深度学习面试100题(第26-30题)
26.神经网络中激活函数的真正意义?一个激活函数需要具有哪些必要的属性?还有哪些属性是好的属性但不必要的?
解析:
(1)非线性:即导数不是常数。这个条件是多层神经网络的基础,保证多层网络不退化成单层线性网络。这也是激活函数的意义所在。
(2)几乎处处可微:可微性保证了在优化中梯度的可计算性。传统的激活函数如sigmoid等满足处处可微。对于分段线性函数比如ReLU,只满足几乎处处可微(即仅在有限个点处不可微)。对于SGD算法来说,由于几乎不可能收敛到梯度接近零的位置,有限的不可微点对于优化结果不会有很大影响[1]。
(3)计算简单:非线性函数有很多。极端的说,一个多层神经网络也可以作为一个非线性函数,类似于Network In Network[2]中把它当做卷积操作的做法。但激活函数在神经网络前向的计算次数与神经元的个数成正比,因此简单的非线性函数自然更适合用作激活函数。这也是ReLU之流比其它使用Exp等操作的激活函数更受欢迎的其中一个原因。
(4)非饱和性(saturation):饱和指的是在某些区间梯度接近于零(即梯度消失),使得参数无法继续更新的问题。最经典的例子是Sigmoid,它的导数在x为比较大的正值和比较小的负值时都会接近于0。更极端的例子是阶跃函数,由于它在几乎所有位置的梯度都为0,因此处处饱和,无法作为激活函数。ReLU在x>0时导数恒为1,因此对于再大的正值也不会饱和。但同时对于x<0,其梯度恒为0,这时候它也会出现饱和的现象(在这种情况下通常称为dying ReLU)。Leaky ReLU[3]和PReLU[4]的提出正是为了解决这一问题。
(5)单调性(monotonic):即导数符号不变。这个性质大部分激活函数都有,除了诸如sin、cos等。个人理解,单调性使得在激活函数处的梯度方向不会经常改变,从而让训练更容易收敛。
(6)输出范围有限:有限的输出范围使得网络对于一些比较大的输入也会比较稳定,这也是为什么早期的激活函数都以此类函数为主,如Sigmoid、TanH。但这导致了前面提到的梯度消失问题,而且强行让每一层的输出限制到固定范围会限制其表达能力。因此现在这类函数仅用于某些需要特定输出范围的场合,比如概率输出(此时loss函数中的log操作能够抵消其梯度消失的影响[1])、LSTM里的gate函数。
(7)接近恒等变换(identity):即约等于x。这样的好处是使得输出的幅值不会随着深度的增加而发生显著的增加,从而使网络更为稳定,同时梯度也能够更容易地回传。这个与非线性是有点矛盾的,因此激活函数基本只是部分满足这个条件,比如TanH只在原点附近有线性区(在原点为0且在原点的导数为1),而ReLU只在x>0时为线性。这个性质也让初始化参数范围的推导更为简单[5][4]。额外提一句,这种恒等变换的性质也被其他一些网络结构设计所借鉴,比如CNN中的ResNet[6]和RNN中的LSTM。
(8)参数少:大部分激活函数都是没有参数的。像PReLU带单个参数会略微增加网络的大小。还有一个例外是Maxout[7],尽管本身没有参数,但在同样输出通道数下k路Maxout需要的输入通道数是其它函数的k倍,这意味着神经元数目也需要变为k倍;但如果不考虑维持输出通道数的情况下,该激活函数又能将参数个数减少为原来的k倍。
(9)归一化(normalization):这个是最近才出来的概念,对应的激活函数是SELU[8],主要思想是使样本分布自动归一化到零均值、单位方差的分布,从而稳定训练。在这之前,这种归一化的思想也被用于网络结构的设计,比如Batch Normalization[9]。
27.梯度下降法的神经网络容易收敛到局部最优,为什么应用广泛?
解析:
深度神经网络“容易收敛到局部最优”,很可能是一种想象,实际情况是,我们可能从来没有找到过“局部最优”,更别说全局最优了。
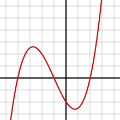
很多人都有一种看法,就是“局部最优是神经网络优化的主要难点”。这来源于一维优化问题的直观想象。在单变量的情形下,优化问题最直观的困难就是有很多局部极值,如
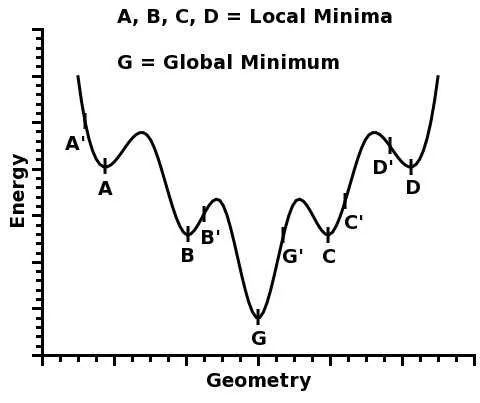
人们直观的想象,高维的时候这样的局部极值会更多,指数级的增加,于是优化到全局最优就更难了。然而单变量到多变量一个重要差异是,单变量的时候,Hessian矩阵只有一个特征值,于是无论这个特征值的符号正负,一个临界点都是局部极值。但是在多变量的时候,Hessian有多个不同的特征值,这时候各个特征值就可能会有更复杂的分布,如有正有负的不定型和有多个退化特征值(零特征值)的半定型
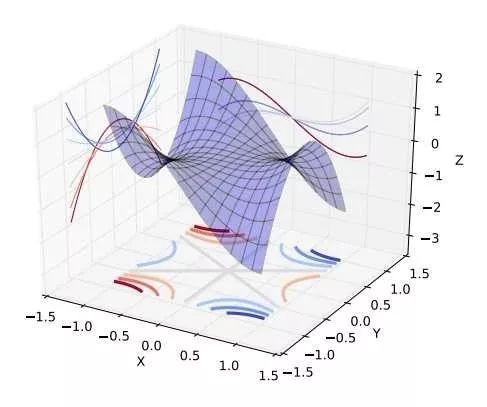
在后两种情况下,是很难找到局部极值的,更别说全局最优了。
现在看来,神经网络的训练的困难主要是鞍点的问题。在实际中,我们很可能也从来没有真的遇到过局部极值。Bengio组这篇文章Eigenvalues of the Hessian in Deep Learning(https://arxiv.org/abs/1611.07476)里面的实验研究给出以下的结论:
• Training stops at a point that has a small gradient. The norm of the gradient is not zero, therefore it does not, technically speaking, converge to a critical point.
• There are still negative eigenvalues even when they are small in magnitude.
另一方面,一个好消息是,即使有局部极值,具有较差的loss的局部极值的吸引域也是很小的Towards Understanding Generalization of Deep Learning: Perspective of Loss Landscapes。(https://arxiv.org/abs/1706.10239)
For the landscape of loss function for deep networks, the volume of basin of attraction of good minima dominates over that of poor minima, which guarantees optimization methods with random initialization to converge to good minima.
所以,很可能我们实际上是在“什么也没找到”的情况下就停止了训练,然后拿到测试集上试试,“咦,效果还不错”。
补充说明,这些都是实验研究结果。理论方面,各种假设下,深度神经网络的Landscape 的鞍点数目指数增加,而具有较差loss的局部极值非常少。
28.简单说说CNN常用的几个模型。
解析:

29.为什么很多做人脸的Paper会最后加入一个Local Connected Conv?
解析:
以FaceBook DeepFace 为例:
DeepFace 先进行了两次全卷积+一次池化,提取了低层次的边缘/纹理等特征。后接了3个Local-Conv层,这里是用Local-Conv的原因是,人脸在不同的区域存在不同的特征(眼睛/鼻子/嘴的分布位置相对固定),当不存在全局的局部特征分布时,Local-Conv更适合特征的提取。
30.什么是梯度爆炸?
解析:
误差梯度是神经网络训练过程中计算的方向和数量,用于以正确的方向和合适的量更新网络权重。
在深层网络或循环神经网络中,误差梯度可在更新中累积,变成非常大的梯度,然后导致网络权重的大幅更新,并因此使网络变得不稳定。在极端情况下,权重的值变得非常大,以至于溢出,导致 NaN 值。
网络层之间的梯度(值大于 1.0)重复相乘导致的指数级增长会产生梯度爆炸。
参考资料:
1.Hengkai Guo,
https://www.zhihu.com/question/67366051;
2.李振华,
https://www.zhihu.com/question/68109802/answer/262143638;
3.许韩,
https://zhuanlan.zhihu.com/p/25005808。
题目来源:
七月在线官网(https://www.julyedu.com/)——面试题库——面试大题——深度学习 第21-25题。

为了帮助大家更好的学习和理解深度学习,我们特意推出了“深度学习第四期”课程,7月31日开课,每周二周四晚上8~10点直播上课,每次课至少2小时,共10次课;本课程提供以下服务:直播答疑、课后回放、布置作业且解答、毕业考试且批改、面试辅导。课程详情可点击文末“阅读原文”进行查看,或者加微信客服:julyedukefu_02 进行咨询。
扫码加客服微信