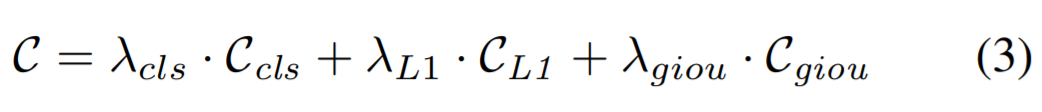选自arXiv
作者:Peize Sun等
机器之心编译
编辑:小舟
目标检测是分类和定位的联合任务,只考虑位置信息的标签分配和网络优化,会导致冗余的高分辨检测框。来自香港大学和字节跳动的研究者提出的 OneNet,首次实现了在 dense detector 中无需 NMS 后处理。
目标检测是计算机视觉领域的基础性任务之一,并且赋能大量的下游应用。当前目标检测器存在的一大挑战是标签分配问题。特别地,如何定义每个目标的正样本和背景的负样本始终是一个悬而未决的难题。数十年来,目标检测中的正样本一直是候选框,它与真值框的 IoU 大于阈值。现代检测器在图像网格上预定义数千个锚框,并在这些候选框上执行分类和回归任务。这种基于框的标签分配方法被称为「框分配」。
尽管多年来候选框方法在目标检测领域占据主导地位,但检测性能容易受到锚框大小、长宽比和数量的影响。为了消除候选框方法的手动设计和复杂计算,研究人员提出了无锚(anchor-free)检测器。无锚检测器中的标签分配被简化成了从网格点到目标框中心的点距。这种基于点的标签分配范式被称为「点分配」。无论是框分配还是点分配方法,都面临着多对一(many-to-one)分配的常见困境。对于一个真值框而言,它有不止一个正样本。检测性能容易受到分配过程中超参数的影响。更糟糕的是产生了冗余和近似重复的结果,导致非最大抑制(NMS)成为了必要的后处理。
最近,一对一(one-to-one)分配在稀疏候选和多阶段细化检测器中取得了成功,其中一个真值边界框只分配给一个正样本,其余皆为负样本。这类方法不需要 NMS 即可直接输出检测结果。检测器的检测准确率性能也非常好。但是,密集候选和单阶段细化检测器可能会更快和更简单。所以为何不为端到端单阶段检测器设计一种直接的一对一标签分类策略呢?
在本文中,
来自香港大学和字节跳动 AI 实验室的研究者发现:标签分配中样本与真值之间缺乏分类代价是 one-stage 检测器移除非最大抑制(NMS)并实现端到端的主要障碍
。现有的 one-stage 目标检测仅通过位置代价来分配标签,例如框 IoU、点距离。在缺少分类代价的情况,单独的位置代价将将导致高置信度得分在推理中产生冗余框,从而使 NMS 成为必要的后处理。
![]()
具体而言,为了设计一种
端到端 one-stage 目标检测器
,研究者提出了
最小代价分配(Minimum Cost Assignment)
。代价是样本与真值之间的分类代价和位置代价的总和。对于每个目标真值,仅将一个最小代价样本分配为正样本,其他都是负样本。为了评估该方法的有效性,研究者设计了一个非常简单的 one-stage 检测器 OneNet。
实验结果表明,在经过「最小代价分配」训练后,OneNet 避免了产生重复框,并实现了端到端目标检测。在 COCO 数据集上,OneNet 实现了 35.0 AP/80 FPS 和 37.7 AP/50 FPS,图像大小为 512 像素。
最小代价分配旨在解决端到端 one-stage 目标检测的标签分配,此前 one-stage 检测器的标签分配方法有框分配和点分配。该研究提出了全新的最小代价分配。
最小代价分配是一种直接的方法,对于每个真值,在所有样本中仅选择一个最小代价样本作为正样本,其余都是负样本。该方法不涉及手动制定的启发式规则或者复杂的二分图匹配。以下算法 1 给出了最小代价分配的说明性示例:交叉熵损失作为分类代价,L1 损失作为位置代价。
![]()
在密集探测器中,分类损失为焦点损失。继 [2, 42, 31] 之后,位置代价包含 L1 损失和泛化 IoU(GIoU)损失。最后,代价如下等式 3 所示:
![]()
其中 C_cls 是预测分类和真值类标签的焦点损失,C_L1 和 C_giou 分别是归一化中心坐标与预测框和真值框高度和宽度之间的 L1 损失和 GIoU 损失。λ_cls、λ_L1 和λ_giou 是每个分量的系数。
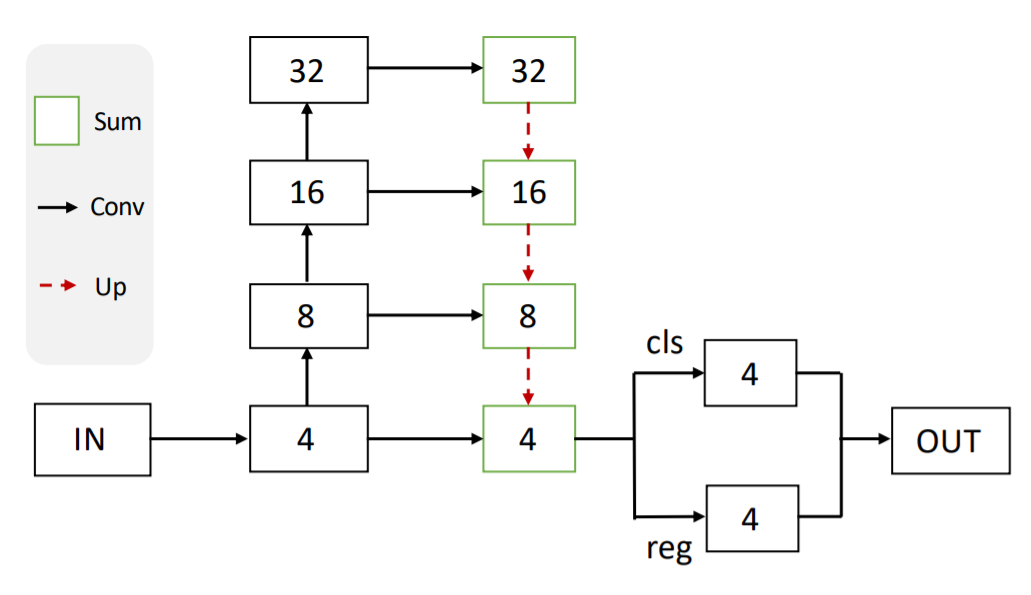
OneNet 是一种基础的全卷积 one-stage 检测器,没有任何后处理(如 NMS)。其流程图如下所示:
![]()
OneNet 的主干是一个先自下而上,然后自上而下的结构。自下而上的部分是 ResNet 架构[13],用于生成多尺度特征图。具有横向连接(FPN)的自上而下架构的作用是生成用于目标识别的最终特征图。输出特征的形态是 H/4xW/4xC,其中 H 和 W 分别是输入图像的高度和宽度。
头通过两个并行卷积层在特征图 H/4xW/4 的每个网格点上进行分类和定位。分类层预测 K 个目标类别在每个网格点上存在目标的概率。位置层可以预测从每个网格点到真值框四个边界的偏移量。
标签分配是最小代价分配。训练损失类似于匹配代价,包括焦点损失、L1 损失和 GIoU 损失。
最终输出是直接的前 k 个(例如 100 个)得分框,没有任何后处理流程(如 NMS 或最大池操作)。
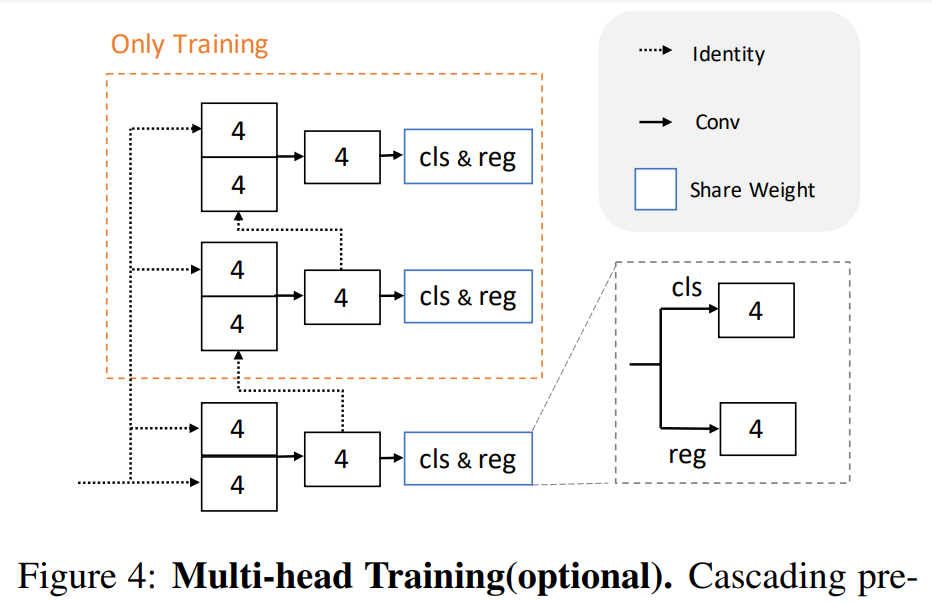
在实现过程中,研究者采用了一种可选择的多头训练策略,主要包括级联预测头和权重共享机制。其示意图如下所示:
![]()
级联预测头在训练过程中使用,其中分类卷积和回归卷积的参数分别在头中共享。推理过程中仅使用 first head,因此推理速度不会产生延迟。
该研究将 CenterNet [41] 和 OneNet 正样本进行了可视化,如下图 5 所示。两种方法最大的区别在于 CenterNet 遵循标签分配位置代价( location cost),而 OneNet 在分类代价和位置代价中遵循最小代价分配。
![]()
图 5:正样本的可视化。第 1 行是位置代价。第 2 行是分类代价与位置代价。正网格点由圆圈突出显示,画出来的边框为真值框。仅有位置代价分配的正样本是最接近真值框中心的网格点。添加分类代价,使得正样本成为更具识别区域的网格点。例如图 5 中斑马的头部。
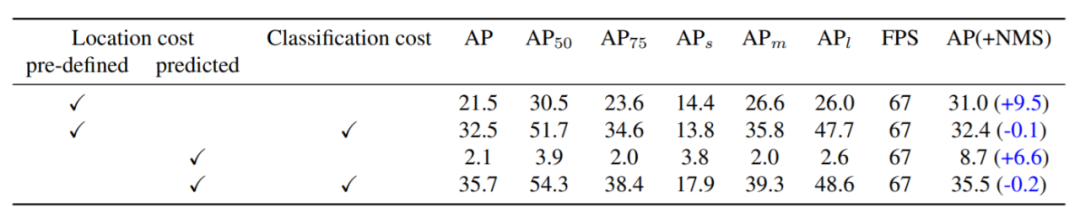
标签分配的研究。在下表 1 中,研究者进行了一系列的实验来研究标签分配对结果的影响。预定义位置代价是特征图中栅格点的固定位置与地面真值框中心位置之间的距离。被预测框的位置代价和分类损失参见第 3 节。分类代价是移除 NMS 的关键。
![]()
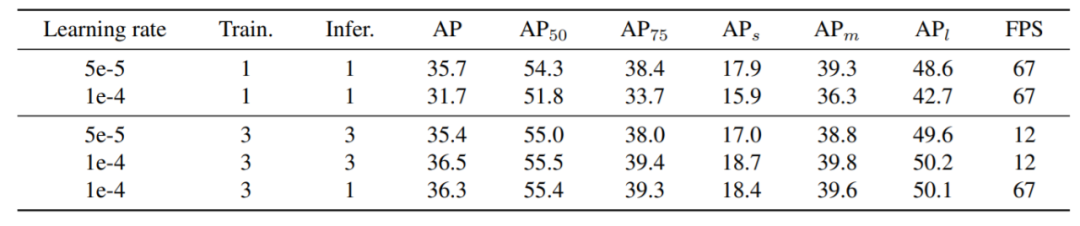
下表 2 为多头训练的控制变量实验。结果表明多头训练可以使用较大的学习率,得到较高的准确率。同时,多头训练与单头推理获得了较高的准确率,以及和基准相似的推理速度。
![]()
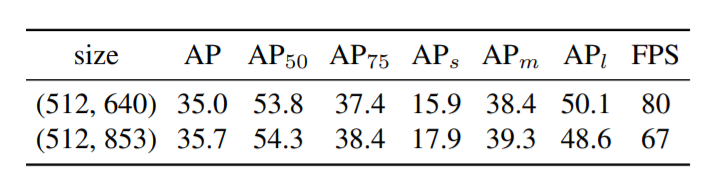
下表 3 研究了图像尺寸对结果的影响。由结果可知,较大的图像尺寸具有较高的准确率,但是,推理速度却慢了。
![]()
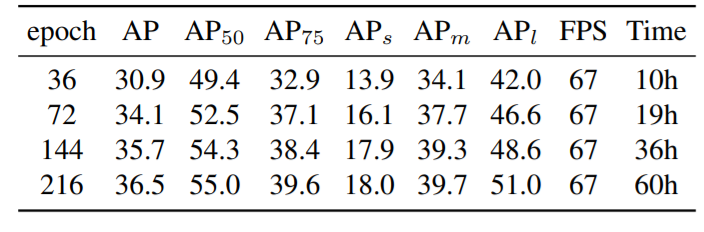
下表 4 为训练 epoch 对结果的影响。检测准确率的增长速度在训练 epoch 为 144 时开始下降。因此,该研究选择 epoch 为 144 作为基准配置。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com