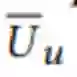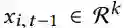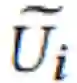点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
本文转载自:机器之心
荷兰、瑞士两位学者(其中一位是教授)的SIGIR 2019论文被发现抄袭,部分内容与RecSys 2018一篇论文高度相似,只有个别用词出现改动。
今日,有Reddit网友爆出,入选SIGIR 2019的论文《Adversarial Training for Review-Based Recommendations》与RecSys 2018上的一篇论文《Why I like it: Multi-task Learning for Recommendation and Explanation》惊人相似。
起初,发帖者以为这仅仅是一个巧合,maybe 这只是因为两组研究人员提出了同样的问题、开展了相同的研究,然后,提出了相同的解决方案。
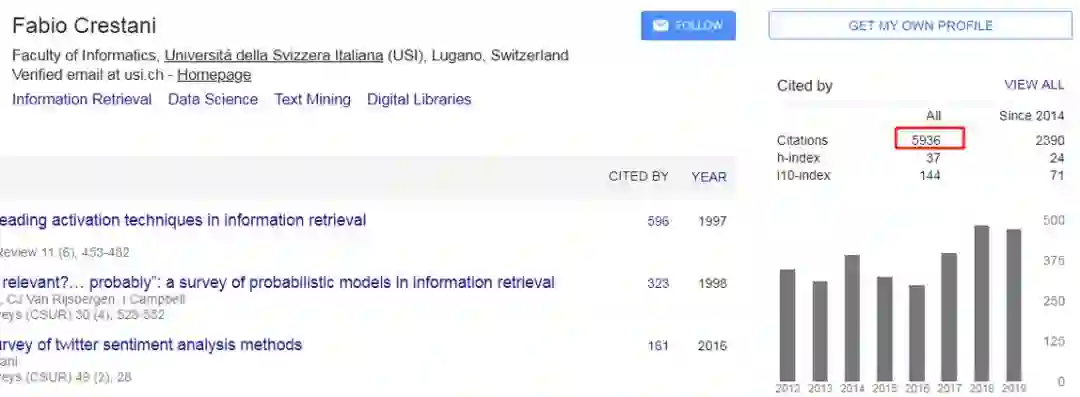
被质疑抄袭他人论文的两位作者分别来自荷兰和瑞士的高校。其中,Dimitrios Rafailidis 是荷兰马斯特里赫特大学的助理教授,Fabio Crestani 则来自瑞士提契诺大学。两个人是老搭档,合著过很多篇论文。Fabio Crestani 在 Google Scholar 上的被引用量甚至高达 5936。
![]()
他们的这篇论文被 SIGIR 会议接收。SIGIR 会议的全称是「Special Interest Group on Information Retrieval」,是一个展示信息检索领域中各种新技术和新成果的重要国际论坛,在《中国计算机学会(CCF)推荐国际学术会议》列表中属于 A 类会议。
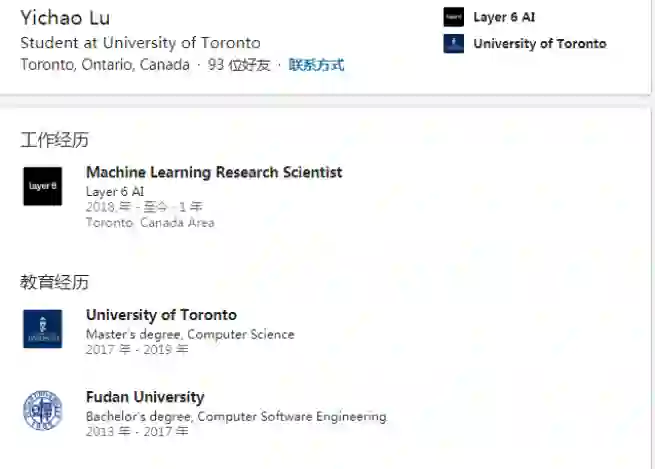
而这次抄袭事件的「原版」论文来自推荐系统顶会 ACM RecSys 2018,其中一作 Yichao Lu 是华人,目前在 AI 公司 Lyaer 6 AI 担任机器学习研究科学家,本科就读于复旦大学,硕士就读于多伦多大学。另两位作者 Ruihai Dong 与 Barry Smyth 则来自都柏林大学。
![]()
说回来,SIGIR 2019 那篇论文中的模型像是从 RecSys 2018 那篇中复制过来的一样,让我们来对比一下:
首先,这两篇论文都在矩阵分解框架的基础上使用了对抗序列到序列的学习模型。其次,在生成器和鉴别器的部分,两篇论文都使用了 GRU 生成器和 CNN 鉴别器。优化方法也相同,都是两个部分之前交替优化。最后,两篇论文所使用的符号和公式也极其相似……
Fine,鉴于「对抗训练」是一种当下很流行的操作,所以不能因此下结论。但是,SIGIR 2019 论文和 RecSys 2018 两篇论文的文字重合之处证明了一切:
在论文写作中,很难想象一个人会写出与他人一字不差的语句,除非是抄袭的。
「解码器利用了一个单一的 GRU,迭代地逐词生成评论。具体来说,在时间步 t 上,GRU 首先将之前时间步的输出表征 z_ut-1 映射为 k 维向量 y_ut-1」,并将其与![]() 连接在一起,以生成一个新的向量 y_ut。最后,将 y_ut 输入 GRU,得到隐藏表征 h_t。接下来,将 h_t 与输出投影矩阵相乘,并通过 softmax 遍历文档词汇表中的所有单词来表示每个单词的概率。时间步 t 上的输出词 z_ut 从 softmax 给出的多项式分布中采样得到。」
连接在一起,以生成一个新的向量 y_ut。最后,将 y_ut 输入 GRU,得到隐藏表征 h_t。接下来,将 h_t 与输出投影矩阵相乘,并通过 softmax 遍历文档词汇表中的所有单词来表示每个单词的概率。时间步 t 上的输出词 z_ut 从 softmax 给出的多项式分布中采样得到。」
「用户评论解码器利用了一个单独的 GRU,迭代地逐词生成评论。在时间步 t 上,解码器 GRU 首先将前一个时间步上的输出词 y_i, t-1 嵌入到相应的词向量![]() ,然后将其与用户文本特征向量
,然后将其与用户文本特征向量![]() 连接在一起。连接后的向量被用作解码器 GRU 的输入,以获取隐藏激活 h_t。接下来,将隐藏激活与输出投影矩阵相乘,并通过 softmax 遍历文档词汇表中的所有单词来表示当前语境的每个单词的概率。时间步 t 上的输出词 y_i, t 从从 softmax 给出的多项式分布中采样得到」。
连接在一起。连接后的向量被用作解码器 GRU 的输入,以获取隐藏激活 h_t。接下来,将隐藏激活与输出投影矩阵相乘,并通过 softmax 遍历文档词汇表中的所有单词来表示当前语境的每个单词的概率。时间步 t 上的输出词 y_i, t 从从 softmax 给出的多项式分布中采样得到」。
在这个例子中,SIGIR 2019 论文的作者替换了论文中的个别短语,以使两篇论文看起来没那么像。然而,发帖者认为,两篇论文之间的相似性还是可以表明,SIGIR 2019 论文的作者在写自己的论文之前肯定读过那篇 RecSys 2018 论文。
「评论 r 的每个单词都被映射成对应的词向量,然后与特定于用户的向量连在一起。需要注意的是,在 2.3 节的对抗训练中,特定于用户的向量与鉴别器的参数 D_*θ*是一起学习的。接下来,用一个卷积层、最大池化层和一个全连接映射层来处理连接后的向量表征。CNN 的最终输出是一个 sigmoid 函数,它会将概率归一化为 [0, 1] 区间内的数字,表示候选评论由用户 u 撰写的概率。」
「首先,将评论中的每个词映射到相应的词向量,然后将其与一个特定于用户、表明用户信息的向量连接在一起。特定于用户的向量与训练中的其他参数是一起学习的。接下来,用一个卷积层、最大池化层和一个全连接层来处理连接后的向量表征。最终的输出单元是 sigmoid 非线性,它会将概率压缩到 [0, 1] 区间内的数字。」
我们注意到,这两段表述中有一个句子几乎完全一样(接下来,用一个卷积层……来处理连接后的向量表征)。
另外,发帖者认为,将特定于用户的向量连接到评论中的每个词向量是一个非常不直观的想法。ta 表示,来自不同研究团队的观点细节不可能如此相似。如果 ta 是作者,ta 会将特定于用户的向量连接到最后那个投影层之前的层上,因为这样能节省计算开销,泛化性能也更好。
在整理完这些重叠之处之后,发帖者陷入沮丧。ta 的结论是:这篇论文绝对不应该在这样一个顶会上发表。而且此时此刻,着急的应该不只是论文作者,SIGIR 2019 的论文评审恐怕也罪责难逃了。
在评论区,众人主张将此事告知 SIGIR 19 会议组织·,也有人认为二位抄袭者的学术生涯就此结束了。
两位作者都是知名学府的学者,他们应该知道,剽窃在学术界是件大事。
对于科学研究来说,观点、方法的剽窃已经是非常严重的不端行为,更何况出现了「复制+粘贴」这样的情况。
前段时间因为论文抄袭而「臭名昭著」的 Siraj Raval,也是活生生的例子。因为被人扒抄袭,不仅被骂得很惨,还被迫与自己创办的 AI 学院断绝关系。
这件事的后续,恐怕会引发更多关注,不知情况是否还会发生反转。
参考链接:
https://www.reddit.com/r/MachineLearning/comments/dq82x7/discussion_a_questionable_sigir_2019_paper/
重磅!CVer学术交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪&去雾&去雨等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)
![]()
▲长按加群
![]()
▲长按关注我们
麻烦给我一个在看!