阿里巴巴提出 DR Loss:解决目标检测的样本不平衡问题
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:张凯
https://zhuanlan.zhihu.com/p/75896297
本文已由作者授权,未经允许,不得二次转载
背景
《DR Loss: Improving Object Detection by Distributional Ranking》作者来自于阿里巴巴。该论文主要是修改损失函数来处理样本不平衡问题的,之前最出名的应该是2017 ICCV最佳学生论文RetinaNet中的focal loss。2019 AAAI的GHM,2019 CVPR的AP loss也分别讨论了样本不平衡的问题。
因为这类方法只会影响训练,不会影响推理速度,对现有产品影响不会很大,所以还是很值得尝试的。

arXiv:https://arxiv.org/abs/1907.10156
代码未开源,基于detectron开发。
一、研究动机
样本不平衡问题是one-stage目标检测算法中一直存在的问题,负样本(背景)的数目远大于正样本,简单样本远大于难例,从而导致训练无法收敛到很好的解。2017 ICCV RetinaNet是通过focal loss来处理该问题,主要是抑制大量简单的负样本,给难例更大的权重。而本篇论文则提出了另外一种解决思路(2019 CVPR AP loss 也是这个思路):将分类问题转换为排序问题,从而避免了正负样本不平衡的问题。同时针对排序,提出了排序的损失函数DR loss,并给出了可求导的解。最终性能较RetinaNet有近2个点的提升,提升还是比较明显的。
二、具体方法
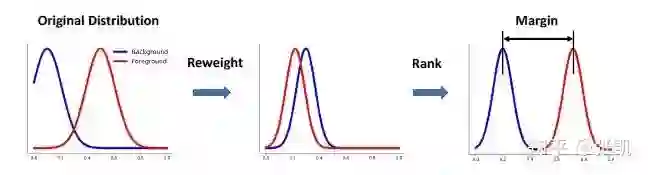
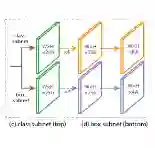
整体思路的话,如图所示,主要是将正样本的分布和负样本的分布尽可能区别开,具体结合公式来讲下,比较简单。
首先是对原有分类问题的定义
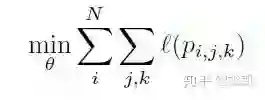
对于所有的样本,寻找一个分类器 
进一步地,把正负样本拆开写
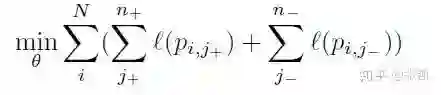
把上述问题转换为排序问题:
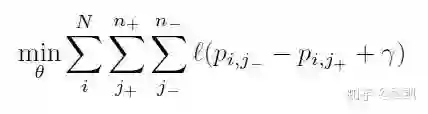
上述公式的含义是,对于所有样本对(一个正样本和一个负样本构成一对)的损失最小,每一个样本对排序都要正确,r 代表margin。
进一步,对于每幅图像可以写成
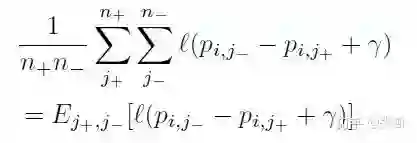
如果按照上述公式来做,会存在两个问题,一是负样本之间本身就是不平衡的,二是样本对太多了,具体是 n+ x n- 。
所以一种解决方案是改求正负样本分布的min和max:
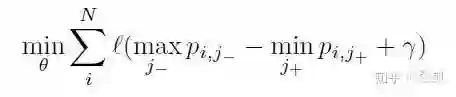
成功地将 量级转换为了1。但上述同样存在一个问题,就是该公式对outliers太敏感了,训练肯定不稳定。
为了解决上述问题,本文的思路是选取正负样本中最具代表性的样本来参与排序,具体地,作者定义了正样本分布和负样本分布的分数:
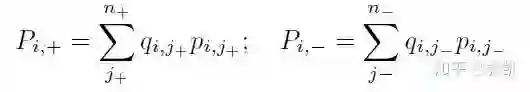
其中q代表的是分布,并有
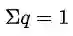
可以看到,如果q服从均匀分布,实际上求得就是正负样本的期望。(当然这样肯定不行,因为负样本中难易样本是不均衡的)
所以作者希望求解这个分布,使得分布的分数最小化或者最大化
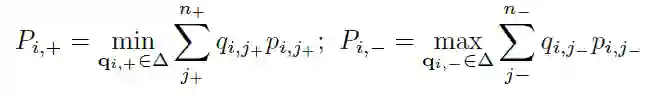
如果分布没有约束的话,那么产生的解一定是最大值对应的q为1,其余值为0,这样就又退化了之前直接求max和min了。
所以作者在此处加入了对分布的约束:
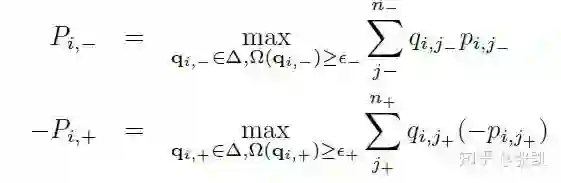
进一步,转换为以下次优问题:
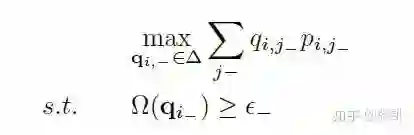
利用对偶法转换:
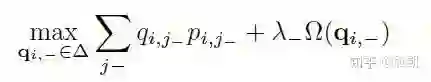
再用KKT条件,可以求得:
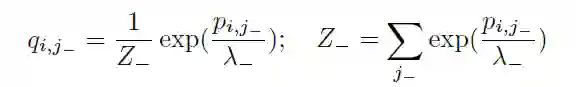
最后,代入公式,求得分布的分数
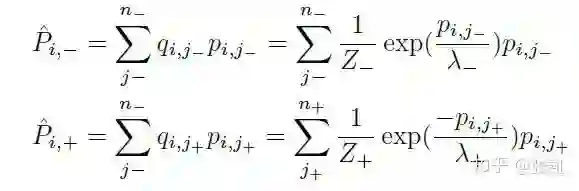
最终为了平滑整个曲线,作者加入了hinge loss:
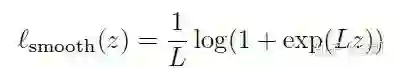
最终分类的loss为:
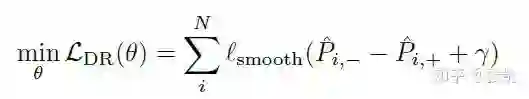
并且为了确保正样本和负样本能够分开,需要
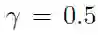
即可保证:
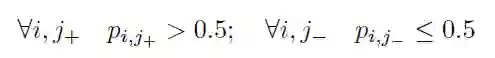
对于回归loss,作者也做了改进:
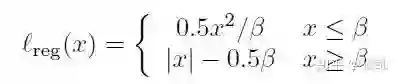
主要是在训练中对其进行衰减:
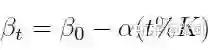
目的是为了减少L1和L2之间的gap。
三、实验结果
作者首先做了一些消融实验,例如对于hingle loss中的L:
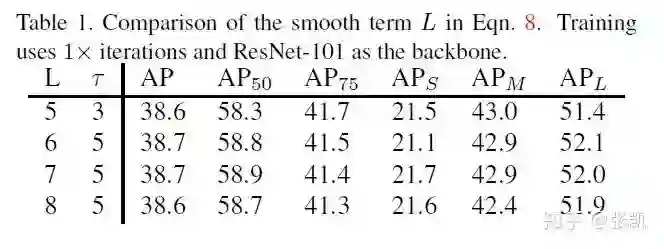
L对最后的结果影响不大。
其他关于正则项h等消融实验详情见论文。
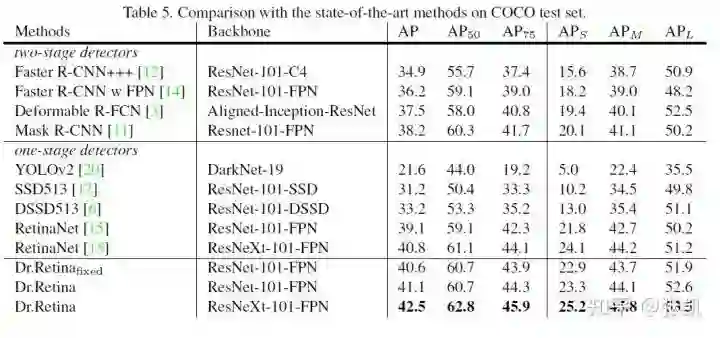
最终结果的性能提升还是非常明显的,比baseline高了2个点左右。
四、总结分析
优点:借鉴了排序loss引入到目标检测中,并且给出了可行的优化过程,性能提升也很明显,对于现有的检测框架,只需要修改损失函数,后续会考虑尝试下。
缺点:超参还是蛮多的,虽然在COCO上似乎影响不大,换个数据集和检测框架(例如anchor-free的)不知道是不是很稳定。之前在FCOS上尝试了GHM的方法,直接用默认参数可以掉10个点,不过可以通过调参调回来。
重磅!CVer-目标检测交流群成立啦
扫码添加CVer助手,可申请加入CVer-目标检测学术交流群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!