Lifchitz et. al
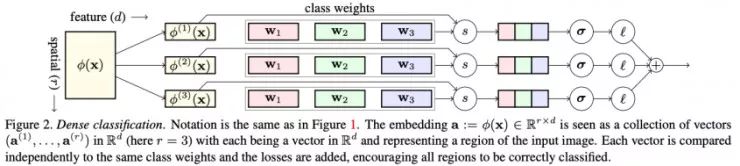
在本文中,分类任务是密集地执行的,即所有的空间位置都需要被正确地分类,而不是在最后进行全局平均池化处理。此外,在测试期间,本文作者并不是在最后一层才进行调优,而是通过添加神经元扩大每一层并对它们进行调优(只有额外添加的权重会被训练,旧的权重会被冻结)。
Variational Prototyping-Encoder: One-Shot Learning with Prototypical Images, Kim et. al.
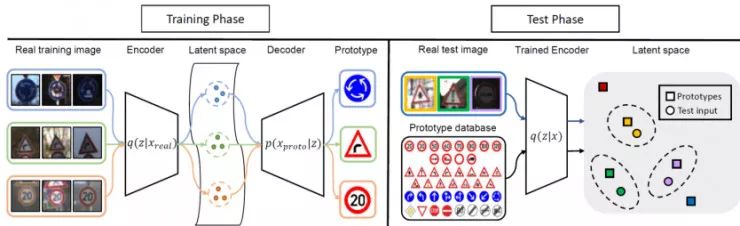
这是一个单样本分类技术的更具体的应用,针对的是标志或路标分类问题。在本例中,作者将标准图形化的图像(与现实中的真实标志/路标相对应)作为原型。他们通过学习一个将真实标志/路标图像映射到原型图像上的元任务学习来学习一种良好的表征。
元学习方法
Edge-Labeling Graph Neural Network for Few-shot Learning, Kim et. al
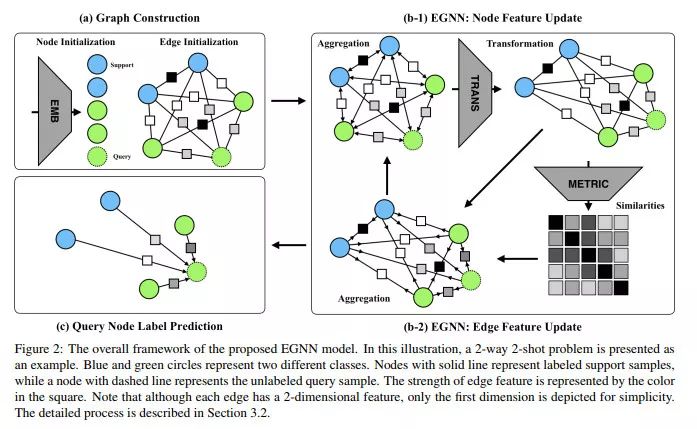
图神经网络已经被用于小样本学习领域。其基本思想是,每个图像都可以作为图中的一个节点来表示,而且信息(节点表征)可以根据它们之间的相似度在它们之间传播。通常而言,分类任务是根据节点表征之间的距离隐式地完成的。在这里,作者建议在每条边上加上显式的特征来描述节点之间的相似度。
Task Agnostic Meta-Learning for Few-Shot Learning, Jamal et. Al
在这项工作中,为了避免元学习模型对训练任务过拟合,作者在输出预测时加入了一个正则化项。正则化要么会使预测具有更高的熵(即预测的概率不会看起来像一个独热矢量),要么使模型在不同任务之间的差异更小(即在不同任务上表现相同)。显然,对于小样本学习来说,有一个强大的正则化机制是十分重要的,但我并不能直观地理解为什么我们需要的是文中体到的特定的正则项。本文作者在 MAML 的基础上测试了该方法,得到了更优的性能。不妨看看将其应用于其它方法上是否也会对性能提升有所帮助!
Meta-Transfer Learning for Few-Shot Learning, Sun et. Al
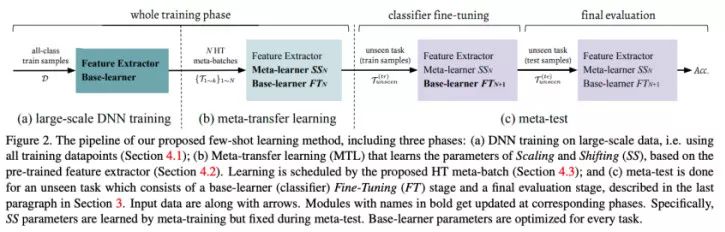
该方法有两个主要的组成部分:(1)对一个预训练的模型调优,其中权值是冻结的,在每一层中只学习放缩和偏置(Scaling and Shifting);(2)困难任务挖掘。如果我没弄错的话,MAML 对批量归一化层进行了调优,这难道不是具有和「学习放缩和偏置」相同的效果吗?似乎将困难批量挖掘(根据之前的任务中具有较低的准确率的类组成的任务)应用到 MAML 上也是有所帮助的。
Generating Classification Weights with GNN Denoising Autoencoders for Few-Shot Learning, Gidaris et. Al
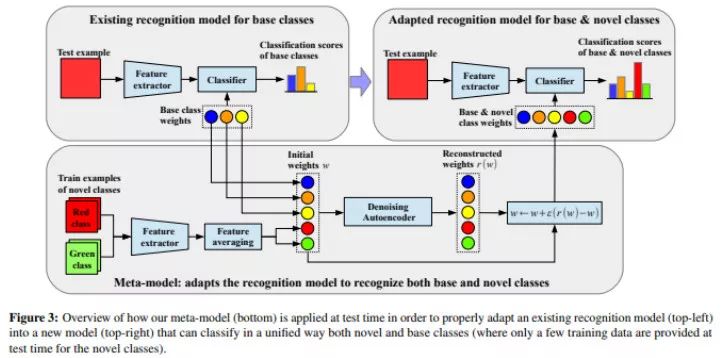
在本文中,作者再次建立模型预测分类器对于未见过的类的权重。此外,所有分类器的权重都会被传递给一个通过一个图神经网络实现的去噪自编码器(基类和任务中的新类别),从而做到:(1)让分类器能够适应当前任务的类别(2)将基类分类器的知识传播给新类分类器。使用去躁自编码器有助于修正预测得到的分类器,因为这些分类器仅仅只基于少量的示例预测得到,有明显的噪声。
Finding Task-Relevant Features for Few-Shot Learning by Category Traversal, Li et. al

给定一个特征提取器,该模型大体上可以预测一个特征向量上的注意力映射。「Concentrator」会分别查看每个类(或图像),而「Projector」则会融合来自任务中所有类的信息来生成注意力映射。「Concentrator」和「Projector」都是通过一个小型的卷积神经网络(CNN)来实现的。我非常喜欢这种简单的模块,当在几个一致的基于度量的方法上使用该模块时,它们总是可以提升性能。
数据增强方法
LaSO: Label-Set Operations networks for multi-label few-shot learning, Alfassy et. al
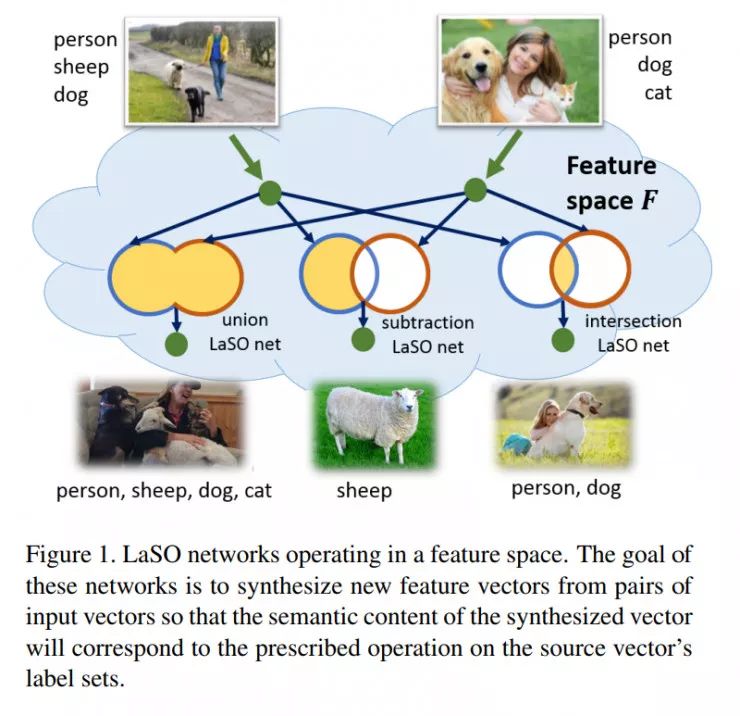
本文的研究课题是多标签小样本分类问题。在本文中,作者训练模型在嵌入空间中对多标签样本的标签集执行集合运算(求并集、差集、交集)。例如,通过对狗和猫的图像求并集,可以得到同时包含狗和猫的图像的表征。之后,作者使用这些操作来增强数据并提高分类性能。
Few-shot Learning via Saliency-guided Hallucination of Samples, Zhang et. Al
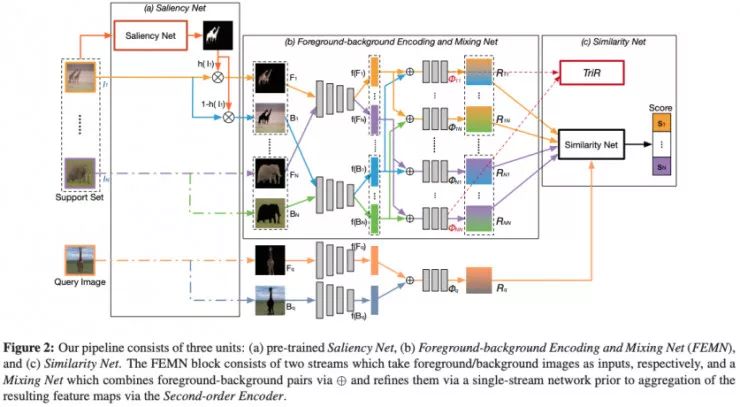
本文采用(在没有交集的类上)预训练的显著性模型分割前景和背景。作者训练了两个特征提取器,一个用于提取前景特征、另一个用于提取背景特征,还有第三个模型用来将前两种特征进行组合。显然,其缺点是你需要一个预训练好的显著性模型。我认为这是一个很棒的增强数据的方式,但是我不确定增强背景数据对于正确的分类有多重要(不像目标检测任务),如果你已经能够分割出前景,那么仅仅使用前景进行分类不是更好吗?
Spot and Learn: A Maximum-Entropy Patch Sampler for Few-Shot Image Classification, Chu et. Al
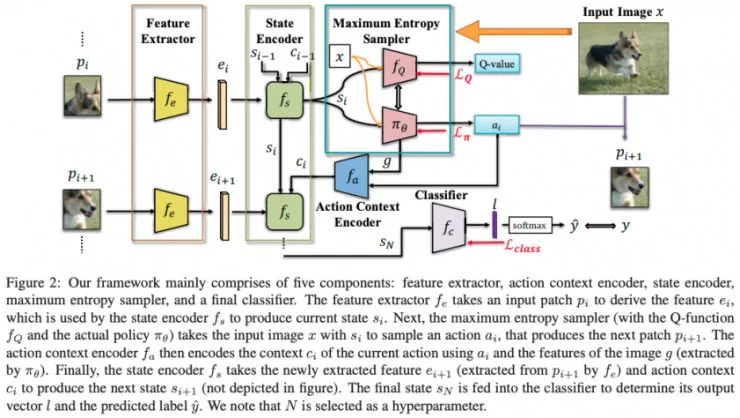
在本文中,作者计算了每一个图块(patch)的表征(而不是仅仅学习整幅图像的表征),然后通过使用了最优图块轨迹的 RNN(即决定下一步应该使用哪一个图块)来聚合这种表征,该轨迹是通过一个强化学习模型预测得到的。与简单的注意力模型相比,我认为该模型由于其具有数据增强方法(对于同一张图像使用不同的轨迹),要更好一些。然而,基准对比测试的结果只能说马马虎虎。我想知道仅仅使用一个随机的轨迹进行增强是否也会起到相同的作用。
Image Deformation Meta-Networks for One-Shot Learning, Chen et. Al
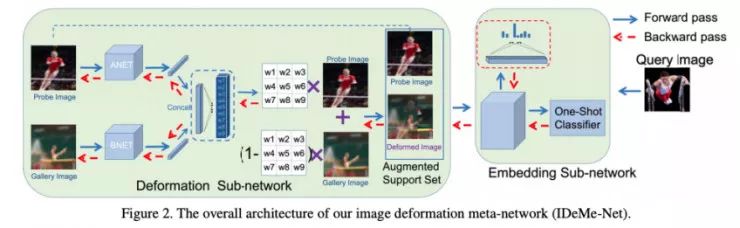
这是一种非常酷的数据增强方法。该方法类似于「mixup」(https://arxiv.org/pdf/1710.09412v1.pdf),但是这里的图像被根据一个网格进行了划分,并且为每个单元使用了不同的预测出的「mixup」系数。模型训练是端到端的,同时进行分类器的学习和对「mixup」的优化(指更好的分类效果)。本文作者将提出的模型与「mixup」进行了对比,但是我们想知道:如果系数是预测得出的而非随机的,「mixup」对整幅图像的效果如何,即不同的「混合」方式对于每个单元的影响如何。
基于语义的方法
Baby steps towards few-shot learning with multiple semantics, Schwartz et. Al
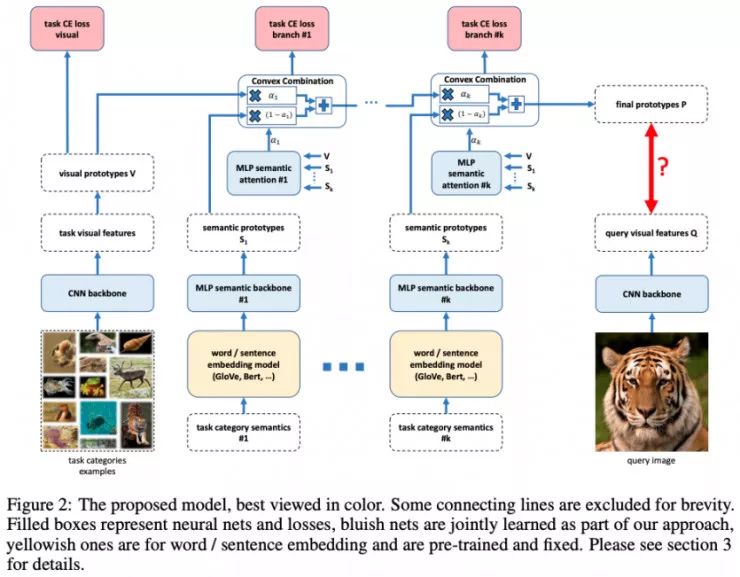
本文作者在 CVPR 的「语言与视觉 Workshop」 上展示了自己的工作。作者基于 AM3 模型[Xing et. al, 2019]构建了自己的模型,并将其泛化,从而利用多种语义。同时,作者还使用了关于类别的短文本描述(这些描述是 ImageNet 的一部分,但是至今仍未被用于小样本学习)来提升性能。从可视化原型开始,他们便采用一系列语义嵌入迭代地更新这些可视化原型。通过这样做,该论文提出的方法实现了目前在 miniImageNet 上最佳的性能。
Generalized Zero- and Few-Shot Learning via Aligned Variational Autoencoders, Schonfeld et. Al
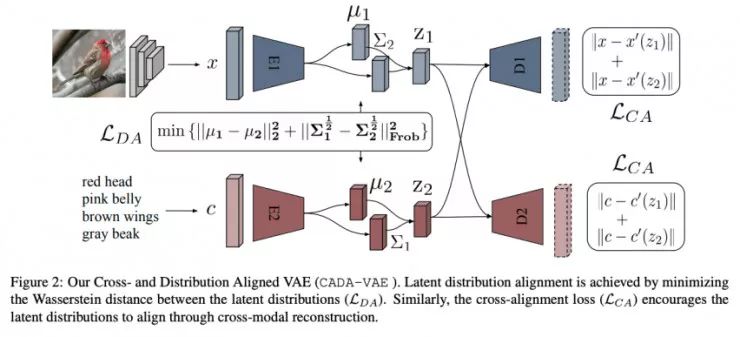
本文作者训练了两个变分自编码器(VAE),一个用于视觉特征,另一个则用于语义特征。其目的是能够根据潜在的视觉特征重建语义特征,反之亦然。作者表明,使得两个潜在空间具有相同的分布也很有帮助。
TAFE-Net: Task-Aware Feature Embeddings for Low Shot Learning, Wang et. Al
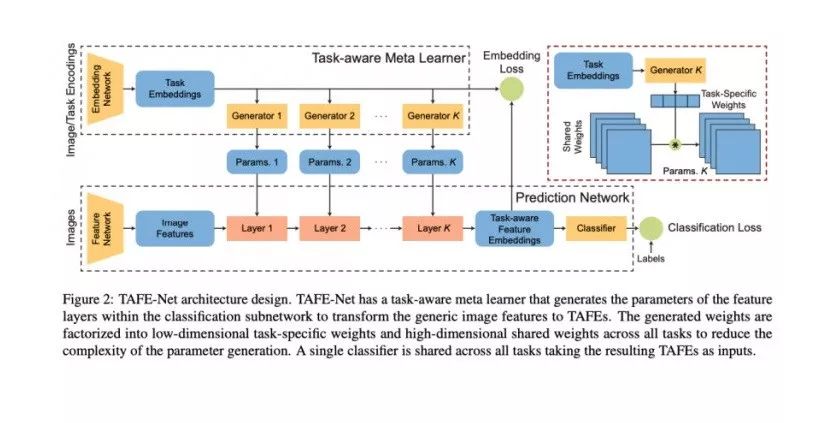
在这项工作中,标签嵌入(GloVe)被用来预测数据特征提取模型的权重。他们提出了一种很好的方法来分解权重,从而只需要预测一个较低维的权重向量。此外,通过「嵌入损失」迫使语义嵌入和视觉嵌入对齐。这篇论文的有趣之处在于,它结合了两种方法:元学习(基于任务来预测模型),以及利用语义信息(标签)。然而,对于小样本学习任务而言,似乎本文提出的模型稍微弱于现有的最佳方法。
Large-Scale Few-Shot Learning: Knowledge Transfer With Class Hierarchy, Li et. Al
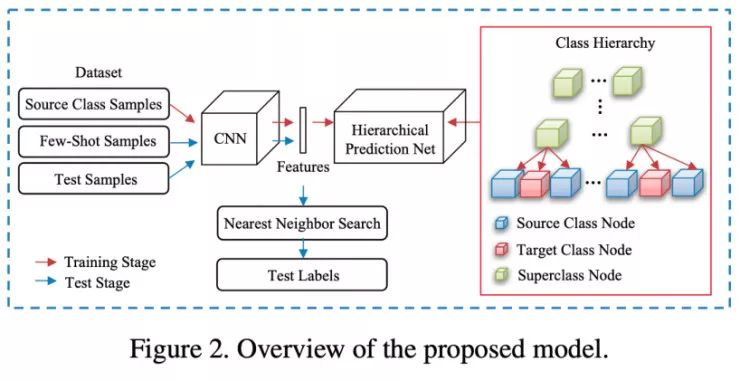
作者声称现有的方法在大规模小样本学习任务往往会失败,例如在 ImageNet 而不是在像 miniImageNet 种的 64 个基类这样的小型数据集上进行预训练,并且其结果也并没有优于简单的对比基线。在本文中,作者也使用了语义标签。他们使用标签嵌入来无监督地构建了一个类别的层次结构,这是一种非常有趣的方法,学习以这种层次化的方式进行分类可能有助于模型捕获那些在未见过的类上表现更好的特征。然而需要警醒的是,将未见过的类标签用于构建类别的层次结构是不是有作弊之虞?
物体识别之外(其它任务中的小样本学习)
RepMet: Representative-based metric learning for classification and few-shot object detection, Karlinsky et. al

该博文的作者也参与了这篇论文的工作。在本文中,作者率先研究了小样本目标检测。他们的解决方案是将一种基于度量的方法(如原型网络)扩展到目标检测任务上。他们使用了一种现成的检测器架构(FPN-DCN),并使用一种基于度量的分类器替换了线性分类器头,在该方法中,对检测出的每个区域的分类是基于特征向量到学到的类别的表征的距离而得出的。论文作者建议为小样本检测问题使用一种新的对比基准,并且展示了该论文提出的方法相对于对比方法的提升。
CANet: Class-Agnostic Segmentation Networks with Iterative Refinement and Attentive Few-Shot Learning, Zhang et. Al
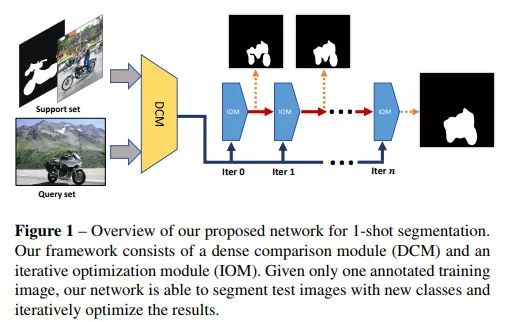
本文将度量学习扩展到了稠密场景下的小样本分割任务中。将查询图像中的所有局部特征与支持集中物体的所有局部特征进行对比的计算开销是非常大的。因此,本文作者选择将查询图像中的局部特征与支持集图像的全局表征进行对比。
Via https://towardsdatascience.com/few-shot-learning-in-cvpr19-6c6892fc8c5

↓ 点击 阅读原文,查看有关 CVPR 2019 更多精彩内容




