2019深度学习语音合成指南

还记得我们前几天发出文章《百度超谷歌跃升全球第二,硬核语音技术成抢夺智能音箱“C位”的王牌》吗?本篇文章我们将讲述 2019年深度学习语音合成的一些进展,其中有多篇工作来自百度研究院或百度硅谷人工智能研究院。
翻译 | 栗 峰
编辑 | 唐 里
人工合成人类语音被称为语音合成。这种基于机器学习的技术适用于文本转换语音(text-to-speech)、音乐生成、语音生成、语音支持设备、导航系统以及为视障人士提供无障碍服务。
在这篇文章中,我们将研究基于深度学习而进行的研究或模型框架。
在我们正式开始之前,我们需要简要概述一些特定的、传统的语音合成策略:拼接和参数化。
拼接方法,需要使用大型数据库中的语音来拼接生成新的可听语音。在需要不同语音风格的情况下,必须使用新的音频数据库,这极大的限制了这种方法的可扩展性。
参数化方法则是用一条记录下的人的声音以及一个含参函数,通过调节函数参数来改变语音。
这两种方法代表了传统的语音合成方法。现在让我们来看看使用深度学习的新方法。为了探索当前流行的语音合成方法,我们研究了这些:
WaveNet: 原始音频生成模型
Tacotron:端到端的语音合成
Deep Voice 1: 实时神经文本语音转换
Deep Voice 2: 多说话人神经文本语音转换
Deep Voice 3: 带有卷积序列学习的尺度文本语音转换
Parallel WaveNet: 快速高保真语音合成
利用小样本的神经网络语音克隆
VoiceLoop: 通过语音循环进行语音拟合与合成
利用梅尔图谱预测上的条件WaveNet进行自然TTS合成
WaveNet: 原始音频生成模型
文章链接: https://arxiv.org/abs/1609.03499
这篇文章的作者来自谷歌。他们提出了一种能产生原始音频波的神经网络。他们的模型是完全概率的和自回归的,在英语和汉语的text-to-speech上都取得了最先进的结果。

图1
WaveNET是基于PixelCNN的音频生成模型,它能够产生类似于人类发出的声音。

图2
在这个生成模型中,每个音频样本都以先前的音频样本为条件。条件概率用一组卷积层来建模。这个网络没有池化层,模型的输出与输入具有相同的时间维数。
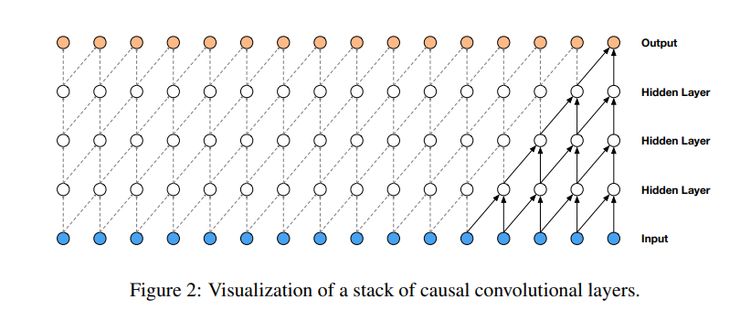
图3
在模型架构中使用临时卷积可以确保模型不会违反数据建模的顺序。在该模型中,每个预测语音样本被反馈到网络上用来帮助预测下一个语音样本。由于临时卷积没有周期性连接,因此它们比RNN训练地更快。
使用临时卷积的主要挑战之一是,它们需要很多层来增加感受野。为了解决这一难题,作者使用了加宽的卷积。加宽的卷积使只有几层的网络能有更大的感受野。模型使用了Softmax分布对各个音频样本的条件分布建模。
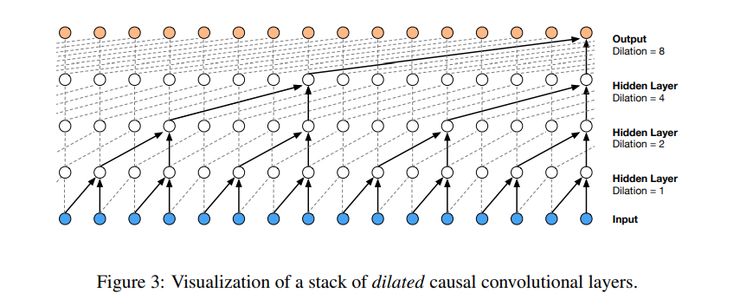
图4
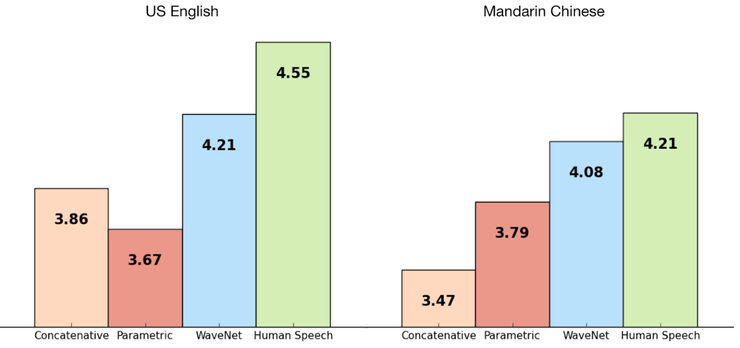
这个模型在多人情景的语音生成、文本到语音的转换、音乐音频建模等方面进行了评估。测试中使用的是平均意见评分(MOS),MOS可以评测声音的质量,本质上就是一个人对声音质量的评价一样。它有1到5之间的数字,其中5表示质量最好。
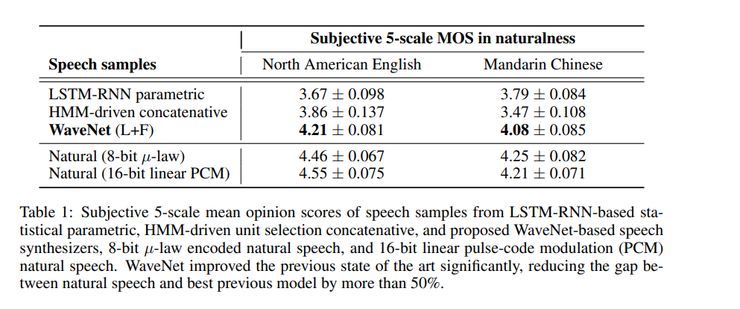
图5
下图显示了1-5级waveNet的语音质量
Tacotron: 端到端的语音合成
文章链接:https://arxiv.org/abs/1703.10135
这篇文章的作者来自谷歌。Tacotron是一种端到端的生成性文本转化语音的模型,可直接从文本和音频对合形成语音。Tacotron在美式英语上获得3.82分的平均得分。Tacotron是在帧级生成语音,因此比样本级自回归的方法更快。
这个模型是在音频和文本对上进行的训练,因此它可以非常方便地应用到新的数据集上。Tacotron是一个seq2seq模型,该模型包括一个编码器、一个基于注意力的解码器以及一个后端处理网络(post-processing net)。如下框架图所示,该模型输入字符,输出原始谱图。然后把这个谱图转换成波形图。

图7
下图显示了CBHG模块的结构。它由1-D卷积滤波器,highway networks和双向GRU(Gated Recurrent Unit)组成。
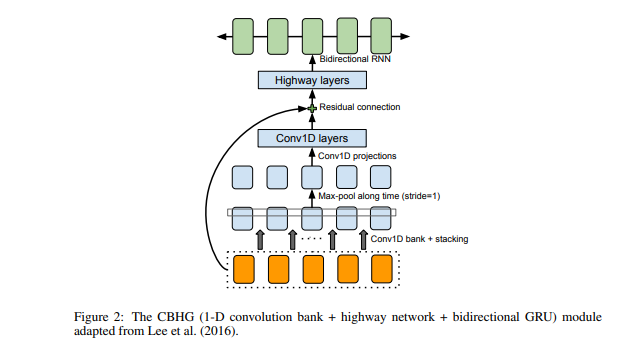
图8
将字符序列输入编码器,编码器将提取出文本的顺序表示。每个字符被表示为一个独热向量嵌入到连续向量中。然后加入非线性变换,再然后加上一个dropout,以减少过度拟合。这在本质上减少了单词的发音错误。
模型所用的解码器是基于内容注意力的tanh解码器。然后使用Griffin-Lim算法生成波形图。该模型使用的超参数如下所示。

图9
下图显示了与其他替代方案相比,Tacotron的性能优势。
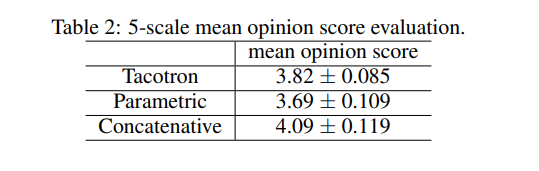
图10
Deep Voice 1: 实时神经文本到语音合成
文章链接:https://arxiv.org/abs/1702.07825
这篇文章的作者来自百度硅谷人工智能实验室。Deep Voice是一个利用深度神经网络开发的文本到语音的系统.
它有五个重要的组成模块:
定位音素边界的分割模型(基于使用连接时间分类(CTC)损失函数的深度神经网络);
字母到音素的转换模型(字素到音素是在一定规则下产生单词发音的过程);
音素持续时间预测模型;
基频预测模型;
音频合成模型(一个具有更少参数的WaveNet变体)。
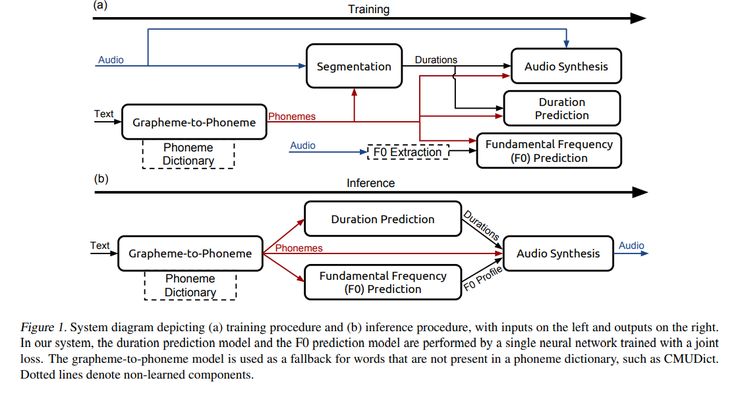
图11
字母到音素模型将英文字符转换为音素。分割模型识别每个音素在音频文件中开始和结束的位置。音素持续时间模型预测音素序列中每个音素的持续时间。
基频模型预测音素是否发声。音频合成模型则综合了字母到音素转换模型、音素持续时间模型、基频预测模型等的输出进行音频合成。
以下是它与其他模型的对比情况
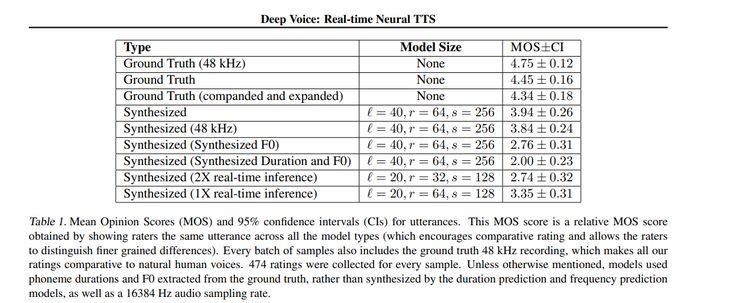
Deep Voice 2: 多说话人神经文本语音转换
文章链接:https://arxiv.org/abs/1705.08947
这篇文章是百度硅谷人工智能实验室在Deep Voice上的二次迭代。他们介绍了一种利用低维可训练说话人嵌入来增强神经文本到语音的方法,这可以从单个模型产生不同的声音。
该模型与DeepVoice 1有类似的流水线,但它在音频质量上却有显著的提高。该模型能够从每个说话人不到半个小时的语音数据中学习数百种独特的声音。
作者还介绍了一种基于WaveNet的声谱到音频的神经声码器,并将其与Taco tron结合,代替Griffin-Lim音频生成。这篇文章的重点是处理多个说话人而每个说话人的数据有非常少的情况。模型的架构类似于Deep Voice 1,训练过程如下图所示。
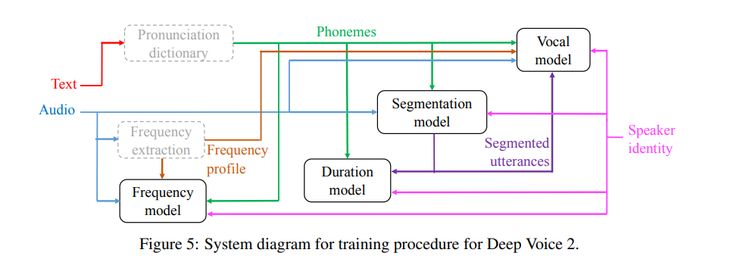
Deep Voice 2和Deep Voice 1之间的主要区别在于音素持续时间模型和频率模型的分离。Deep Voice 1有一个用于联合预测音素持续时间和频率曲线的单一模型; 而在Deep Voice 2中,则先预测音素持续时间,然后将它们用作频率模型的输入。
Deep Voice 2中的分割模型使用一种卷积递归结构(采用连接时间分类(CTC)损失函数)对音素对进行分类。Deep Voice 2的主要修改是在卷积层中添加了大量的归一化和残余连接。它的发声模型是基于WaveNet架构的。
从多个说话人合成语音,主要通过用每个说话人的单个低维级说话人嵌入向量增强每个模型来完成的。说话人之间的权重分配,则是通过将与说话人相关的参数存储在非常低维的矢量中来实现。
递归神经网络(RNN)的初始状态由说话人声音的嵌入产生。采用均匀分布的方法随机初始化说话人声音的嵌入,并用反向传播对其进行联合训练。说话人声音的嵌入包含在模型的多个部分中,以确保能考虑到每个说话人的声音特点。
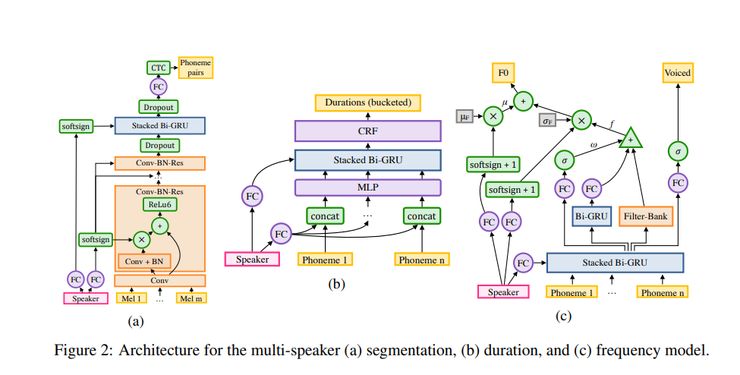
图14
接下来让我们看看与其他模型相比它的性能如何
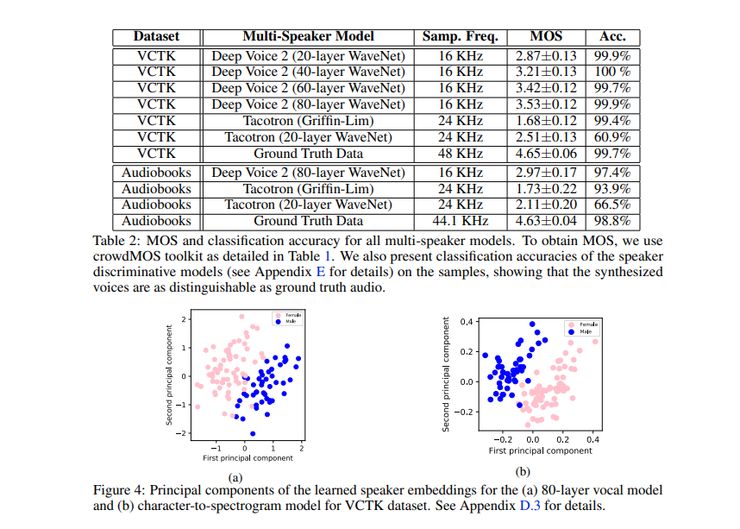
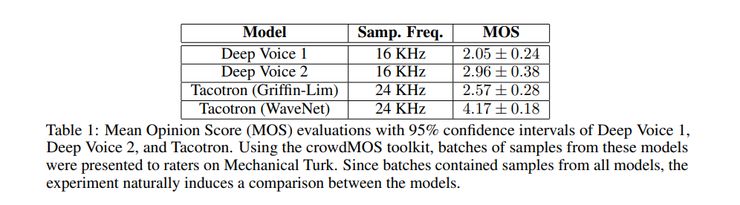
图15
Deep Voice 3: 利用卷积序列学习将文本转换为语音
文章链接:https://arxiv.org/abs/1710.07654
作者提出了一种全卷积字符到谱图的框架,可以实现完全并行计算。该框架是基于注意力的序列到序列模型。这个模型在LibriSpeech ASR数据集上进行训练。
这个模型的结构能够将字符、音素、重音等文本特征转换成不同的声码器参数,其中包括Mel波段光谱图、线性比例对数幅度谱图、基频谱图、谱包络图和非周期性参数。然后将这些声码器参数作为音频波形合成模型的输入。
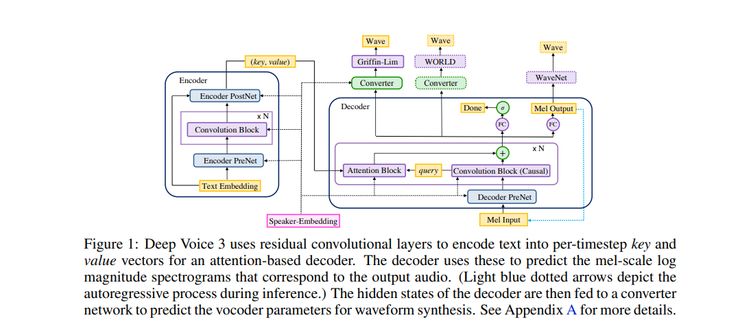
模型的结构由以下几个部分组成:
编码器:一种全卷积编码器,可将文本特征转换为内部学习表示。
解码器:一种全卷积因果解码器,以自回归的方式解码学习表示。
转换器:一种全卷积后处理网络,可预测最终的声码器参数。
对于文本预处理,作者的处理方式包括:大写文本输入字符,删除标点符号,以句号或问号结束每句话,并用表示停顿长度的特殊字符替换空格。
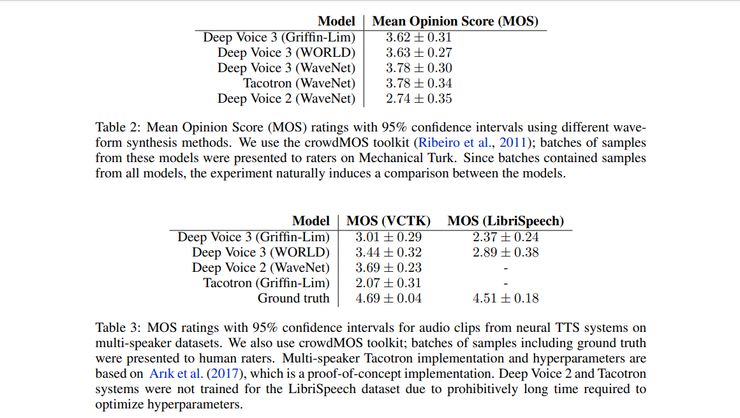
下图是该模型与其他替代模型的性能比较。
Parallel WaveNet: 快速高保真语音合成
文章链接:https://arxiv.org/abs/1711.10433
这篇文章的作者来自谷歌。他们引入了一种叫做概率密度蒸馏的方法,它从一个训练过的WaveNet中训练一个并行前馈网络。该方法是通过结合逆自回归流(IAFS)和波形网(WaveNet)的最佳特征构建的。这些特征代表了WaveNet的有效训练和IAF网络的有效采样。
为了进行有效训练,作者使用一个已经训练过的WaveNet作为“老师”,并行WaveNet‘学生’向其学习。目的是为了让学生从老师那里学到的分布中匹配自己样本的概率。

作者还提出了额外的损失函数,以指导学生生成高质量的音频流:
功率损失函数:确保使用语音不同频带的功率,就像人在说话一样。
感知损失函数:针对这种损失函数,作者尝试了特征重构损失函数(分类器中特征图之间的欧氏距离)和风格损失函数(Gram矩阵之间的欧氏距离)。他们发现风格损失函数会产生更好的效果。
无论条件向量如何,对比度损失会惩罚有高可能性的波形。
下图显示了这个模型的性能:
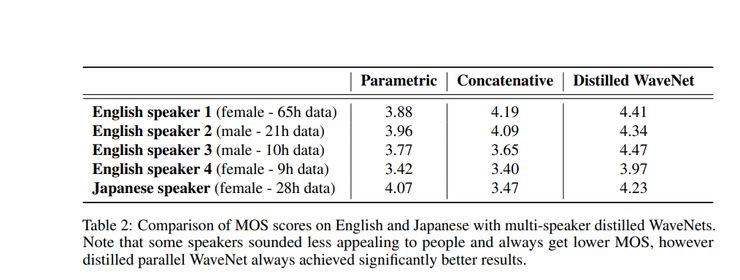
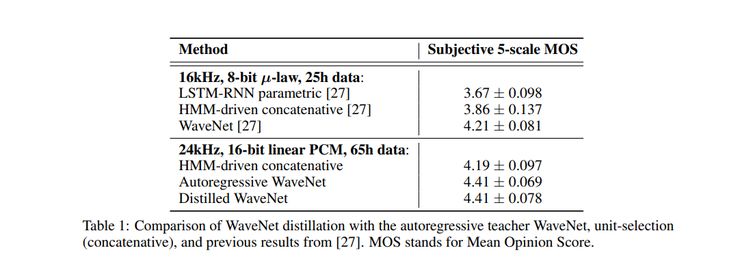
图19
利用小样本的神经网络语音克隆
文章链接:https://arxiv.org/abs/1802.06006v3
这篇文章的作者来自百度研究院。他们引入了一个神经语音克隆系统,它可以通过学习从少量音频样本合成一个人的声音。
系统使用的两种方法是说话人自适应和说话人编码。说话人自适应是通过对多个说话人的声音生成模型进行微调来实现的,而说话人编码则是通过训练一个单独的模型来直接推断一个新的嵌入到多个说话人语音生成模型。
本文采用Deep Voice 3作为多说话人模型的基线。所谓声音克隆,即提取一个说话人的声音特征,并根据这些特征来生成给定的文本所对应的音频。
生成音频的性能指标决定于语音的自然度和说话人声音的相似度。作者提出了一种说话人编码方法,该方法能够从未曾见过的说话人音频样本中预测说话人声音嵌入。
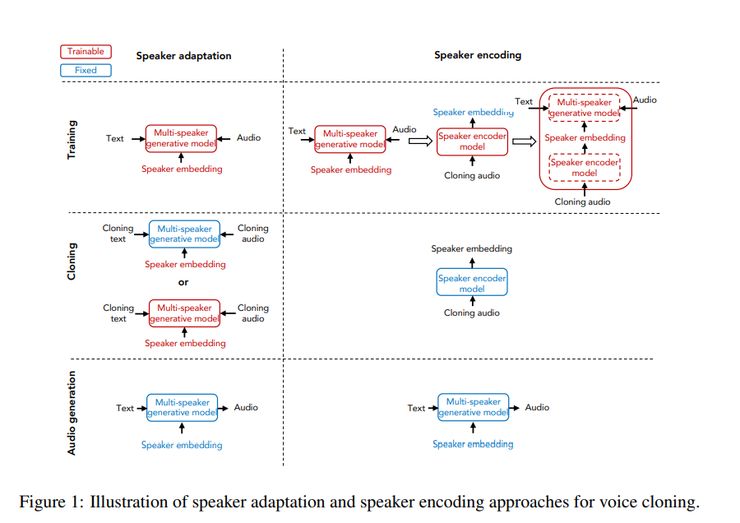
图20
下面是声音克隆的性能:
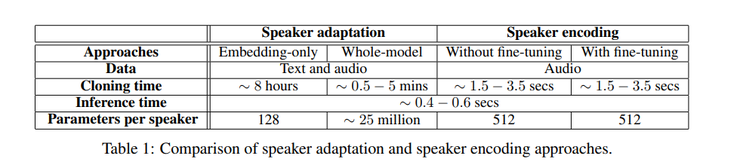
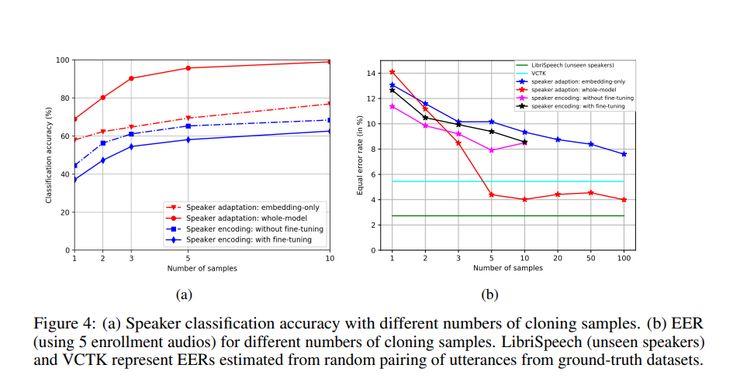
图22
VoiceLoop: 通过语音循环进行语音拟合与合成
文章链接:https://arxiv.org/abs/1707.06588
这篇文章的作者来自Facebook AI研究院。他们引入了一种神经文本到语音(TTS)技术,可以将文本从野外采集的声音转换为语音。
VoiceLoop的灵感来源于一种称为语音循环的工作记忆模型,它能在短时间内保存语言信息。它由两部分组成,其一是一个不断被替换的语音存储(phonological store),其二是一个在语音存储中保持长期表达(longer-term representations)的预演过程。
Voiceloop将移动缓冲区视作矩阵,从而来构造语音存储。句子表示为音素列表。然后从每个音素解码一个短向量。通过对音素的编码进行加权并在每个时间点对它们求和来生成当前的上下文向量。
使VoiceLoop脱颖而出的一些属性包括:使用内存缓冲区而不是传统的RNN,所有进程之间的内存共享,以及使用浅层、全连接的网络进行所有计算。

下图显示了模型与其他替代方案相比的性能表现
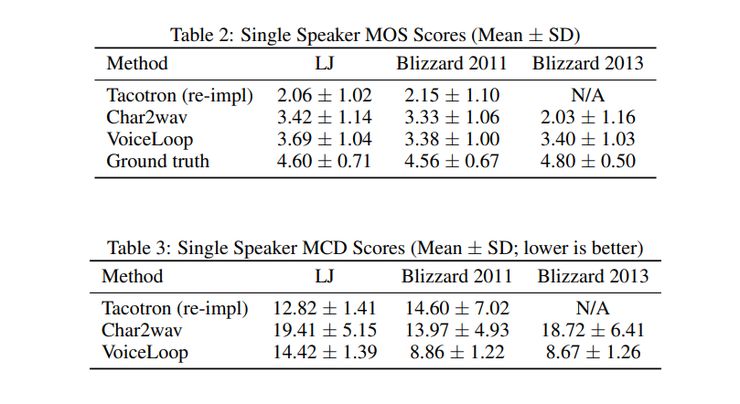

图25
利用梅尔图谱预测上的条件WaveNet进行自然TTS合成
文章链接:https://arxiv.org/abs/1712.05884
作者来自谷歌和加州大学伯克利分校。他们引入了Tacotron 2,这是一种用于文本语音合成的神经网络架构。
它由一个循环的的序列到序列特征预测网络组成,该网络将字符嵌入到梅尔标度图谱中。然后是一个修改后的WaveNet模型,这个模型充当声码器,利用频谱图来合成时域波。模型的平均意见评分(MOS)为4.53分。

图26
这个模型结合了Tacconon和WaveNet的最佳特点。下面是它与其他模型的性能对比:
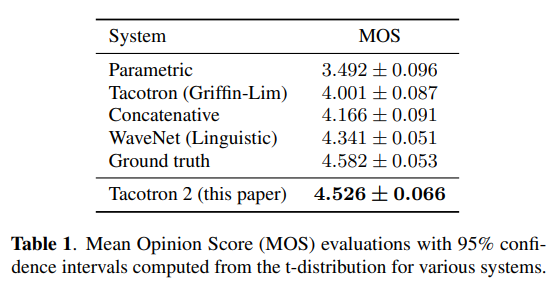
图27
结论:
现在的语音合成技术发展很快,我们希望能够尽快追赶上最前沿的研究。以上这几篇文章是当前语音合成领域最重要的进展代表,论文、以及其代码实现都可在网上找到,期待你能去下载下来进行测试,并能够获得期望的结果。
让我们一起创造一个丰富多彩的语音世界。
原文链接:
https://heartbeat.fritz.ai/a-2019-guide-to-speech-synthesis-with-deep-learning-630afcafb9dd
点击 阅读原文 查看 2019语义分割指南


