CVPR 2019 | 旷视研究院提出极轻量级年龄估计模型C3AE

全球计算机视觉三大顶级会议之一 CVPR 2019 将于当地时间 6 月 16-20 日在美国洛杉矶举办。届时,旷视研究院将带领团队远赴盛会,助力计算机视觉技术的交流与落地。在此之前,旷视每周会介绍一篇被 CVPR 2019 接收的论文,本文是第 9 篇,旷视成都研究院提出一个极其简单但是高效、基于上下文信息的级联性年龄估计模型 ——C3AE。

论文名称:C3AE: Exploring the Limits of Compact Model for Age Estimation
论文链接:https://arxiv.org/abs/1904.05059
导语
简介
模型
用于小尺寸图像的紧致模型:重新思考标准卷积
年龄的两点表征
级联训练
基于周围环境的回归模型
实验
在 Morph II 上的对比
在 FG-NET 上的对比
结论
参考文献
往期解读
导语
在计算机视觉领域,年龄估计(Age Estimation)是一个经典的学习问题。随着 CNN 网络(比如 AlexNet、VGGNet、GoogLeNet、ResNet)不断变大变深,其性能也获得长足提升;但是上述模型并不适用于嵌入式/移动设备。
最近,MobileNet 和 ShuffleNet 系列算法降低参数数量,带来了轻量级模型。但是由于采用深度可分离卷积,特征表达能力被弱化。在调查了紧致模型(Compact Model)在中小尺度图像方面的局限性之后,旷视研究院提出了一个极其简单但高效的基于语境的年龄估计模型 ——C3AE。
相较于 MobileNets、ShuffleNets 和 VGGNet,该网络只有其 1/9 和 1/2000 的参数量,但取得了极具竞争力的性能。具体而言,旷视研究院把年龄估计问题重新定义为基于级联模型的两点表示;并且,为充分利用面部的上下文信息,提出了三分支 CNN 网络,以集成多个尺度的上下文信息。三个年龄估计数据集上的实验表明,C3AE 很大程度地推进了紧致模型的当前最佳性能。
简介
近年来,越大越深的卷积神经网络在带来精度提升的同时,也带来了计算成本前所未有的提升,无论是对于训练还是部署而言。具体而言,受限于模型大小和计算量,在智能手机、汽车、机器人等嵌入式/边缘设备上运行现有的大型模型(比如 AlexNet、VGGNet、ResNet、InceptionV1-V4)几近不可能。
为解决上述问题,最近,MobileNet 和 ShuffleNet 系列算法通过深度可分离卷积方法极大减少参数量,在这些模型中,传统的卷积被一个两步的改进卷积所替代,即逐通道卷积和逐点卷积。这两个系列算法将所有的关注点都集中在模型改进上,忽略了图像的输入尺寸也与模型设计息息相关,尤其是紧致性模型设计。事实上,卷积模块中的卷积层/或者池化层很大程度上类似直接对图像做下采样操作,但是其卷积层却耗费了大量的参数和计算量。
对于大尺寸图像而言,这样的操作(可分离卷积)是可行的,因为图像需要被大量通道所表征;对于低分辨率的中小尺寸图像来说,这就需要打问号。另外对于识别问题来说,许多高清的大尺度图像是没有必要的,几倍的下采样往往并不影响模型的性能,但却极大地影响着模型设计。
相较于大尺寸图像,中小尺寸图像经常只需要网络中更少的通道来表征,当然计算量和参数量也一样会大幅度减少。因此,和深度可分离卷积相比,中小尺寸图像的标准卷积层并不需要太多的参数和内存。
从图像表征的角度看,可分离卷积的输出通道数量是标准卷积的很多倍。为补偿表征能力,可分离卷积不得不增加参数。因此,旷视研究院认为,使用小卷积核的一般卷积层比深度可分离卷积层更适合处理中小尺寸图像。
之前的许多紧致性模型都在思考如何改进模型或者卷积层以满足现实需求,很少考虑图像的输入尺寸与模型设计的关系。对于一个识别系统来说,当图像清晰度合适时,许多低分辨率的图像往往也是非常合格的训练样本,如图 1 所示。
图像的存储和处理要在低分辨率、中小尺寸的情况下,即小图像运行在低功耗的移动设备上,年龄估计即是与此相关的困难问题之一。
比如,人们可以轻易地识别出图 1 中男人的年龄,不管他的脸是低分辨率、局部或是全局的。旷视研究院认为,当下的普通卷积神经网络同样可以拥有这种能力,通过设计一个带有标准卷积层的简单网络,并把中小尺寸人脸图像作为年龄估计的输入,也能设计一个非常紧致的模型。事实上,对图像进行下采样的过程就对应到神经网络中的池化过程,只是之前的许多工作都把研究重心放在了模型改进上。

▲ 图1:不管何种分辨率和大小,人们可以轻易识别上图男子的年龄。旷视研究院新方法 C3AE 把小尺寸图像(64 × 64 × 3)作为输入进行年龄估计,同样取得了不俗的效果
年龄估计的最新进展通常归纳为两个方向:1)联合分类与年龄值回归,2)分布匹配。在本文中,旷视研究院尝试同时利用分类、回归和标签分布的信息,它的实现是通过把年龄值表征为两个相邻年龄等级上的一个分布(如图 2 所示),并且训练目标是最小化分布之间的匹配(如图 3 所示)。
在深度回归模型中,会在特征层和年龄值预测层之间嵌入一个带有语义分布的全连接层,该全连接层即是预测的分布。
总体而言,旷视研究院设计了一个紧致模型,它把所有中/小尺度图像作为输入,使用标准卷积而不是深度卷积,其中能较好地控制特征层的通道数。据知,这应该是目前为止最小的人脸识别模型,基础模型仅 0.19 MB,完整模型约 0.25 MB;接着,旷视研究员把分离的年龄值表征为一个分布,并设计一个级联模型;进而,旷视研究员引入一个基于语境的回归模型,它把多个尺寸的人脸图像作为输入。
借助于这一简单的基础模型、级联式训练以及多尺寸语境,旷视研究院旨在解决所有的中小尺寸图像的年龄估计问题,这一方法称之为——C3AE。事实上这一思路可以推广到许多其他的应用中。
模型
旷视研究员首先展示了基础模型及其架构,接着描述了新的年龄两点表示方法,并通过级联的方式将其嵌入到深度回归模型中。随后,借助于三个不同尺度下的人脸信息,加入了基于周围环境信息的集成模块,通过共享的 CNN 嵌入到单一的回归模型中。
用于中小尺寸图像的紧致模型:重新思考标准卷积
本文的基础模型(plain model)由 5 个标准卷积和 2 个全连接层构成,如表 1 所示;旷视研究员还展示为什么使用标准的卷积模块而不是 MobileNet 和 ShuffleNet 系列模型所用的可分离的卷积模块。本文设计的基础模型极其简单,也不 fashion,但是一点也不影响其良好的性能。
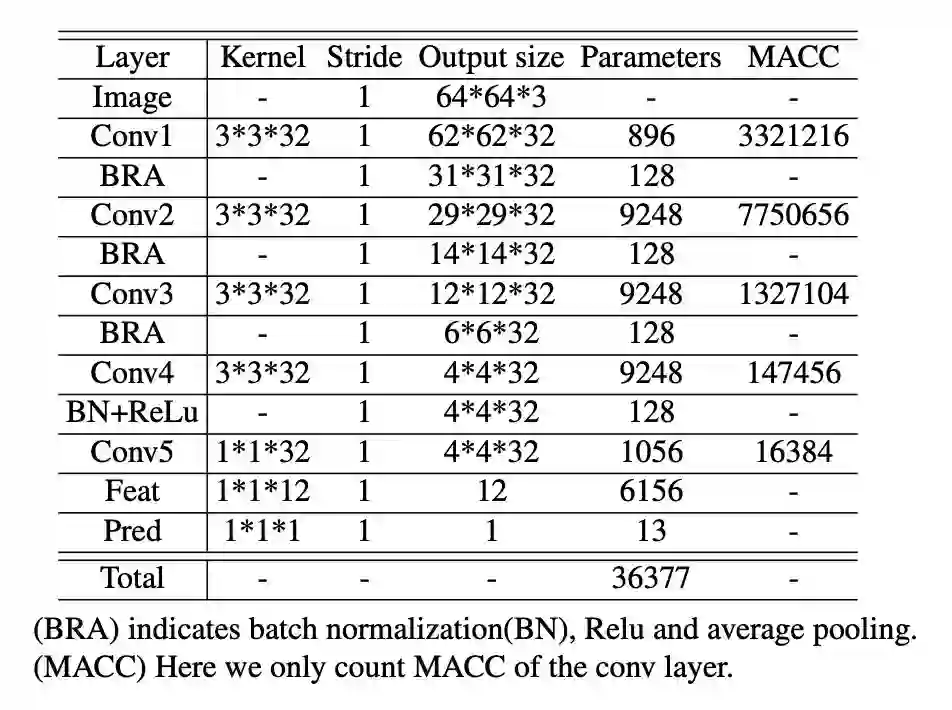
▲ 表1:C3AE基础模型
在 MobileNet 系列模型中,对参数量与计算量降低方面的状况进行了分析,尤其是标准卷积和可分离卷积之间的对比。这一分析适用于大尺寸图像,而对于中、小尺寸图像,效果则不一定好。
年龄的两点表征
旷视研究员借助两点表征对年龄估计实现了重新定义,即把一个全新的年龄表征看作是两个离散且相邻的 bin 的一个分布。任意点的表征是通过两个邻近的 bin,而不是任意两个或多个 bin 来表示。显然,两点表征的分布是稀疏的,只有其中两个元素是非零的。
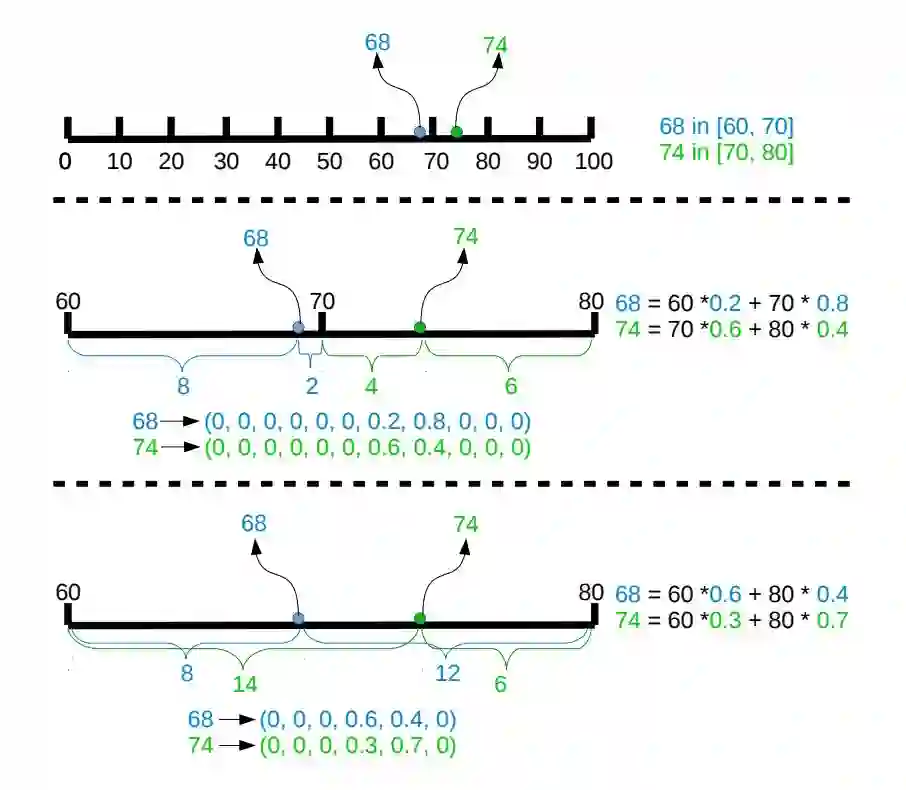
▲ 图3:借助两点表征重新定义年龄估计任务
级联训练
年龄值可由分布向量表征,但是分布向量的组合方式是多种多样的。两点表征很适合解决这种多样性的不足。那么下一个问题是,如何把向量信息嵌入到一个端到端的网络中。本文通过级联模型做到了这一步,如图 2 所示。具体而言,一个带有语义信息(年龄分布)的全连接层被嵌入到特征层和回归层之间,并使用 KL loss 进行约束。
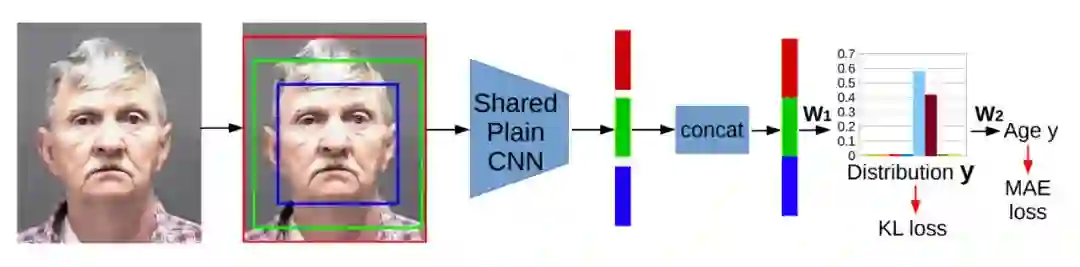
▲ 图2:C3AE图示
基于周围环境的回归模型
中小尺寸图像的分辨率和大小是限定的,利用不同尺寸下的人脸信息很有必要。如图 1 所示,分辨率更高的图像有着丰富的局部信息,而分辨率较低的图像则有着全局信息和场景信息。除了挑选 SSR 中一个对齐的人脸框外,本文按照三个尺寸剪裁人脸中心,如图 2 所示,紧接着将其输入到共享的 CNN 网络,最后三种尺寸的人脸图像的特征通过级联模块之前的串联(concatenation)进行聚合。
实验
实验包含三个部分。第一部分是基础模型的对比实验(1):对比使用基础模型的 SSR、MobileNet V2、ShuffleNet V2 和 C3AE;第二部分是消去实验(2):讨论级联模块(两点表示)和基于周围场景模块的必要性;第三部分是与当前最优方法的一些对比实验。本文主要介绍第三部分。
在 Morph II 上的对比
如表 5 所示,在 Morph II 上,C3AE(full model)在从头开始训练和在 IMDB-WIKI 上预训练两种情况下分别取得了2.78 和 2.75 MAE,这是所有简单模型中的当前最佳结果;而C3AE(plain model)则直截了当地取得了 3.13 MAE。总之,C3AE 以超轻量级模型在 Morph II 上取得了很有竞争力的结果。
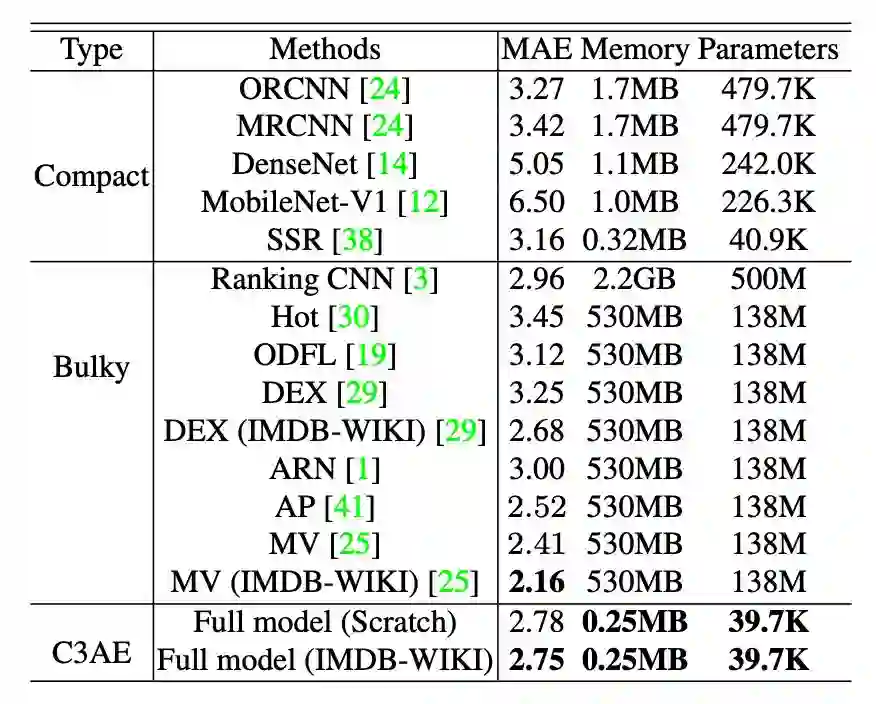
▲ 表5:C3AE在Morph II上的对比结果
在 FG-NET 上的对比
如表 6 所示,在 FG-NET 上,C3AE 与一些当前最优模型做了对比。通过平均绝对值损失,经过预训练的 MV 取得了最佳结果 2.68 MAE,而 C3AE 经过预训练实现的结果是 2.95 MAE 和 0.17 std,即第二优结果。此外,在没有预训练的情况下,C3AE 取得的结果 4.09 稍优于 MV 的 4.10。总之,在 FG-NET 上的对比证明了 C3AE 的有效性和竞争力。
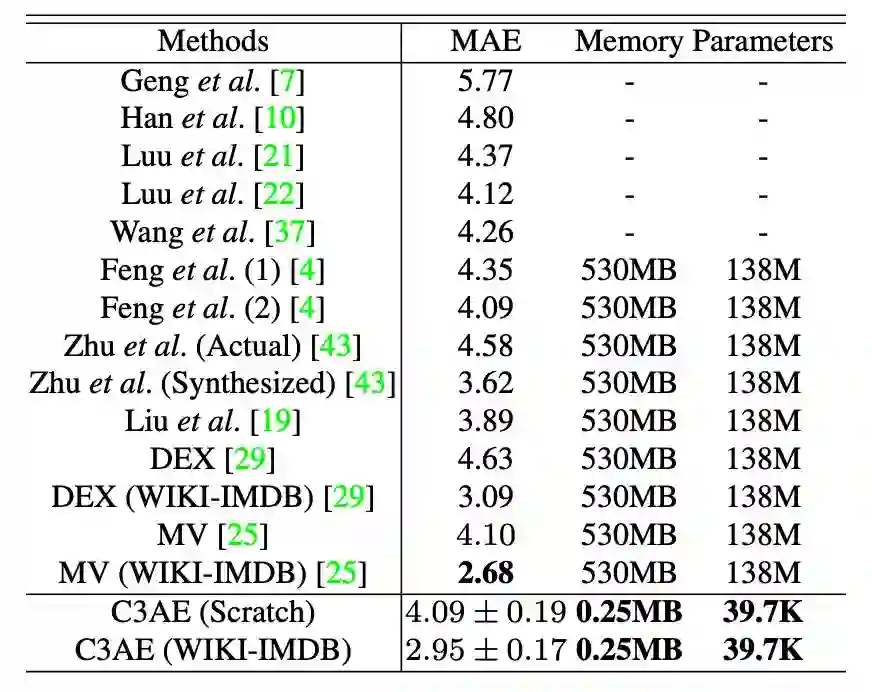
▲ 表6:C3AE在FG-NET上的对比结果
结论
旷视研究院提出了一个极简单模型,称之为 C3AE,相较于其他简单模型(紧致性模型),C3AE 取得了当前最优的结果,且相比于大模型其表现也很有竞争力。多个消去实验也证明了 C3AE 各个模块的有效性。对于中小尺寸的图像和模型,本文也给出了一些分析和思考。未来,旷视研究院将会评估 C3AE 在一般数据集和更广泛应用上的有效性。
参考文献
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residuallearning for image recognition. In CVPR, 2016.
Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, WeijunWang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficientconvolutional neural networks for mobile vision applications. arXiv preprintarXiv:1704.04861, 2017.
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenetclassification with deep convolutional neural networks. In NIPS, 2012.
Ningning Ma,Xiangyu Zhang, Hai-Tao Zheng, and Jian Sun. Shufflenetv2: Practical guidelines for efficient cnn architec- ture design. In ECCV,2018.
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zh- moginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In CVPR, 2018.
X Zhang, X Zhou, M Lin, and J Sun. Shufflenet: An extremelyefficient convolutional neural network for mobile devices. arxiv 2017. arXivpreprint arXiv:1707.01083.
传送门
欢迎各位同学关注旷视成都研究院(及同名知乎专栏:https://zhuanlan.zhihu.com/c_1119253499380166656,简历可以投递给研究院负责人刘帅成(liushuaicheng@megvii.com)
往期解读:

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐


