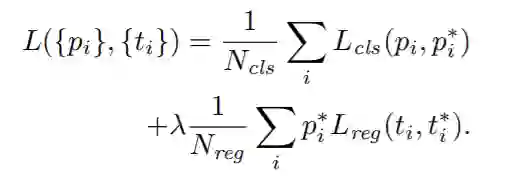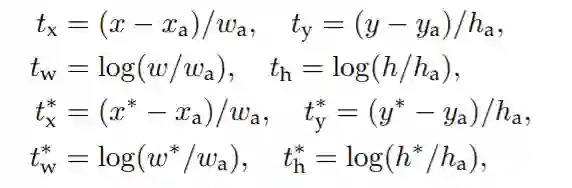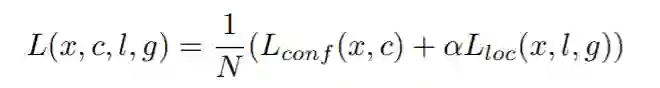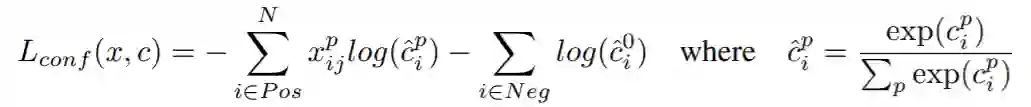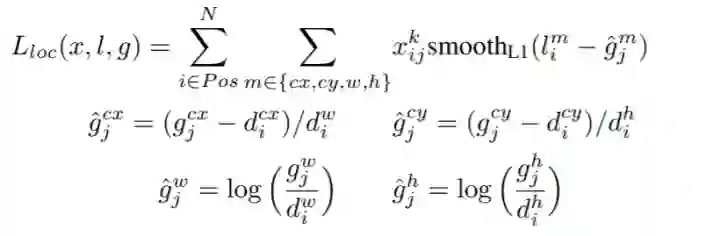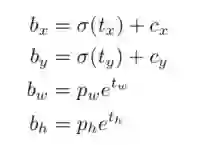前段时间,YOLOv4&v5大火,而很多人忽视了YOLOv5在anchor上的一些细节变化,因此,本文从Faster RCNN着手,逐步分析SSD、YOLOv4&v5的anchor三个任务和参数化坐标。
1 Faster RCNN
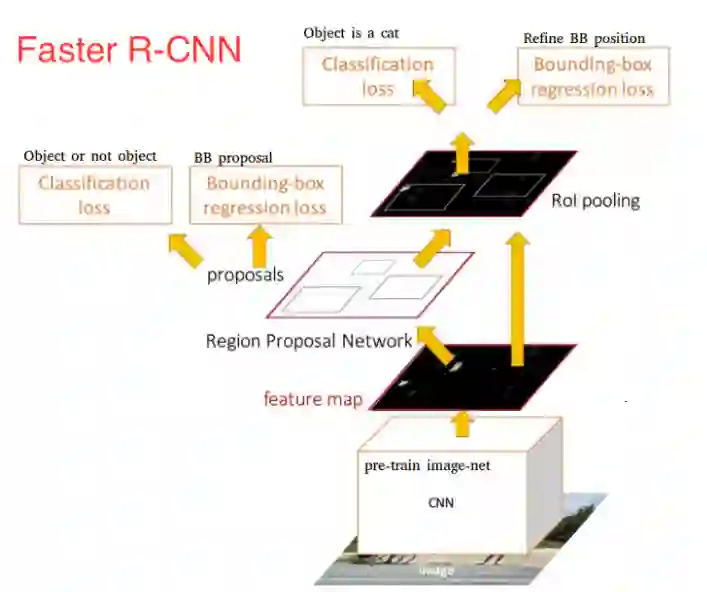
Faster RCNN可以看作是RPN(Regio Proposal Network) 和 Fast RCNN 的组合,由下图可以看到,输入图像经过RPN后输出proposals。RPN有三个任务,也可以说是与anchor相关三个任务:
分配任务:从众多anchors中,判断哪些anchor是正样本,哪些是负样本;
分类任务:对分配好的anchors使用交叉熵loss进行分类的训练;
回归任务:对于正样本的anchors使用mooth_l1 loss进行回归训练,以获得修正值。
![]()
Faster RCNN中的正样本有两种定义。第一,与ground truth bbox有最大的IoU的anchors作为正样本,第二,与ground truth bbox的IoU大于0.7的anchors作为正样本;而定义的负样本为与ground truth bbox的IoU小于0.3的样本。
![]()
Pi^*:标签。正样本时,
Pi^*=1;负样本时,
Pi^*=0;
ti: 预测的Bounding Box的参数化坐标(parameterized coordinates);
ti^*:Ground Truth的Bounding Box的参数化坐标,也就是学习的目标;
Nreg: Anchor Location的数量;
需要说明的是RPN输出的Classification并不是判定物体是具体的哪一类,而是输出一个二分类,只判断是否是object。
(1)由上述可知,回归的是参数化坐标,其计算方式如下:
![]()
其中,x,y,w,h是Bounding Box的中心坐标和宽高;而 则分别对应Predicated BBox、Anchor BBox和Ground Truth BBox;y,w,h也同理。
Anchor已经粗略地“框住了”输入图像中的目标,明显的一个问题是,框的不够准确。因为受限于Anchor的生成方式,Anchor的坐标永远都是固定的那几个。所以,如果我们预测相对于Anchor的offset,那么,就可以通过预测的offset调整锚框位置,从而得到更精准的bounding box。
首先,对于预测的bounding box的w和h可以通过anchor进行缩放,但有一个基本的要求,就是h和w都必须为正值,而网络最后一层的预测输出是没法保证正负的,所以最简单的方法就是对预测输出求exp,这样就保证了预测值恒为正。那么反过来,对预测目标就是求log。
其次,对cx和cy除以anchor的宽和高的处理是为了做尺度归一化。例如,大的box的绝对偏移量一般较大,而小的box的绝对偏移量一般较小,除以宽和高消除这种影响。即两个框大小不一,但相对值却一致。
Faster RCNN首次提出了anchor机制,后续大量流行的SSD、R-CNN、Fast RCNN、Faster RCNN、Mask RCNN和RetinaNet等等模型都是在建立在anchor基础上的,而yolov3、yolov5等模型尽管对anchor做了一些调整,但出发点不变,都是
从anchor的三个任务和参数化坐标出发,因此,Faster RCNN很重要。
到此,已经把 anchor 的三个任务和参数化坐标内容介绍完,接下来的再来分析SSD和YOLO中的 anchor。
2 SSD
Faster R-CNN先通过RPN网络得到候选框,然后再进行分类与回归,而SSD可以一步到位完成检测。相比,SSD有两大改变:
使用不同尺度的特征图来做检测,大尺度特征图用来检测小物体,而小尺度特征图用来检测大物体;
不同尺度和长宽比的先验框(Prior boxes,Default boxes,就是Faster RCNN中的anchors)
![]()
先是ground truth box找到与其IOU最大的那个先验框(prior boxes),这样保证每个GT都有其对应的先验框;
然后是对每个先验框找到与GT的IOU大于某个阈值(例如:0.5)的先验框;
![]()
N :是与 ground truth box 相匹配的 prior boxes 个数
尽管一个ground truth可以与多个先验框匹配,但正样本还是很少,为了保证正负样本尽量平衡,SSD采用了hard negative mining,就是对负样本进行抽样,采样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,并保证正负样本比例是1:3。
这样就可以使用交叉熵进行分类任务的训练了,公式如下:
![]()
与Faster R-CNN类似,对 prior boxes (d)的参数化坐标 进行回归:
![]()
其中,cx,cy,w,h分别Bounding Box的中心坐标和宽高,g是ground truth box,d是 prior box, 是Ground Truth的Bounding Box的参数化坐标,也就是学习的目标,而l是predicted box的参数化坐标。
SSD的anchor的三个任务和参数化坐标与Faster RCNN是一样的,但不能因此忽视SSD,SSD也是重要的里程碑。在我看来使用multi-scale feature maps实现的one stage检测器SSD的贡献是:能够在不怎么降低精度的情况下使得速度得到了很大的提升。
3 YOLO
在yolo v3&v4中,anchor匹配策略和SSD、Faster RCNN类似:保证每个gt bbox有一个唯一的anchor进行对应,匹配规则就是IOU最大,并且某个gt不能在三个预测层的某几层上同时进行匹配。不考虑一个gt bbox对应多个anchor的场合,也不考虑anchor是否设置合理。
而yolov5采用了跨网格匹配规则,增加正样本anchor数目的做法:
对于任何一个输出层,抛弃了基于max iou匹配的规则,而是直接采用shape规则匹配,也就是该bbox和当前层的anchor计算宽高比,如果宽高比例大于设定阈值,则说明该bbox和anchor匹配度不够,将该bbox过滤暂时丢掉,在该层预测中认为是背景;code如下:
r = t[None, :, 4:6] / anchors[:, None]
j = torch.max(r, 1. / r).max(2)[0] < model.hyp['anchor_t']
对于剩下的bbox,计算其落在哪个网格内,同时利用四舍五入规则,找出最近的两个网格,将这三个网格都认为是负责预测该bbox的,可以发现粗略估计正样本数相比前yolo系列,增加了三倍。code如下:
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
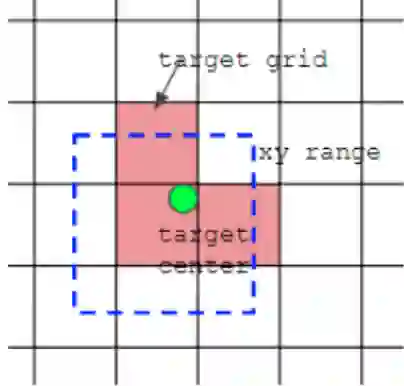
如下图所示,绿点表示该gt bbox中心,现在需要额外考虑其2个最近的邻域网格的anchor也作为该gt bbox的正样本,明显增加了正样本的数量。
![]()
参数化坐标box:xywh部分的参数化坐标,也就是box的loss
置信度conf:也就是obj的loss
类别cls,也就是class的loss
![]()
bx,by,bw,bz 分别是即边界框bbox相对于feature map的位置和宽高;
cx 和 cy 分别代表feature map中grid cell的左上角坐标,在yolo中每个grid cell在feature map中的宽和高均为1;
pw 和 py 分别代表Anchor映射到feature map中的的宽和高,anchor box原本设定是相对于416*416坐标系下的坐标,需要除以stride如32映射到feature map坐标系中;
tx,ty,tw,tzh这4个参数化坐标是网络学习的目标,其中tx,ty是预测的坐标偏移值,tw和th是尺度缩放,sigma代表sigmoid函数。
与faster rcnn和ssd中的参数化坐标不同的是x和y的回归方式,YOLO v3&v4使用了sigmoid函数进行偏移量的规则化,而faster和ssd中对x,y除以anchor的宽和高进行规则化。
对于yolov3使用的loss是smooth l1损失,而yolov4使用的是CIOU损失。
【YOLOv5】参数化坐标的方式和yolo v3&v4是不一样的,如下:
pxy = ps[:, :2].sigmoid() * 2. - 0.5
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
pbox = torch.cat((pxy, pwh), 1).to(device)
这样,pxy的取值范围是[-0.5,1.5],pwh的取值范围是(0,4*anchors[i]],这是因为采用了跨网格匹配规则,要跨网格预测了。
lobj 表示该anchor中是否含有物体的概率,默认使用BCEWithLogitsLoss。
lcls 表示该anchor属于哪一类的概率,默认使用BCEWithLogitsLoss。
例如,对于coco数据集上训练的YOLO的每个anchor的维度都是85,前5个属性是(Cx,Cy,w,h,confidence),confidence对应lobj,后80个维度对应lcls。
github上有很多版本的yolov4,初步看了以下两个repo:
https://github.com/WongKinYiu/PyTorch_YOLOv4
熟悉yolov5的同学会对u版不会感到陌生,该版的yolov4其实只是用了yolov4的backbone,参数化坐标及loss等等都与yolov5的一样。
https://github.com/Tianxiaomo/pytorch-YOLOv4
从参数化坐标及loss来看,和yolov3一致,但还是少了挺多,如label smoothing, Self-Adversarial Training,DIOU NMS等等。
虽然都不是严格的 yolov4,但也不妨碍我们使用(本人不想肝DarkNet),个人认为u版的更好些,因为自定义网络会方便简介很多。
本文回顾 Faster RCNN 和 SSD 中的 Anchor 的三个任务和参数化坐标,然后比较了YOLOv3&v4&v5的 Anchor及其loss,最后简评了github上两个YOLOv4的repo,希望对大家有所帮助。
推荐阅读
ACCV 2020国际细粒度网络图像识别竞赛正式开赛!
![]()
添加极市小助手微信(ID : cvmart2),备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳),即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群:每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~
![]()