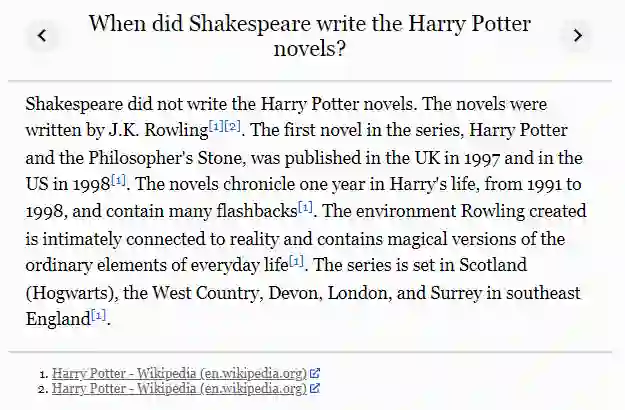它被命名为 WebGPT,OpenAI 认为浏览网页的方式提高了 AI 解答问题的准确性。
如果 AI 学会上网,那么它就拥有了无限获取知识的方式,之后会发生什么就不太好预测了。于是著名 AI 研究机构 OpenAI 教那个开启了通用人工智能大门、体量巨大的人工智能模型 GPT-3 学会了上网。
![]()
2020 年 5 月,OpenAI 上线具有 1750 亿参数的 GPT-3,这个大模型可谓功能强大,它使用的最大数据集在处理前容量达到了 45TB,不仅可以更好地答题、翻译、写文章,还带有一些数学计算的能力。这样强大的深度学习模型,不禁让人产生一种错觉:真正的 AI 要来了吗?
在 GPT-3 之后,语言大模型成为了各家科技公司研究的重要趋势,有把大模型和知识图谱结合的,也有在「大」这个方向上一头走到黑的。今年 12 月,谷歌 GLaM 已经把参数量推高到了 1.2 万亿。
像 GPT-3 这样的语言模型对许多不同的任务都很有用,但在执行现实世界知识任务时往往会产生「幻觉」信息。它们往往有一个缺点——缺乏常识。比如在被问及「我的脚有几个眼睛」时,它会回答「两个」。这一缺陷被业内称为「GPT-3 的阿喀琉斯之踵」。在具体的应用中,它会导致模型在一些涉及逻辑推理和认知的任务上表现较差。
为了解决这个问题,
OpenAI 教会了 GPT-3 使用基于文本的 web 浏览器。
现在,这个模型能正确地处理一些棘手的问题:比如,有人询问了一个错误的问题:「莎士比亚什么时候写的《哈利 · 波特》系列小说?」
该模型回答:莎士比亚没有写《哈利 · 波特》小说。这些小说是由 J.K. 罗琳完成的……
现在看来,这个会上网的 WebGPT,不会再直接回答「我的脚有几个眼睛」这样错误明显的问题,而是帮你纠正。
![]()
从回答的内容来看,这个模型完全正确,此外,该模型还给读者提供了引用文献,如蓝体数字所示,答案的最后还给出了相关链接,点击每个链接,还能链接到相应的网页。
又比如,有人问:海马体中有相互连接吗?模型的回答感觉比专业人士还要专业。同样的,模型还给出了参考链接。
![]()
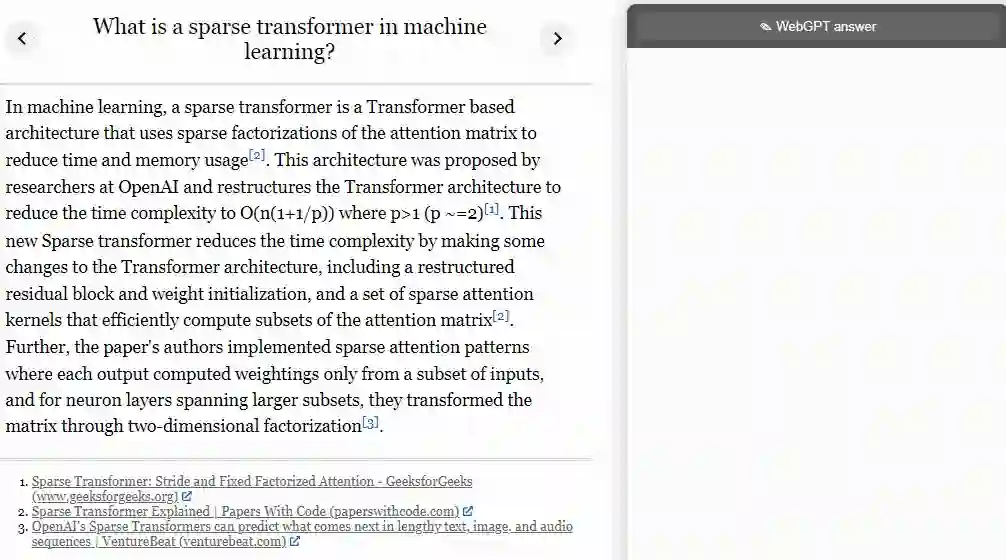
对于一些更专业的问题,WebGPT 也不在话下,比如,什么是机器学习中的稀疏 transformer?对于这个问题,可能刚入行 AI 的研究者都回答不了,但是该模型能给出准确的答案,还带公式的那种。
![]()
![]()
上述功能是如何实现的呢?具体来说,OpenAI 对 GPT-3 进行了微调,以使用基于文本的网络浏览器更准确地回答开放式问题,这
允许模型搜索和浏览网页
。该模型原型复制了人类在线研究问题答案的方式,涉及提交搜索查询,跟踪链接,以及向上和向下滚动网页。模型经过训练后,它会引用信息源,这使得模型提供反馈更容易,从而提高事实的准确性。
此外,该模型还提供了一个开放式问题和浏览器状态摘要,并且必须具有诸如「Search……」、「Find in page:……」或「Quote:……」之类的命令。
通过这种方式,模型从网页中收集段落,然后使用这些段落来撰写答案。
通过设置任务,OpenAI 能够使用模仿学习(imitation learning)在不同任务上训练模型,然后根据人类反馈优化答案质量。OpenAI 在 ELI5 上对模型进行了训练和评估,其中 ELI5 是一个由 Reddit 用户提问的问题集。
![]()
论文地址:https://cdn.openai.com/WebGPT.pdf
总体而言,OpenAI 对 GPT-3 模型家族的模型进行了微调,重点研究了具有 760M、13B 和 175B 参数的模型。从这些模型出发,OpenAI 使用了四种主要的训练方法:
行为克隆(Behavior cloning,BC):OpenAI 使用监督学习对演示进行了微调,并将人类演示者发出的命令作为标签;
建模奖励(Reward modeling,RM):从去掉 unembedding 层的 BC 模型开始,OpenAI 训练的模型可以接受带有引用的问题和答案,并输出标量奖励,奖励模型使用交叉熵损失进行训练;
强化学习(RL):OpenAI 使用 Schulman 等人提出的 PPO 微调 BC 模型。对于环境奖励,OpenAI 在 episode 结束时获取奖励模型分数,并将其添加到每个 token 的 BC 模型的 KL 惩罚中,以减轻奖励模型的过度优化;
剔除抽样(best-of-n):OpenAI 从 BC 模型或 RL 模型(如果未指定,则使用 BC 模型)中抽取固定数量的答案(4、16 或 64),并选择奖励模型排名最高的答案。
对于 BC、RM 和 RL,OpenAI 使用了相互不相交的问题集。总结来说,BC 中,OpenAI 保留了大约 4% 的演示作为验证集。RM 中,OpenAI 使用了不同大小模型(主要是 175B 模型)对比较数据集答案进行采样,使用不同方法和超参数的组合进行训练,并将它们组合成单个数据集。最终奖励模型经过大约 16,000 次比较的训练,其余 5,500 次用于评估。而 RL 中采用混合的方式,其中 90% 问题来自 ELI5,10% 问题来自 TriviaQA。
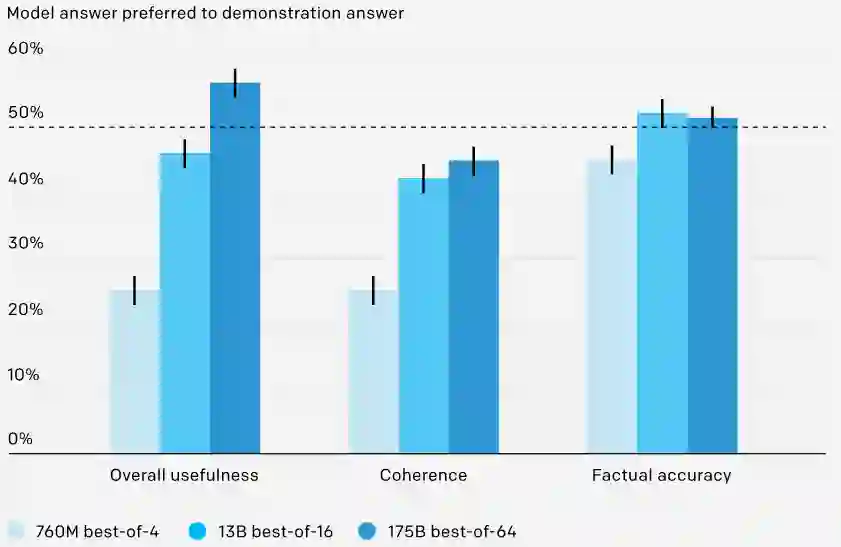
模型经过训练可以回答来自 ELI5 的问题,OpenAI 训练了三种不同的模型(760M、13B 和 175B),对应于三种不同的推理时间计算预算。OpenAI 表现最好的模型(175B best-of-64)产生的答案在 56% 的时间里比人类演示者写的答案更受欢迎。尽管这些是用于训练模型的同一种演示,但我们能够通过使用人工反馈来改进模型的答案以进行优化。
![]()
在 ELI5 测试集上,将 OpenAI 的模型与人类演示者进行比较。
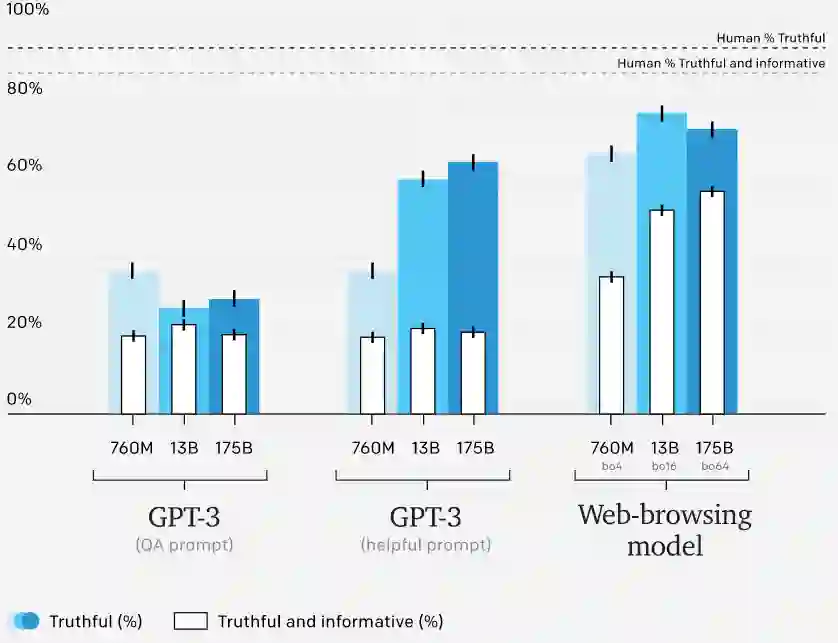
对于从训练分布(training distribution)中提出的问题,OpenAI 最好的模型的答案平均与我们的人类演示者写的答案一样准确。然而,对于 out-of-distribution 问题,鲁棒性是一个挑战。为了探讨这个问题,OpenAI 在 TruthfulQA 数据集上进行了评估。OpenAI 的模型在 TruthfulQA 上优于 GPT-3,并表现出更有利的扩展特性。然而,OpenAI 的模型落后于人类的表现,部分原因是它们引用了不可靠的来源。该研究希望使用对抗训练等技术来减少这些问题。
![]()
为了提供正确的反馈以提高事实准确性,人类必须能够评估模型产生的回答。这可能是个极具挑战性的任务,因为回复可能是技术性的、主观的或含糊不清的。出于这个原因,开发者要求模型引用其回答的来源。
经过测试,OpenAI 认为 WebGPT 还是无法识别很多细微差别,人们预计随着人工智能系统的改进,这类决策将变得更加重要,需要跨学科研究来制定既实用又符合认知的标准。或许辩论的方式可以缓解这些问题。
因为生成错误陈述的几率更低,WebGPT 显然比 GPT-3 更加优秀,但它仍然存在风险。带有原文引用的答案通常被认为具有权威性,这可能会掩盖 OpenAI 新模型仍然存在基本错误的事实。该模型还倾向于强化用户的现有信念,研究人员们正在探讨如何最好地解决这些问题。
除了出错和误导之外,通过让 AI 模型访问网络的方法训练,为该研究引入了新的风险。对此 OpenAI 表示人工智能的浏览环境还不是完全的网络访问,是通过模型将查询请求发送到 Microsoft Bing Web Search API 并关联网络上已有链接实现的,这可能会产生副作用。
OpenAI 表示,根据对 GPT-3 的已有经验,该模型似乎不足以危险地利用这些与外界互联的方式。然而,风险会随着模型能力的增加而增加,研究人员正在努力建立针对它们的内部保护措施。
OpenAI 认为,人类的反馈和 Web 浏览器等工具为实现稳定可信,真正通用的 AI 系统找到了一条有希望的途径。尽管目前的语言大模型还面临很多未知和挑战,但人们在这个方向上仍然取得了重大进展。
https://openai.com/blog/improving-factual-accuracy/
![]()
点击阅读原文,了解更多详情
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com