CVPR 2019 | 旷视研究院提出Re-ID新方法VPM,优化局部成像下行人再识别

全球计算机视觉三大顶级会议之一 CVPR 2019 将于当地时间 6 月 16-20 日在美国洛杉矶举办。届时,旷视研究院将带领团队远赴盛会,助力计算机视觉技术的交流与落地。在此之前,旷视每周会介绍一篇被 CVPR 2019 接收的论文,本文是第 13 篇。围绕行人再识别,并针对实际情况下行人经常被遮挡、仅能被部分成像这一困难,旷视研究院提出一种可见部件感知模型 VPM,其可通过自监督学习感知哪些部件可见或不可见,并在比较两幅图像时,聚焦在二者共同可见的部件上,显著提高部分成像下的行人再识别准确率。

论文名称:Perceive Where to Focus: Learning Visibility-aware Part-level Features for Partial Person Re-identification
论文链接:https://arxiv.org/abs/1904.00537
导语
简介
方法
VPM 结构
部件定位器
部件特征提取器
使用 VPM
训练 VPM
自监督
实验
大规模数据集实验
对比 SOTA
结论
参考文献
往期解读
导语
近年来,行人再识别研究取得迅速进展,2018 年下,在公开数据集 Market-1501 上,SOTA 方法的一选准确率已达到 95% 甚至更高水平;与此同时,CV 产业界也开始发力,推动其场景落地。但是在实际 re-ID 系统中,一些极具挑战性的问题正等待克服,部分成像下的行人再识别(partial re-ID)即是其中之一。
在 partial re-ID 场景下,图像可能只包含行人的部分可见信息,例如腿部被遮挡、只有上半身被成像。此时,未经针对性设计的行人再识别方法通常会遭遇性能“滑铁卢”,无法再准确识别行人。
为此,旷视研究院联合清华大学,提出一种可见性感知局部模型 VPM(Visibility-aware Part Model),通过自监督学习感知哪些部件可见/不可见(这种能力称之为“可见部件感知能力”),并在比较两幅图像时,聚焦在共同可见的部件上,显著提高部分成像下的行人再识别准确率。
对于 partial re-ID,VPM 具有两方面的优势:1)VPM 引入了部件特征,因此,与在传统全身的行人再识别(holistic re-ID)问题中一样,部件特征受益于细粒度信息,获得更好的鉴别能力;2)由于具备可见部件感知能力,VPM 可估计出两张图像之间的共享区域,并在评估其相似性时聚焦在共享区域,这种做法符合人脑识别行人的思维习惯。
实验结果证明,VPM 可显著改善特征表达,在 re-ID、尤其是 partial re-ID 问题上取得了优异性能。
简介
行人再识别需要在行人图像库中,检索出特定身份行人的所有图像。尽管近年来进展迅速,但在实际应用之前,仍然遇到了一系列严峻挑战,其中之一是局部成像问题。在实际的 re-ID 系统中,一个行人可能被其他物体部分遮挡,或是正在走出摄像机视场,因此相机经常无法对行人进行全身成像,产生所谓的局部成像下的行人再识别问题——partial re-ID。
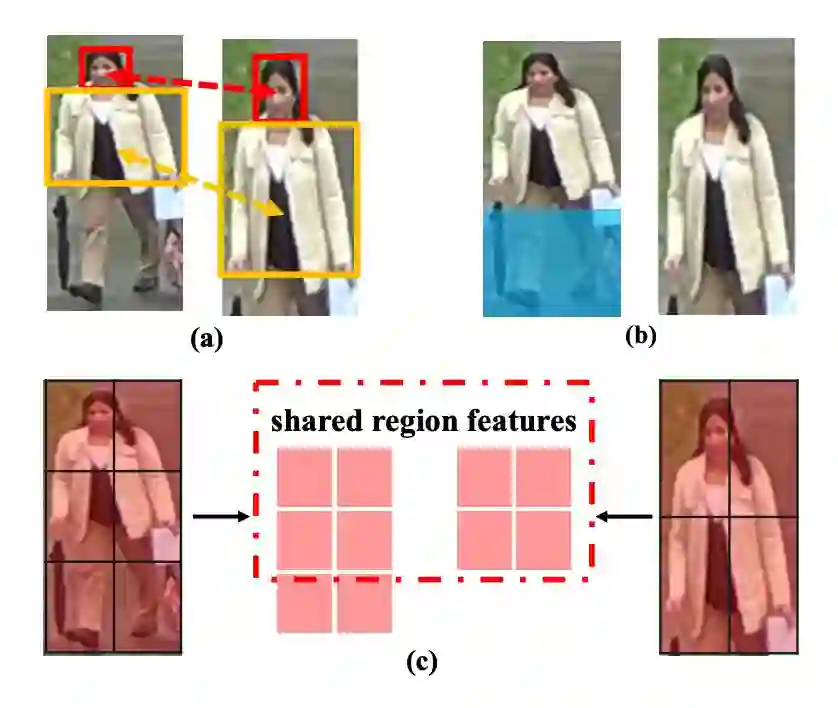
▲ 图1:局部再识别的两项挑战 (a)、(b) 以及旷视研究院提出的VPM方法 (c)
直觉上来讲,局部成像必然加大行人检索难度;若仔细分析可以发现,相较于整体的行人再识别,局部成像又额外引入了两项特有挑战:
1. 局部成像加剧了查询(query)图像与库(gallery)图像之间的空间错位。全局 re-ID 场景下,空间错位主要源自行人姿态变化和观察视角的变换;然而在局部成像条件下,即便两个行人姿态相同,从同一个视角观察,两张图像间依然存在严重的空间错位(如图1(a))。
2. 如果生硬地比较全身图像和半身图像,二者之间不共享的区域(如图 1(b)中蓝色区域)不仅不再提供有益的线索,反而引入了额外的干扰噪声。这种额外噪声在对比两幅缺失程度不同的图像时也会发生。
针对上述挑战,旷视研究院提出可见部件感知模型 VPM。给定一幅行人图像,VPM 能够感知哪些区域缺失、哪些区域可见,通过聚焦于两幅图共享的区域,VPM 避免或是说缓解了上述与局部重识别相关的两个特殊困难(如图1(c))。
值得强调的是,VPM 不依赖于头部、躯干等语义部件,而是依赖于预先定义的方形区域作为部件。这种做法被 PCB 推广,其性能在全身行人在识别问题上已超过语义部件特征学习。本文把这种思路进一步延续:部件特征学习并不需要依赖人类习惯的语义部件,采用预先定义的方形部件高效且准确率可能更高。VPM 正是由于采用这种做法,不再需要代价高昂的语义部件学习,仅仅通过自动监督学习,即可获得最关键的可见部件感知能力。
具体而言,旷视研究员首先在完整出现了人体的图像上定义一系列区域。在训练过程中,给定局部行人图像,VPM 可以学习去定位所有在卷积特征图上的预定义区域。之后,VPM 会感知可见的区域,并学习区域层级的特征。在测试过程中,给定两张待比较的图像,VPM 首先会计算其共享区域之间的本地距离,然后得出两张图像的总体距离。
方法
VPM 结构
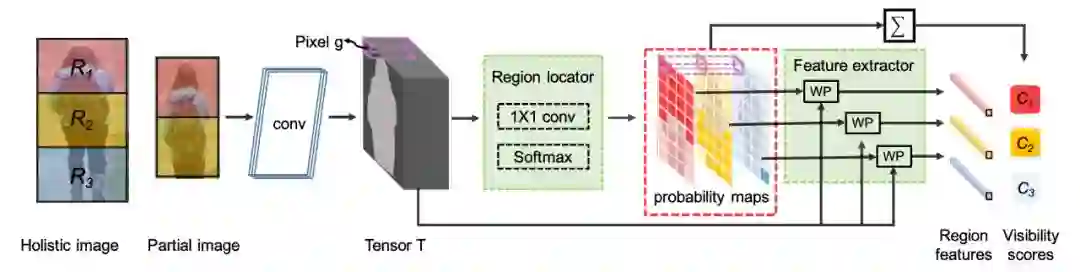
▲ 图2:VPM结构图示
VPM 是一个全卷积网络,结构如图 2 所示。本文在完整的行人图像上预先定义一个固定的部件分割,将图像分成 p 个部件(如图 2 分成上、中、下三个部件,即 p=3)。对于每一幅行人图像,VPM 输出固定数量的部件特征,以及相应的部件可见性得分。
注意,即使当前输入图像有一些部件不可见(例如图 2 中输入图像的下端部件实际不可见),VPM 仍然会为所有部件分别产生一个部件特征(包括那些不可见部件),但不可见部件的可见性得分将很低(趋于零)。这样,VPM 就能够知道哪些部件特征有效,哪些部件特征无效、不予采信。
为了实现上述功能,VPM 在卷积层输出 Tensor T 上附加一个部件定位器和一个部件特征提取器,前者通过自监督学习,学习 Tensor T 上的部件位置(及可见性得分),接着,后者则为每个部件生成一个相应特征。
自监督学习的构建非常直观,如图 2 所示。本文在完整的行人图像上预先定义一个固定的部件分割,将图像分成 p 个部件,然后裁剪,把裁减后的图像缩放到固定尺寸输入给 VPM。由于裁减参数可自动获取,从而自然知道哪些部件是可见的(如图中的上、中两个部件),哪些部件是不可见的(如图中的下端部件)。具体训练方法请参见“训练VPM”。
部件定位器
部件定位器直接在 T 上预测各个部件 pixel-wise 的分布(也可以理解为一个图像分割器,只不过分割的对象是预先定义好的部件),从而感知哪些区域可见。为此,部件定位器在 T 上使用一层 1 × 1 卷积及一个 Softmax 函数来构建一个 pixel-wise 的部件分类器,这个公式并不必要,但是为了后面引用时清晰明确,将其如下列出:
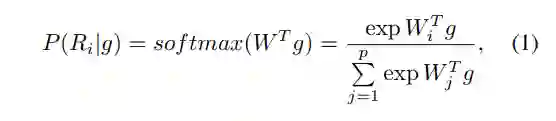
这个部件分类器实际上将产生 p 个分布概率图,每个分布概率图对应一个预先定义好的部件。这个分布概率图以 soft mask 的形式,直接指示出各个部件的位置。如果一个部件实际上不可见,那么对应于它的分布概率图应该处处为零,即各个像素属于这个部件的概率很小。
自然地,把各个概率图加起来,即可得到相应的区域可见性得分 C。这个做法非常直观:如果一个部件的分布概率图处处很小,那么这个部件可见性则很低(即可能不可见)。
部件特征提取器
得到部件的概率分布图后,就可以简单地利用带权池化提取部件特征。公式同样很简单:
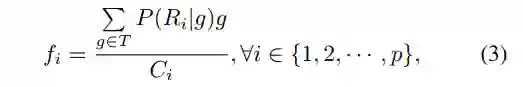
再次强调,通过上述公式,VPM 会给每个预先定义好的部件产生一个特征,即使某个部件实际不可见,但这没关系,因为实际上已知道这个部件不可见,因此可不采信这个部件特征。具体如下节介绍。
使用 VPM
给定两幅待比较的图像、
,VPM 将提取其部件特征,并分别预测所有部件的可见性分数,即
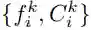
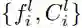
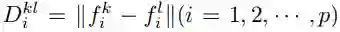
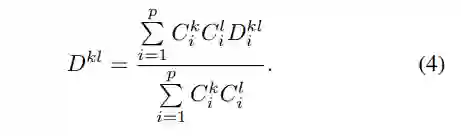
上式的效果是:采信可见区域之间的距离,忽视不可见区域之间的距离。换而言之,可见部件的距离将主导总体距离;相反,如果一个部件在任何图像中没出现,那么其部件特征则被认为不可靠,无法对
产生明显影响。
这样的调用过程非常高效:与 PCB 这种实用方法相比,VPM 仅仅增加了一层卷积运算用于预测部件可见性,计算距离则几乎不增加时间(仅仅多了公式 4 所示的加权平均)。这使得 VPM 成为了为数不多的、能够在 Market-1501 数据集上开展 partial re-ID 实验的方法(也具有在大规模实际数据集上应用的潜力)。
训练 VPM
VPM 的训练包含 1)部件定位器的训练和 2)部件特征提取器的训练。两者在 Tensor T 之前共享卷积层,并以多任务的方式被端到端训练。部件定位器的训练依靠自监督学习,而训练部件特征提取器也需要自监督信号进行辅助。由实验可知,自监督学习对 VPM 的性能至关重要。
自监督
自监督对于 VPM 十分关键,它监督 VPM 学习部件定位器,并要求 VPM 在学习部件特征时,放弃对不可靠的部件特征的监督,仅仅对可见区域施加监督。
部件定位器的训练类似 Segmentation 训练,这里仅强调一下:Label 信息由自监督产生。部件特征的学习虽然也采用了常用的分类+度量学习联合训练,但需要做一些重要调整,如图 3 所示。
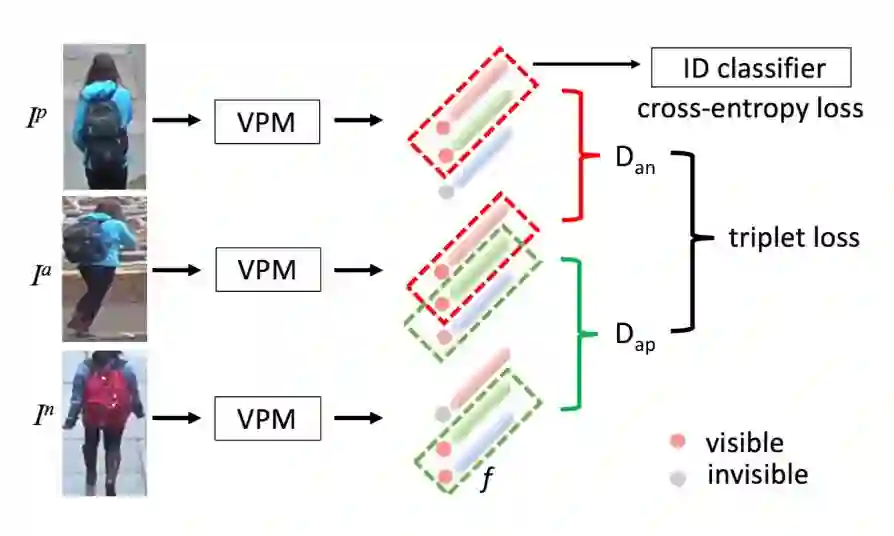
▲ 图3:VPM通过辅助性自监督学习区域特征
由于 VPM 会为所有部件分别生成一个部件特征,这导致在学习特征时出现一个非常重要的问题:只有可见部件的特征被允许贡献训练损失。借助自监督信号,旷视研究员动态地为特征学习选择可见区域。实验结果表明,如果不加区分地对所有部件特征施加监督,re-ID 准确率将剧烈降低。
总结一下,自监督对训练 VPM 的贡献体现在 3 个方面:
1. 自监督生成 pixel-wise 的部件标签用以训练部件定位器(类似于 Segmentation);
2. 在利用分类损失函数(Softmax Loss)学习部件特征时,自监督使 VPM 仅仅关注可见部件;
3. 利用度量学习(Triplet)学习部件特征时,自监督使 VPM 专注于图像的共有区域。
实验
大规模数据集实验
本文首先利用两个大型全身 re-ID 数据集(Market-1501 和 DukeMTMC-reID)合成相应的部分成像 re-ID 数据集上的实验评估 VPM 的有效性。
本文用了两种基线作为对比:首先是一个学习全局特征的基线,它是利用分类损失函数和三元组损失函数联合训练的;第二个基线则是非常流行的全身部件特征模型 PCB。实验结果如表 1 所示,可以看到 VPM 相对这两种基线都有明显提高。
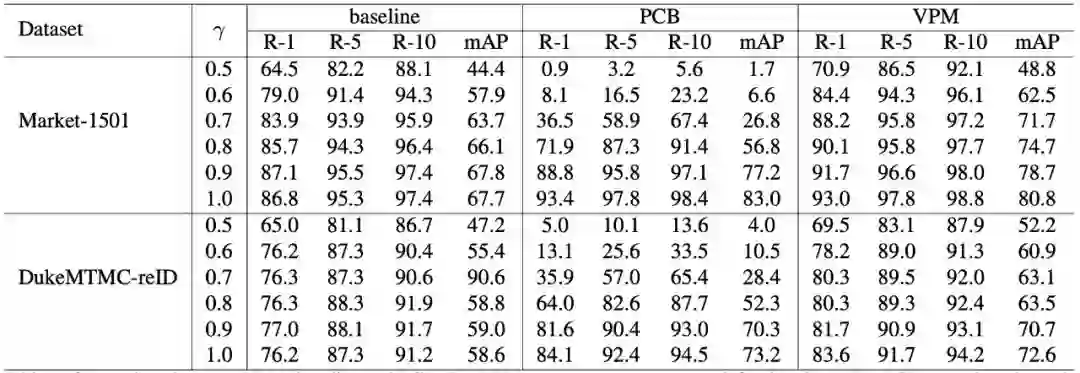
▲ 表1:VPM、baseline与PCB之间的对比
对比 SOTA
本文在两个公开数据集 Partial-REID 和 Partial-iLIDS 把 VPM 与当前最佳方法做了对比。本文训练了 3 个版本的 VPM:1)VPM(bottom),训练时总是丢弃随机比例的上半身,而下部区域可见;2)VPM(top),训练时总是丢弃随机比例的下半身,而图像的上部区域总是可见;3)VPM(bilateral),训练时,图像的上部和下部区域都有可能被随机比例丢弃。对比结果如表 2 所示。
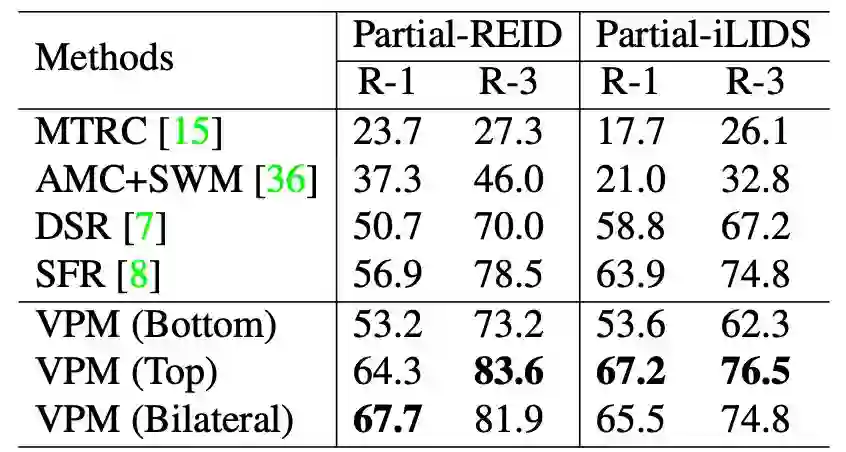
▲ 表2:VPM在Partial-REID和Partial-iLIDS上的评估结果
可以看到,训练时的 crop 策略对性能是有影响的,VPM(bottom)结果比较差。这是因为首先大部分数据集以及在实际情况中,大部分图像是下半身缺失,而上半身可见,VPM(bottom)在训练时的策略相反,背离了现实;此外,一般来讲,上半身能够提供的可鉴别线索本身就更为丰富。
文中还进行了一些其它有意思的实验,例如通过 Ablation Study 分析各个环节中自监督对 VPM 性能的影响,VPM 定位各个部件的可视化实验。
结论
本文提出一个基于可见部件感知的行人特征学习方法——VPM,它可解决局部成像下的行人再识别问题。延续 PCB 的思路,VPM 没有采用语义部件这种直观做法,而是采用了均匀分割产生若干预定义的部件。通过自监督学习,VPM 能够感知哪些部件可见、哪些部件缺失,并决定应该如何具体对比两幅图像。实验结果表明,VPM 同时超越了全局特征学习基线和部件特征学习基线,并在公开的 partial re-ID 数据集上取得了国际领先水平。
参考文献
L. He, J. Liang, H. Li, and Z. Sun. Deep spatial feature reconstruction for partial person re-identification: Alignment-free approach. CoRR, abs/1801.00881, 2018.
Y. Sun, L. Zheng, Y. Yang, Q. Tian, and S. Wang. Beyond part models: Person retrieval with refined part pooling. In ECCV, 2018.
L. Zhao, X. Li, J. Wang, and Y. Zhuang. Deeply-learned part-aligned representations for person re-identification. In ICCV, 2017.
L. Zheng, L. Shen, L. Tian, S. Wang, J. Wang, and Q. Tian. Scalable person re-identification: A benchmark. In ICCV, 2015.
L. Zheng, Y. Yang, and A. G. Hauptmann. Person re-identification: Past, present and future. arXiv preprint arXiv:1610.02984, 2016.
W. Zheng, S. Gong, and T. Xiang. Person re-identification by probabilistic relative distance comparison. In The 24th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2011, Colorado Springs, CO, USA, 20-25 June 2011, 2011.
W. Zheng, X. Li, T. Xiang, S. Liao, J. Lai, and S. Gong. Partial person re-identification. In 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, December 7-13, 2015, 2015.
Z. Zheng, L. Zheng, and Y. Yang. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In ICCV, 2017.
传送门
欢迎各位同学关注旷视研究院视频分析组(以及知乎专栏「旷视Video组」:https://zhuanlan.zhihu.com/r-video),简历可以投递给负责人张弛(zhangchi@megvii.com)。
往期解读:

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐


