CVPR 2020 Oral | 旷视研究院提出双边分支网络BBN:攻坚长尾分布的现实世界任务

IEEE 国际计算机视觉与模式识别会议 CVPR 2020 (IEEE Conference on Computer Vision and Pattern Recognition) 将于 6 月 14-19 日在美国西雅图举行。近日,大会官方论文结果公布,旷视研究院 17 篇论文被收录,研究领域涵盖物体检测与行人再识别(尤其是遮挡场景)、人脸识别、文字检测与识别、实时视频感知与推理、小样本学习、迁移学习、3D 感知、GAN 与图像生成、计算机图形学、语义分割、细粒度图像等众多领域,取得多项领先的技术研究成果,这与即将开源的旷视 AI 平台 Brain++ 密不可分。
本文是旷视 CVPR 2020 论文系列解读第 5 篇,是 CVPR 2020 Oral 展示论文之一,它揭示了再平衡方法解决长尾问题的本质及不足:虽然增强了分类器性能,却在一定程度上损害了模型的表征能力。 针对其不足,本文提出了一种针对长尾问题的新型网络框架——双边分支网络(BBN),以兼顾表征学习和分类器学习。通过该方法,旷视研究院在细粒度识别领域权威赛事 FGVC 2019 中,获得 iNaturalist Challenge 赛道的世界冠军。该网络框架的代码已开源。

目录
-
导语 -
简介 -
论点证明 -
方法 -
实验 -
结论 -
参考文献 -
往期解读

随着深度卷积神经网络(CNN)研究的推进,图像分类的性能表现已经取得了惊人的进步,这一成功与高质量的大规模可用数据集密不可分,比如 ImageNet ILSVRC 2012、MS COCO 和 Places 数据集。
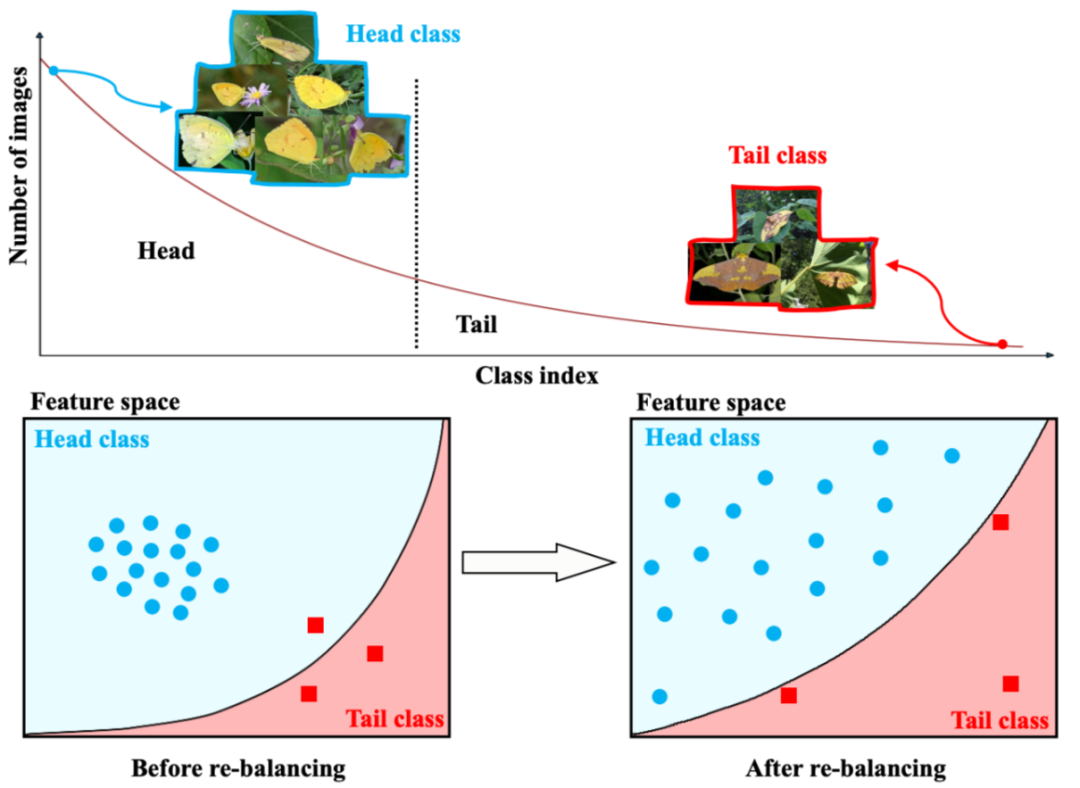
这些视觉识别数据集的类别标签分布是大致均匀的,相对而言,真实世界的数据集却总是存在偏重情况,呈现出长尾分布模式,即少量类别(头部类别)具有大量数据,而大部分类别(尾部类别)仅有少量样本,如图 1 所示。
另外,计算机视觉社区在近些年中构建出了越来越多反映真实难题的长尾数据集,如 iNaturalist、LVIS、RPC。
 ▲ 图1. 真实世界的大规模数据集往往会展现出长尾分布现象
▲ 图1. 真实世界的大规模数据集往往会展现出长尾分布现象
长尾分布这种极端不平衡会导致分类训练难以得到很好的效果,尤其是对于长尾类别而言。类别再平衡策略可让模型在长尾问题上的准确度表现更好。
本文揭示出,这些策略的机制是显著提升分类器学习,但同时又会在一定程度上出人意料地损害已学的深度特征的表征能力。
如图 1 所示,经过再平衡之后,决策边界(黑色实弧线)往往能更准确地分类尾部数据(红色方块)。但是,每个类别的类内分布会变得更加松散。在过去的研究中,处理长尾问题的显著且有效的方法是类别再平衡,它可以缓解训练数据的极端不平衡问题。
一般来说,类别再平衡方法有两类:1)再采样方法;2)代价敏感再加权方法。这些方法可对 mini-batch 中的样本进行再采样或对这些样本的损失进行重新加权,以期望能够和测试分布维持一致,从而实现对网络训练的调整。
因此,类别再平衡可有效地直接影响深度网络的分类器权重更新,即促进分类器的学习。正是因为这个原因,再平衡方法可以在长尾数据上取得令人满意的识别准确度。

简介
在本文中,旷视研究院首先通过验证实验,对前述论点进行了证明。具体来说,为了解析再平衡策略的工作方式,把深度网络的训练过程分为两个阶段:1)表征学习;2)分类器学习。
表征学习阶段,旷视研究院采用的传统的训练方法(交叉熵损失)、再加权和再采样这三种学习方式来习得各自对应的表征。
另一方面,通过固定分类器的学习方式,简单的交叉熵损失相比再平衡策略反而可以取得更低的错误率,这说明再平衡策略在一定程度上损害了表征学习。
从该角度出发,旷视研究院提出了一种统一的双边分支网络(BBN),可以同时兼顾表征学习和分类器学习,大幅提升了长尾问题的识别性能。
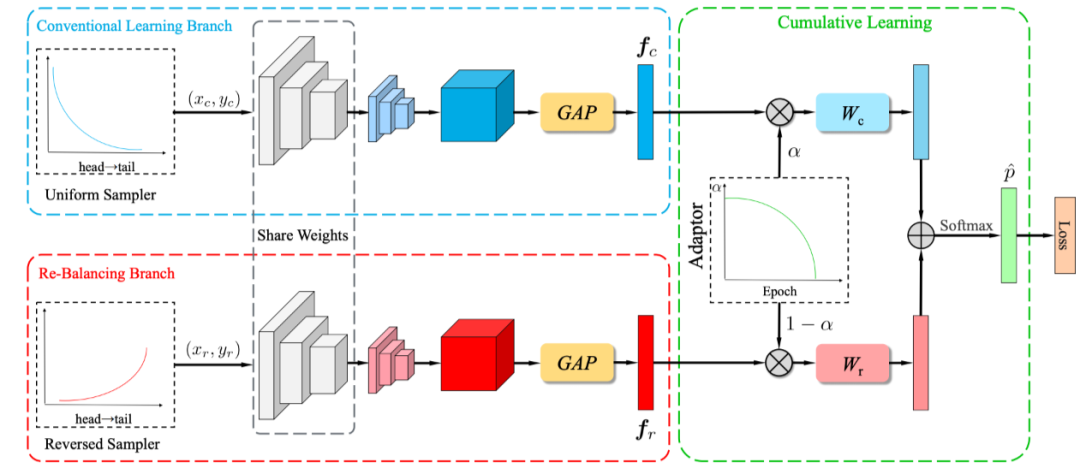
如图 3 所示,BBN 模型由两个分支构成,即常规学习分支(Conventional Learning Branch)和再平衡分支(Re-Balancing Branch)。总体而言,BBN 的每个分支各自执行其表征学习和分类器学习任务。
顾名思义,常规学习分支为原始数据分布配备了典型的均匀采样器(Uniform Sampler),可用于为识别任务学习通用的表征;再平衡分支则耦合了一个逆向的采样器(Reversed Sampler),其目标是建模尾部数据。
接着,再通过累积学习(Cumulative Learning)将这些双边分支的预测输出聚合起来。累积学习使用了一个自适应权衡参数 α,它通过「适应器(Adaptor)」根据当前训练 epoch 的数量自动生成,可以调节整个 BBN首先从原始分布学习通用的特征,然后再逐渐关注尾部数据。

论点证明
为探究再平衡策略对表征学习和分类器学习的影响,旷视研究院设计了一个两阶段的验证实验,把深度学习模型解耦为了表征提取器和分类器。
具体来说,第一阶段使用普通的训练方法(即交叉熵)或再平衡方法(即再加权/再采样)作为学习方法训练一个分类网络;然后,获取对应于这些学习方法的不同类型的表征提取器。
在第二阶段,固定在前一阶段学习到的表征提取器的参数,再使用前述的三种学习方法从头开始重新训练分类器。
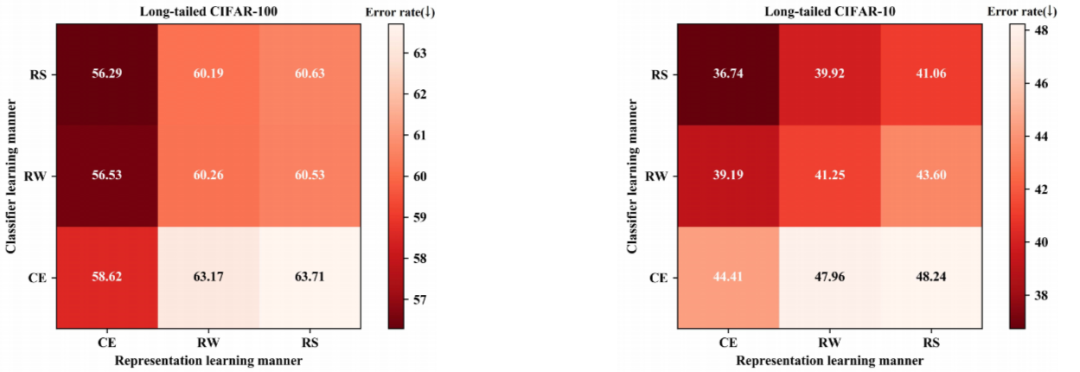
如图 2 所示,旷视研究院在 CIFAR-100-IR50 数据集(这是不平衡比为 50 的长尾 CIFAR-100)上通过对照实验对上述论点进行了验证。可以看到,在每个数据集上,基于不同的排列组合可得到 9 组结果。基于此,可得到两个方面的观察结果:
-
分类器:可以发现,当应用同样的表征学习方法时(比较竖直方向上三个单元格的错误率),RW/RS 的分类错误率总是低于 CE,这是因为它们的再平衡操作会对分类器权重的更新过程进行调整,以与测试分布相匹配; -
表征:当应用同样的分类器学习方法时(比较水平方向上三个单元格的错误率),可以惊讶地发现 CE 的错误率总是低于 RW/RS。这说明使用 CE 进行训练可以获得更好的表征,RW/RS 在一定程度上损害了习得的深度特征的表征能力。
此外,如图 2 左图所示,通过在表征学习上应用 CE 和在分类学习上应用 RS,在 CIFAR-100-IR50 的验证集上得到的错误率最低。

方法
 ▲ 图3. BBN 框架示意图
▲ 图3. BBN 框架示意图
在这之后是旷视研究院专门设计的累积学习策略,可在训练阶段在两个分支之间逐渐切换学习的「注意力」。
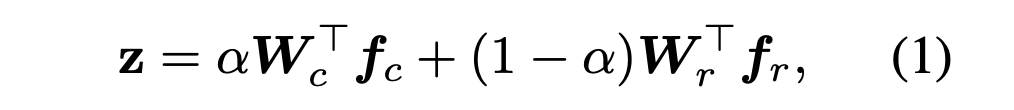
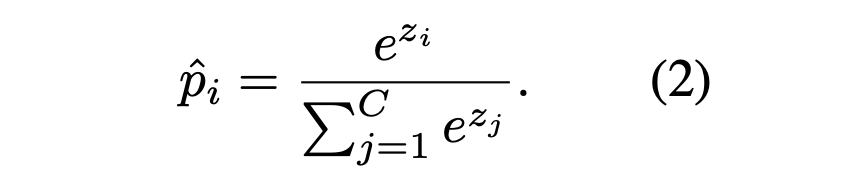
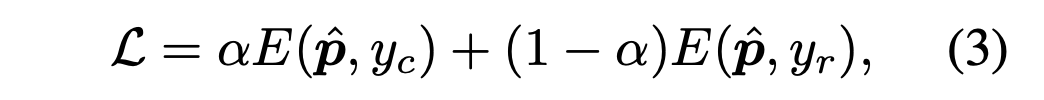

实验
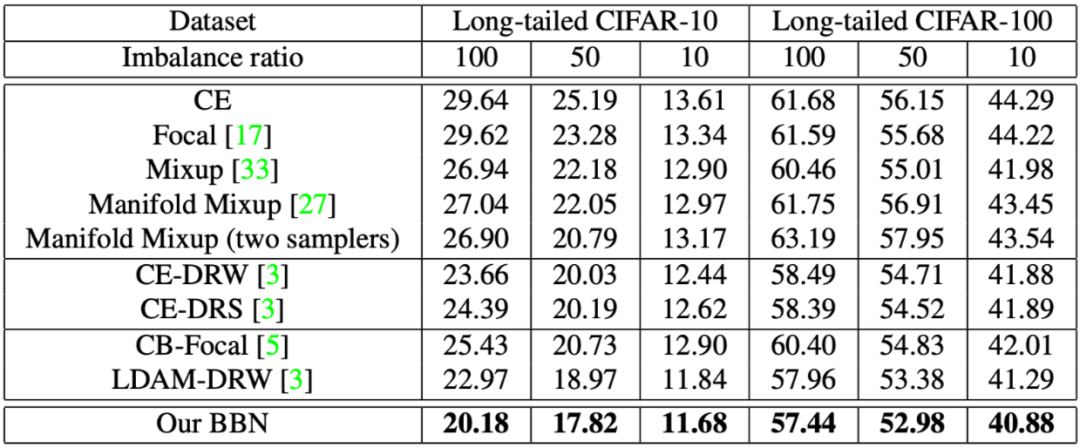
旷视研究院在不平衡比分别为 10、50、100 的三个长尾 CIFAR 数据集上进行了广泛的实验,结果如下所示:

结论
本文首先探索了类别再平衡策略对深度网络的表征学习和分类器学习产生的影响,并揭示出这些策略虽然可以显著促进分类器学习,但也会对表征学习产生一定的负面影响。
基于此,本文提出了一种带有累积学习策略的双分支网络 BBN,可以同时考虑到表征学习与分类器学习,大幅提升长尾识别任务的性能。
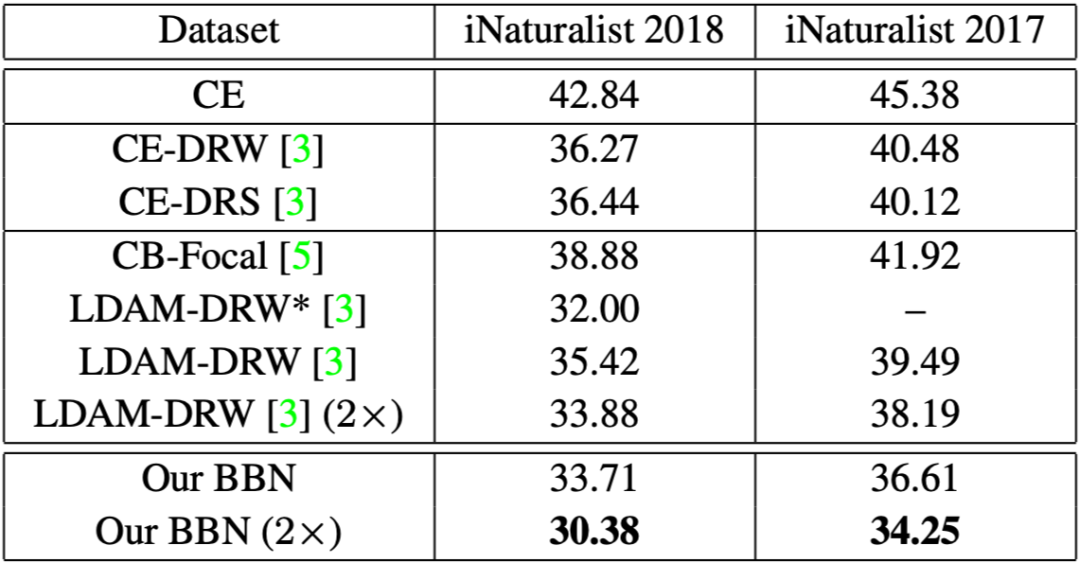
经过广泛的实验验证,旷视研究院证明 BBN 能在长尾基准数据集上取得最佳的结果,其中包括大规模的 iNaturalist 数据集。未来,旷视研究院还将继续探索 BBN 模型在长尾检测问题上的应用,并希望通过 BBN 开源项目促进社区在长尾问题方面的探索和研究。


往期解读
-
CVPR 2020 | 旷视研究院提出PVN3D:基于3D关键点投票网络的单目6DoF位姿估计算法 -
CVPR 2020 | 旷视研究院提出SAT:优化解决半监督视频物体分割问题 -
CVPR 2020|旷视研究院提出新方法,优化解决遮挡行人重识别问题 -
CVPR 2020 Oral|旷视研究院提出Circle Loss,革新深度特征学习范式
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





