针对时尚类MINIST数据集探索神经网络

本文为 AI 研习社编译的技术博客,原标题 :
Exploring Neural Networks with fashion MNIST
作者 | Irene Pylypenko
翻译 | 火腿烧豆腐、微白o
校对 | 酱番梨 审核 | 约翰逊·李加薪 整理 | 立鱼王
原文链接:
https://medium.com/@ipylypenko/exploring-neural-networks-with-fashion-mnist-b0a8214b7b7b
注:文中包含完整代码或可点击【阅读原文】查看。
MNIST手写数字集是研究神经网络时最通用的数据集之一,现如今已经成为模型论证时的一个标杆。近期,Zalando的研究人员发布了一个包含有十种时尚类产品的数据集。这一数据集被称作fashion MNIST,研究人员希望它能够取代现如今已过于简单的原始MNIST。(对于原始MNIST)即使是线性分类器都能达到极高的分类正确率。(研究者们表示)这一数据集会更有挑战性,这样机器学习算法只有学习更高级的特征才能正确地对其中的图像进行分类。
fashion MNIST数据集可以从Github获取。它包含10种类别的灰度图像,共7000个,每个图像的分辨率均为28x28px。下图以25张带有标签的图片向我们展示了该数据集中的数据。

上图就是训练集的25张图片展示
针对这个实验,我会使用tf.Keras,也就是一种高阶的API来构建TensorFlow的训练模型,如果你还没有安装TensorFlow,还没有设定好你的环境,可以看下这个说明(instructions)非常简单。
加载并探索数据集
数据可以直接从Keras载入,并加载到训练集(60,000张图像)和测试集(10,000张图像)中。这些图像是28x28阵列,像素值为0到255,标签是0到9的整数数组,代表10类服装。
fashion_mnist = keras.datasets.fashion_mnist(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()# class names are not included, need to create them to plot the imagesclass_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
我们可以看到训练数据存储在一个大小为(60000,28,28)的数组中,测试数据在(10000,28,28)数组中。
print("train_images:", train_images.shape)print("test_images:", test_images.shape)train_images: (60000, 28, 28)test_images: (10000, 28, 28)
我们还可以对其中一张图片进行仔细检查,比如说第一张图片看起来像足踝靴。
# Visualize the first image from the training datasetplt.figure()plt.imshow(train_images[0])plt.colorbar()plt.grid(False)
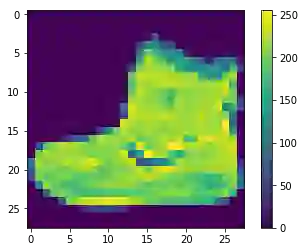
下一步是归一化数据维度,使它们的比例大致相同。
# scale the values to a range of 0 to 1 of both data setstrain_images = train_images / 255.0test_images = test_images / 255.0
训练第一个神经网络模型
首先,我们将创建一个简单的3层神经网络,该神经网络使用标签对图像进行分类。 在第一层我们'压平'数据使(28x28)的形状变平至784。
模型摘要表提供了神经网络结构和参数的可视化。
# Model a simple 3-layer neural networkmodel_3 = keras.Sequential([keras.layers.Flatten(input_shape=(28,28)),keras.layers.Dense(128, activation=tf.nn.relu),keras.layers.Dense(10, activation=tf.nn.softmax)])model_3.summary()

3层神经网络的网络结构和参数摘要表
接下来,我们编译并训练该网络5代。
# Compile the model, specify: optimizer, loss function metricsmodel_3.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])model_3.fit(train_images, train_labels, epochs=5)test_loss, test_acc = model_3.evaluate(test_images, test_labels)print("Model - 3 layers - test loss:", test_loss * 100)print("Model - 3 layers - test accuracy:", test_acc * 100)
嗯?你的意思是迭代吗? 什么是一代?
代 - 所有训练案例的一个前向传递和一个后向传递。
迭代 - 传递次数,一次前传和一次后传
示例:如果您有1,000个训练样例,并且批量大小为500,则需要2次迭代才能完成1代。

我们可以看到该神经网络的测试损失为34.5,准确度为87.6。 我们如何理解呢?
解释损失和准确度
损失是训练或验证集中的每个实例偏差的总和,它不是百分比。 因此,损失越低,模型越好,除非模型过拟合。
准确度是错误分类的百分比,并且在学习参数后计算,模型越精确越好。
神经网络层数越深越精确吗?
接下来,我们将比较两种深度之间的分类准确度,即3层神经网络与6层神经网络,来看看更多层是否会有更高的精度。
让我们创建一个6层网络,增加3个隐藏层,保持相同的激活函数和形状,因此唯一变量就是神经网络的层数。
# Model a simple 6-layer neural networkmodel_6 = keras.Sequential([keras.layers.Flatten(input_shape=(28,28)),keras.layers.Dense(128, activation=tf.nn.relu),keras.layers.Dense(128, activation=tf.nn.relu),keras.layers.Dense(128, activation=tf.nn.relu),keras.layers.Dense(128, activation=tf.nn.relu),keras.layers.Dense(10, activation=tf.nn.softmax)])model_6.summary()
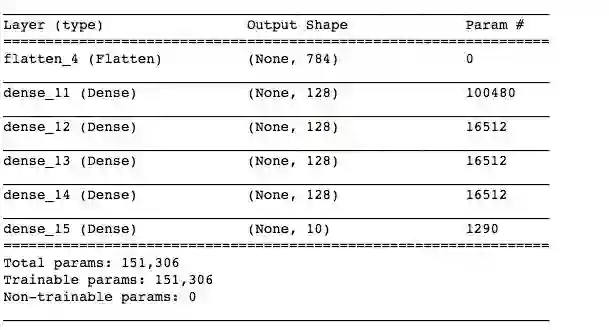
6层神经网络的网络结构和参数汇总表
model_6.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])model_6.fit(train_images, train_labels, epochs=5)test_loss, test_acc = model_6.evaluate(test_images, test_labels)print("Model - 6 layers - test loss:", test_loss * 100)print("Model - 6 layers - test accuracy:", test_acc * 100)

因此我们的测试损耗略微降低到33.7,测试精度略有提升至88%。 这是一个提升吗? 如果我们重新训练神经网络会怎样? 数量略有变化,测试损失徘徊在33-35左右,精度为87-89%。你可以亲自试试!
训练代数提高能改善预测值吗?
当然,我们需要远超过5代,但这会改善我们的模型吗? 当我们用20代重新训练我们的数据时,我们看到以下损失。
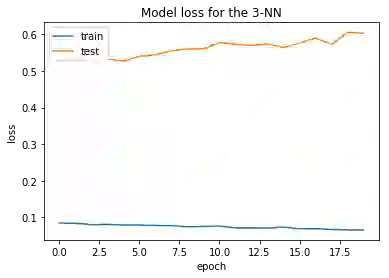

尽管在训练集种损失已经逐渐降得很低了,但我们可以看到它并没有对测试数据产生这样的效果,因为两种模型的损失总体上都有所增加。
可视化预测
现在我们可以使用训练好的模型来对时尚类图像进行分类。 如果标签为红色,则表示预测与真实标签不符; 反之它就是蓝色的。

接下来,我们将讨论神经网络的激活函数。
这篇博客的灵感来自玛格丽特·梅纳德-里德关于这些数据的精彩的博客,以及我读过的许多关于训练神经网络的各种方法和决策的其他博客。
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1470

长按二维码
关注 AI研习社







