用 TensorFlow 目标检测 API 发现皮卡丘!

雷锋网按:本文为雷锋字幕组编译的技术博客,原文 Detecting Pikachu in videos using Tensorflow Object Detection ,作者 Juan De Dios Santos。
翻译 | 于志鹏 整理 | 吴璇
在 TensorFlow 众多功能和工具中,有一个名为 TensorFlow 目标检测 API 的组件。这个库的功能正如它的名字,是用来训练神经网络检测视频帧中目标的能力,比如,一副图像。
需要查看我之前的工作的话,请查看文末链接,我解释了在安卓设备上采用 TensorFlow 识别皮卡丘的整个过程。此外,我也介绍了这个库和它的不同架构及其各自特点,以及演示如何使用 TensorBoard 评估训练过程。
数月之后,我开始着手优化我之前训练的检测皮卡丘的模型,目的是直接使用 Python、OpenCV、以及 TensorFlow 来检测视频中的目标。源代码可以从我的 GitHub 中获取。
Github:
https://github.com/juandes/pikachu-detection

皮卡丘
这篇文章就是解释我所使用的步骤。首先,我会描述我在最初的模型中发现的问题,以及我是如何优化的。然后,我会讲解如何使用这个新的经过优化的模型,我组建了一个视频检测系统。最后,你将会看到两段检测多个皮卡丘的视频。
但开始之前,这里有一个简短的 gif,显示了一些快速检测。

皮卡丘被检测到

这就是皮卡丘
模型优化
如上面所述,在以前的工作中,我对皮卡丘检测模型做了初始的训练,这个模型的目的是在安卓设备或 Python notebook 上进行皮卡丘检测。然而,我对这个模型的性能并不安全满意,这促使我优化这个系统,因此,写下了这篇文章。
我当时主要关心的是用于构建这个系统的皮卡丘数量,230 个。其中 70% 用于训练,而剩余 30% 用于测试。所以,用于训练的数量不多,虽然这在技术上不是问题(因为模型是在执行「okayish」),但我在训练集里增加了 70 张图片(总数依然不是很多,不过总比没有要好)。
结果是,由于我现在拥有更多的图片,我不得不扩展这个模型的训练,而不是从零开始。我使用了早期模型的训练检查点,然后从检查点开始继续进行;前者训练了 15000 次,而新的则训练了 20000 次。下面两幅图表显示了总体的损失和精度 (从 TensorBoard 中获得);很明显,从 15000 次到 20000 次没有太多改变(特别是在损失方面)。
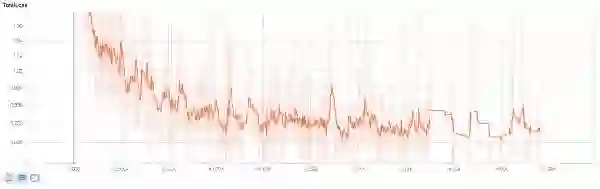
损失
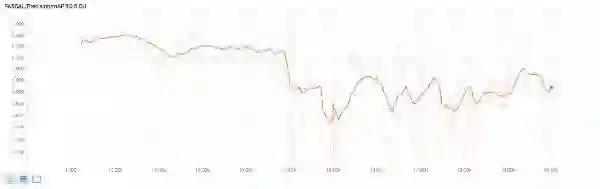
精度
我做的最后一个(也是小的)修正是修改了 Android 应用的检测阈值。默认值是 0.6,增加到 0.85。
这个优化改变了什么吗? 即使将我的确认偏差放在一边,我也会说,是的。我注意到了一个细小的优化。我注意到的最大变化是,Android 应用中误报的数量有所减少,因为那些物体看起来像黄色的斑点;当然,这可能也是因为阈值增加了。
现在,使用最新的和优化后的模型,在视频中检测皮卡丘。继续之前,我需要说明,我将忽略模型冻结和导入的整个过程,因为我之前的工作中已做了解答。
从视频中检测
从视频中进行目标检测并不像听到的那么困难或奇特。从外行角度,我们可以讲视频是一组按顺序排列的图像,所以从视频中进行目标检测和在正常图像中进行检测是非常相似的。为什么非常相似?好吧,由于视频的性质,在将视频输入检测模型之前,视频帧的处理和准备需要多个步骤。我将在下面的章节中将对此做出解释,另外在解释下检测过程,以及如何创建一个新的视频来显示它们。
我的大部分代码都是基于 TensorFlow 目标检测 repo 提供的 Python notebook 实现的。这些代码完成了大部分困难的工作,因为它包括很多功能,可以简化检测过程。我建议你可以看下我的 Script,并作为你阅读下面这几个段落的指导。
从高层视角看,这段代码包括三个主要任务:
加载资源
首先,必须加载冻结的模型、数据标签和视频。为简单起见,我推荐了一个简短、中等大小的视频,因为处理完整部电影需要很多时间。
遍历视频
这个脚本的主要功能是基于一个循环,遍历视频的每一帧。每次遍历过程中,读取帧,并改变其色彩空间。接着,执行实际检测过程,就是寻找所有那些漂亮的黄色皮卡丘。结果是,返回皮卡丘所在位置的边界坐标(如果找到的话)和检测结果的置信度。随后,只要置信度高于给定的阈值,将会创建一个视频帧的副本,其中包含了皮卡丘位置的边界框。对于这个项目,我设置的置信度阈值非常低,20%,因为我发现检测误报数很低,所以决定冒性能的风险来检测到更多的皮卡丘。
创建新的视频
在前面的步骤中,使用新创建的帧副本重新组成一个新的视频,这些帧携带了检测的边界框。为创建这个视频,需要用到 VideoWriter 对象,每次遍历时,帧的副本都会被写入这个对象(不含声音)。
结果和讨论
这两个视频显示了模型的运行过程:
第一个视频的检测非常好。尽管皮卡丘在整个视频中一直举着番茄酱瓶子,在大多数场景中这个模型都能探测到。另一方面,在时间 0:22 时有一个没有被检测到,此外,「大镰刀」(绿螳螂的样子)打碎了番茄酱瓶的镜头(0:40 到 0:44)是误报。
在第二个视频上,这个模型的性能并没有在第一个视频上表现的那么好,主要问题是视频中出现了两个皮卡丘的场景。这种情况下,模型貌似将两个皮卡丘作为一个来检测,而不是分别检测。一个明显的例子是在 0:13 的时候,两个皮卡丘在互相拍打 (悲伤的场景 :(,我知道)。
总结与回顾
在这篇文章中,我介绍了如何使用 TensorFlow 目标检测库在视频中检测皮卡丘。文章开头,介绍了一些我之前的工作,使用模型的早期版本在安卓设备上进行目标检测。至于模型,尽管它做了该做的工作,但也有一些我想要解决的问题;这些优化使我完成了这个项目并建立了一个用于视频的检测模型。
新的模型如预想的那样工作。当然,或多或少也有一些不足之处,导致误判,或者没有检测到皮卡丘,但模型还是完成了它应该做的工作。作为以后的工作方向,我会为训练集合增加更多不同角度的皮卡丘图像。例如,侧视和后视图像,增加数据的多样性,以获得优异的性能。
感谢阅读。我希望这篇指导文章对你能有所帮助。
文章来源:
https://towardsdatascience.com/detecting-pikachu-in-videos-using-tensorflow-object-detection-cd872ac42c1d
安卓上用 TensorFlow 识别皮卡丘:
https://towardsdatascience.com/detecting-pikachu-on-android-using-tensorflow-object-detection-15464c7a60cd

从Python入门-如何成为AI工程师
BAT资深算法工程师独家研发课程
最贴近生活与工作的好玩实操项目
班级管理助学搭配专业的助教答疑
学以致用拿offer,学完即推荐就业

教你从零开始检测皮卡丘 - CNN 目标检测入门教程(上)
▼▼▼





