An Analysis of Scale Invariance in Object Detection - SNIP 论文笔记
CVPR 2018 论文 论文链接 https://arxiv.org/abs/1711.08189
1.摘要
本文分析了目标检测领域中处理目标尺寸变化的常用方法,通过实验对这些方法进行比较。作者通过实验测试了图像上采样对检测小目标的影响。基于这些分析和测试,作者提出了一种训练方法--图像金字塔尺度归一化(Scale Normalization for Image Pyramids, SNIP)。该方法使用多尺度图像训练检测网络,并根据目标大小选择性的反向传播梯度。使用SNIP方法训练的检测网络,在COCO数据集上取得了很好的效果。
SNIP优点:
使用所有目标进行训练,学习到大量的外观变化
减小分类模型和检测模型尺度空间的domain-shift
2.作者的动机
在ImageNet 分类任务中,使用CNN的方法已经将top-5错误率降至2%。但是在COCO目标检测任务上mAP50仅有62%。为什么目标检测比图像分类更困难呢。分析下图中ImageNet和COCO数据集中目标尺度的分布,可以看出,COCO数据集中目标尺度分布不均匀,绝大多数都是小目标。
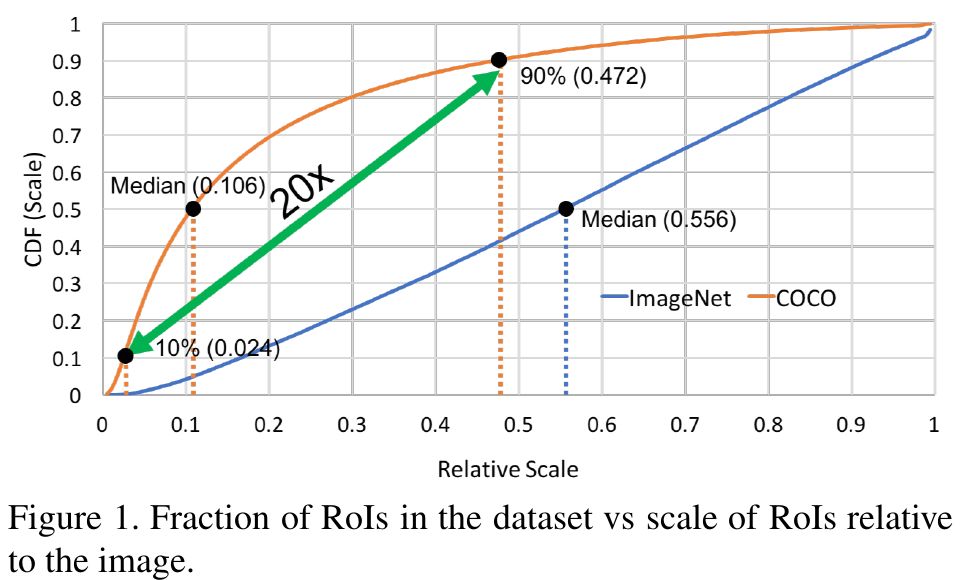
因此,作者总结出目标检测存在的难点:
小目标检测困难
目标尺寸变化很大,用CNN学习尺度不变的特征具有挑战性
ImageNet分类数据集和COCO数据集尺度差别很大,对分类任务的模型进行微调,并应用到检测任务时,存在很大的domain-shift
为了解决小目标识别的问题,人们提出了一些多尺度目标检测方法:
使用空洞卷积(dilated/atrous convolution)。减小stride的,增加feature map大小,但不会减小感受野的大小。这样做不影响检测大目标的性能
训练时将图像放大1.5到2倍,预测时,放大4倍
使用CNN中不同层的特征分别进行预测,浅层负责检测小目标,深层负责检测大目标
深浅层特征结合进行预测,使浅层特征结合深层的语义特征,如FPN。但当目标尺寸较小时,如25x25,特征金字塔生成的高层语义特征也可能对检测小目标帮助不大
3.多尺度图像对分类网络的影响
作者分析训练和测试图像尺寸对预训练的分类网络的影响。作者分析了如下三组网络:

实验结果如下:

CNN-B使用224x244高分辨率图像训练。测试时,先将原图缩放48x48...128x128等尺寸,然后将图像上采样到224x224进行测试。作者发现,随着训练预测时图像尺度差异的增加,网络的分类效果变差。
因此作者提出,使用网络没有训练过的分辨率的图像进行测试,达不到很好的效果,至少在分类任务中是这样的。
基于上述结果,作者提出了第二组实验。
CNN-S使用低分辨率图像训练和测试(使用CIFAR10数据集,图像大小为32x32)。将图像缩放到48x48和96x96训练两个网络,测试时用对应大小的图像进行测试。使用相同分辨率图像进行测试时,发现结果比用CNN-B效果好很多。需要注意到,由于图像尺寸和原先的224比小了很多,因此对原来网络的结构进行了调整,如减小stride等。
因此作者提出,一个可能的检测小目标的方法是,修改网络结构,如减小strdie,使用低分辨率的图像进行预训练。测试时,用于检测低分辨率的小目标。
接下来,作者又提出一种方法。
CNN-B-FT用上采样到244的低分辨率的图像微调CNN-B,测试时,用由低分辨率图像上采样后的图像进行测试(同CNN-B)。作者发现,这样做效果比CNN-S还要好。以作者的经验来说,他认为由高清图像训练的filter,也可以很好的识别低分辨率图像。
因此,相比于减小stride(CNN-S),更好的方法是对低清图像进行上采样,然后微调由高清图像训练的网络。
对上述实验进行总结,作者得出,训练和测试时输入图像大小的差异,可能导致网络效果变差。如果在训练目标检测网络时,proposals的大小与分类网络预训练时使用的图像大小接近,就有可能减小domain-shift,达到很好的效果。
4.多尺度图像对检测网络的影响
作者使用800x1200和1400x2000两种分辨率,训练了两个检测网络;使用1400进行小目标检测(COCO数据集中,目标分辨率小于32x32的)。
结果如下:
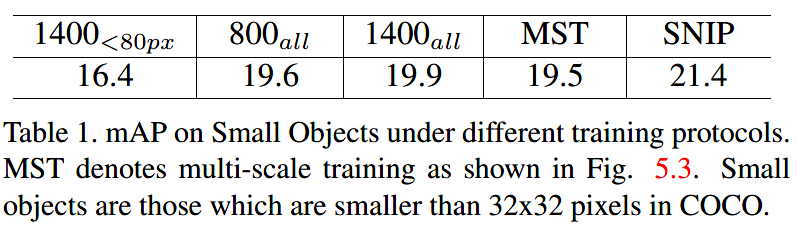
实验表明,1400表现更好,因为训练测试图像的分辨率相同。然而性能提升的很有限。作者发现,增加图像分辨率后,中大目标的分辨率也跟着增加了,以至于训练时难以正确分类,因此导致整个分类器性能下降。
因此,作者又设计了一组实验。使用1400分辨率进行训练,同时忽略原图中的中大目标(大于80像素)。然而,结果更差了。作者分析,这样做忽略了很多目标的外观变化(中大目标约占30%),与忽略大尺度的影响相比,这样做更影响性能。
作者又尝试训练具有尺度不变特性的检测器。随机采样图像,用不同分辨率的图像进行训练(Multi-Scale Training, MST)。然而效果也不太好,原因是随机采样,会出现极大极小的样本,影响训练效果。
因此作者得出结论:图像缩放后,使用尺度接近的目标来训练分类器很重要。
5.SNIP 图像金字塔尺度归一化
作者提出,在训练时,既希望训练数据有尽可能多的外观变化,又想将物体的尺度限制在一个合理的范围内。因此作者提出了SNIP训练方法,使用MST(多尺度图像训练)方法时,只训练目标尺度在特定范围(与预训练的图像尺寸接近)的图像,在反向传播时,忽略其他过大过小的图像。
网络的训练和测试过程如下:
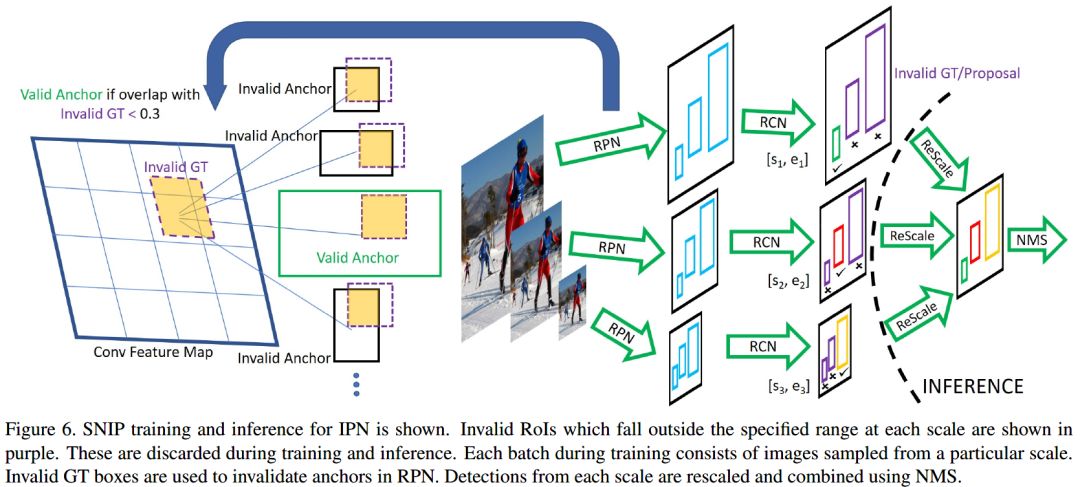
训练和测试时,忽略特定目标的规则如下: two-stage的检测器,包括RPN提取proposals,对proposals分类和bbox回归两个阶段。 在分类阶段,训练时,不选择那些proposals和GT boxes在特定大小范围外的。 RPN阶段,和无效GT boxes(大小不在范围内)的IoU大于0.3的anchor认为是无效的,忽略这些anchor。 在测试阶段,使用多个分辨率的图像进行检测;在分类阶段,去除那些回归后bboxes大小不在特定范围的检测结果。然后使用Soft-NMS将不同分辨率图像的检测结果合并。
6.训练细节
对于预训练的分类器,通常训练图像大小为224x224。为了尽可能减少domain-shift,训练检测器时,我们期望proposals的大小与预训练时差不多。因此作者设定了如下的有效范围,注意的是COCO数据集中的图像大多在480x640左右。
左为训练图像分辨率,右为原图中有效尺寸的范围,使用了三种尺度进行训练:
1400x2000,[0,80]
800x1200,[40,160]
480x800,[120,∞]
假设原图短边尺寸为480,经过简单计算可知,有效尺寸映射到训练图像的分辨率上,边长为200左右,与预训练图像尺寸接近。
7.实验
SNIP对分类阶段的提升
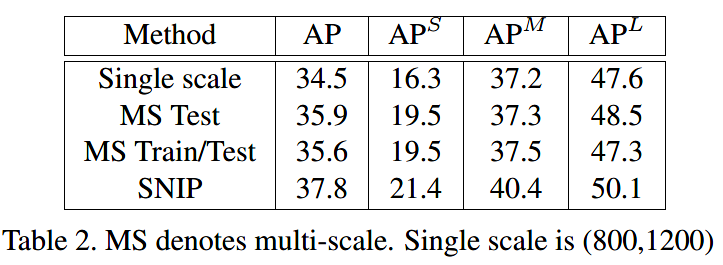
Baseline是使用单尺度训练的RFCN MS Test是使用多尺度图像进行测试 MS Train/Test是使用多尺度训练测试,即MST
SNIP对RPN的提升
主要考察召回率