被指责抄袭的作者亲自下场分辨,却被反驳「漏洞百出」,顶会抄顶会的故事还没有最终定论。
上周,一位 Reddit 网友曝出,一篇 SIGIR 2019 的论文疑似抄袭,论文中的许多段落与 RecSys 2018 的一篇论文高度相似,只是措辞略有不同,但并没有声明引用后者。被质疑抄袭的两位作者分别来自荷兰和瑞士的高校,其中一位还是教授。这一事件在 Reddit 上引发围观。原贴发酵数日之后,两位被指责「抄袭」的作者终于现身回应。然而,他们的回应似乎并不能让发帖者信服……
在原帖中,发帖者列出了五条可以证明 SIGIR 2019 论文抄袭 RecSys 2018 论文的证据:
两篇文章都在矩阵分解框架的基础上使用了序列到序列的对抗学习模型;
生成器和鉴别器部分,两篇论文都将 GRU 和 CNN 分别作为生成器和鉴别器;
优化方法相同,即在两个部分之间交替进行优化;
评估是相同的,即都是通过评估 MSE 的推荐性能和鉴别器的准确性来表明生成器已学会生成相关评论;
两篇论文使用的符号和公式看起来非常相似。
在最新的回帖中,SIGIR 2019 论文作者针对这些「证据」逐条进行了反驳。
对于第 1 条证据,作者表示,事实上,这两篇论文都对一篇 WWW『18 论文《Co-Evolutionary Recommendation Model: Mutual Learning between Ratings and Reviews》进行了拓展(这篇的作者也是 RecSys 2018 论文的作者)。
SIGIR 2019 论文的作者在研究中引用了 WWW‘18 的论文(但很奇怪的是,那篇 RecSys 18 论文并没有引用他们自己之前的这项工作)。
针对第 2 条指控,作者解释称,两篇论文都是基于对抗训练,WWW『18 的论文也是如此。
在句子结构中,GRU / CNN 都是相当普遍的序列到序列学习策略。
实际上,其他许多论文也都将 GRU 和 CNN 用于文本表示/文档分类的序列到序列学习。
所以两篇论文在生成器和鉴别器部分都遵循类似的策略是说得通的。
对于第 3 条证据,作者反驳道,这么说并不完全正确。
「我们的论文中确实采用了与 RecSys2018 论文相同的交替优化方法,但这种方法已经相当广泛了,之前我们在 ECML/PKDD2016 的一篇论文中也使用了这种方法。
另一方面,为了建模用户偏好,我们使用了非负矩阵分解,而不是 RecSys 论文中使用的概率矩阵分解。
这里存在实质性差别。
」
对于第 4 条的评估方法,作者表示,「这点不准确:
评估是不同的。
尽管 MSE 是用于评级预测的广泛使用的度量,但在我们的论文中,我们评估了自己的方法在四个与 RecSys 论文不同的数据集上的性能。
请注意,我们在实验部分引用了 WWW'18 论文,已经明确说明了使用相同的评估方案(其他基于评论的推荐系统的研究也用到了此方案)。
除了在 RecSys2018 论文以及其他基于评论的推荐系统的论文中广泛使用的 PMF 和 HFT 两种基线策略之外,我们还针对 DeepCoNN、TNET 和 WWW'18 论文提出的 TARMF 方法评估了我们的方法。
在我们的实验中,我们还评估了 RecSys2018 论文中未报告的潜在因素数量的影响。
这些都是有意义的差异所在。
」
对于第 5 条提到的公式和符号问题,作者解释称,「SIGIR2019 和 RecSys2018 的论文都是基于对抗训练,就像 WWW‘18 那篇论文一样,因此这些符号/公式看起来很像。
然而,除了使用不同的矩阵分解方法之外,对抗训练过程也存在一些差异。
我们的论文中使用了 RecGAN 2018 中提到的策略,如引文 [2] 所示:
我们还用到了 IRGAN 2017 的策略来减少训练中的方差,如引文 [18] 所示:
RecSys‘18 那篇论文采用了 2017 预印版论文中的策略,也就是他们的引文 [26]:
除了这五条「证据」之外,原贴作者还给出了三个示例,证明两篇论文的某些段落在措辞上有多么相似。
为了看起来更加直观,有位 Reddit 网友将这三个示例进行了标注。
对此,作者表示,他们自己对这一相似度也感到非常吃惊。
对于第一个示例,他们解释称,由于他们的论文只描述了 DeepCoNN 模型的工作原理,所以两个短句看起来非常相似。
![]()
原帖中的第一个示例。
上:
SIGIR 2019 论文第 1 部分。
下:
RecSys 2018 论文第 2 部分。
至于另外两个示例,作者解释道,由于两个模型都是基于 WWW‘18 论文,而且都用到了基于双向 GRU 和 CNN 的序列到序列学习,所以术语是一样的。
例如,使用 GRU/CNN 处理文档分类的序列到序列学习论文用到了相同的术语,如「max-pooling」、「fully connected layer」、「concatenate word embeddings」、「the probability of each word」。
因此,这些词在这种语境下非常常见。
因此,后两个例子看起来相似是说得通的。
最后,他们还解释了为什么没有引用那篇 RecSys 的论文。
作者表示,尽管他们看过那篇 RecSys‘18 论文的进展(他们的论文发表于 SIGIR 论文 deadlin 之前的三个月),但在搜索基于评论和深度学习的推荐系统的论文时,那篇论文并没有引起他们的注意。
「那篇 RecSys 论文的标题是关于多任务学习和可解释推荐的,与基于评论和深度学习的推荐无关。
此外,那篇论文的摘要和关键词不会和我们的方法产生直接联系。
而且,请注意,那篇论文没有引用 WWW'18 的论文。
因此,从引用 WWW‘18 论文的工作中找到那篇论文也是不可能的。
」
至此,第一回合 battle 宣告结束。
但看到这些解释,原贴的楼主似乎并不买账。
原贴楼主继续在帖子下回复道,「我很欣赏你们能够出来自证清白,但在我看来,你们的回答简直漏洞百出」。
楼主注意到,作者在回应中提到了两次「SIGIR2019 和 RecSys2018 的论文都是基于对抗训练,WWW『18 的论文也是如此」。
于是,他去读了这篇论文,但读过之后,他并没有发现任何显示其基于对抗学习的地方。
所以,他认为作者在混淆概念以愚弄读者;
针对作者所说的「我们的论文中使用了 RecGAN 2018 中提到的策略,如引文 [2] 所示;
我们还用到了 IRGAN 2017 的策略来减少训练中的方差,如引文 [18] 所示」,楼主喊话称,「请明确说明你在论文中用来减少训练方差的策略并非 RecSys‘18 论文中的策略。
你声称两篇论文所采用的策略具有『实质性差别』,但我只看到了参考文献是不同的,理论基础几乎完全一样。
请说明这一点。
」
另外,作者声称「就对用户偏好进行建模而言,我们使用的是非负矩阵分解,而 RecSys 论文使用的是概率矩阵分解」。
但楼主认为,概率矩阵分解属于非负矩阵分解的一类。
此外,楼主还注意到,SIGIR2019 论文最终得出的公式 [5] 与 RecSys'18 论文中公式 [10] 几乎完全相同,所以他希望作者明确说明存在哪些「实质性差别」。
![]() SIGIR 2019 论文中的公式 [5]。
SIGIR 2019 论文中的公式 [5]。
![]() RecSys'18 论文中的公式 [10]。
RecSys'18 论文中的公式 [10]。
最后,关于措辞的问题,楼主指出,SIGIR2019 论文不仅复制了描述 DeepCoNN 模型的语句,而且还复制了描述 TNet 模型的语句。
难道这也是巧合吗?
此外,对于作者所说的「论文中使用的术语在文献中很常见,所以两段以上相似的内容也是可以理解的」,楼主也无法信服。
他表示,「请至少再找一个例子说明这种『极度相似性』的语句会出现在同行评审的发表论文中。
」
对于楼主的新一波质疑,SIGIR2019 作者显得有些疲倦。
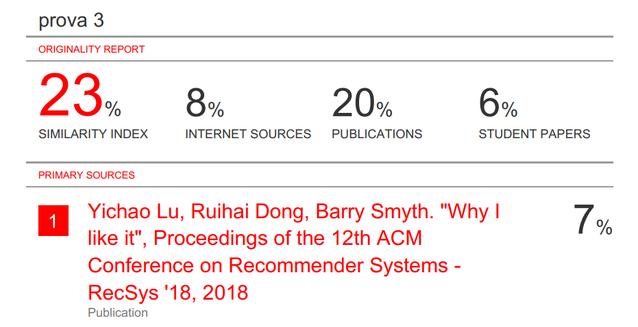
为了增加说服力,他们索性自己去查了重并晒出了查重报告。
但没想到的是,就连这份查重报告也受到了质疑。
![]()
查重报告显示,这篇 SIGIR19 论文与 RecSys18 论文之间的相似度为 7%。
作者表示,根据软件公司的说法,24% 及以下的相似度都是很低的(参见:
https://help.turnitin.com/feedback-studio/turnitin-website/student/the-similarity-report/interpreting-the-similarity-report.htm),所以 7% 的相似度真的是很低了。
另外,对于报告第一页显示的五行重复句子,作者表示,这里是在讨论相关工作,所提到的文献都有标注,他们不应该因此而被钉死在十字架上。
他们没有声明这里是自己原创的。
撰写论文初稿的第一作者也表示论文是他自己写的。
![]()
原贴楼主认为,论文作者使用的软件是为了检查学生论文剽窃而设计的,学生论文与其他材料有一定程度的重叠是可以接受的,但一个经过同行评审的论文有这种程度的重叠是不可接受的。
而且楼主认为,作者好像比错了数据。
他们只提到自己的论文与 RecSys18 论文的相似度是 7%,远低于 24% 的分界线,但实际上应该看的数字是该论文与其他材料的总体相似度,而这一数字高达 23%,只比 24% 低一点。
除了这位楼主之外,一位用户名为 eamonnkeogh 的网友也对查重报告提出了质疑,认为 7% 的相似度并不足以证明作者的清白,因为真正的抄袭者有各种办法降低查重率。
经过两轮的 battle,质疑和被质疑者并没有达成共识,但这件事已经惊动了 ACM SIGIR 主席、SIGIR 大会指导委员会主席 Ben Carterette。
他在帖子下面留言道,「我们已经注意到了这个情况。
ACM 有明确的规定和程序来报告和判定可能的剽窃事件。
众所周知,这是非常严重的指控,最好由具备经验和资质的中立第三方来裁决。
如果你想正式投诉,你可以投诉。
」
另外,他还给出了 ACM 关于剽窃规定的文件链接。
该文件显示,ACM 将剽窃行为分为以下几种:
逐字抄写、几乎逐字抄写或有意意译他人作品的某些部分;
抄袭他人作品中不常见的方程式、表格、图表、插图、演示文稿或照片等元素,抄袭或故意意译他人句子但不给出适当或完整出处;
一字不差地抄袭他人的部分作品,并给出不正确的出处。
根据抄袭的严重程度,ACM 将抄袭行为分为五级。
其中,最轻的一级只需要写道歉信,然后由 ACM 出更正声明,作品仍有发表的机会。
而对于最严重的剽窃行为,剽窃者不仅需要写道歉信,而且五年之内不得向 ACM 的任何机构投稿。
此外,剽窃的证据将提交 ACM 职业道德委员会作为参考并发送给剽窃者的院长、导师等相关人士。
就目前的情况来看,这篇 SIGIR 论文是否存在抄袭行为还很难得出定论。
在 ACM 给出官方裁决之前,大家可以查看两篇论文自行分析。
SIGIR2019 论文:https://gofile.io/?c=ej2y69
RecSys 2018 论文:https://researchrepository.ucd.ie/bitstream/10197/10892/4/Why%20I%20like%20it%20Multi%20Task%20learning%20for%20recommendation%20and%20Explanation.pdf
reddit 讨论:https://www.reddit.com/r/MachineLearning/comments/dq82x7/discussion_a_questionable_sigir_2019_paper/
查重报告完整版:https://drive.google.com/file/d/18tQXFTJX3FCiAO1hlQqrm9eX0aSC-5mc/view
ACM 关于剽窃的规定:https://www.acm.org/publications/policies/plagiarism-overview
第三届机器之心「Synced Machine Intelligence Awards」年度奖项评选正在进行中。本次评选设置六大奖项,重点关注人工智能公司的产品、应用案例和产业落地情况,基于真实客观的产业表现筛选出最值得关注的企业,为行业带来实际的参考价值。
参选报名日期
:
2019 年 10 月 23 日~2019 年 12 月 15 日
评审期
:
2019 年 12 月 16 日~2019 年 12 月 31 日
![]()




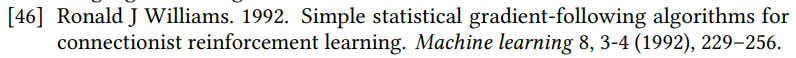


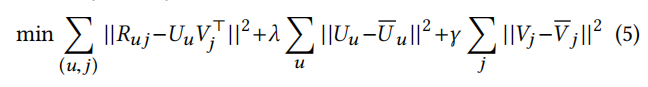 SIGIR 2019 论文中的公式 [5]。
SIGIR 2019 论文中的公式 [5]。
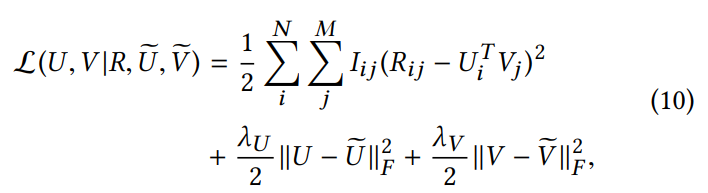 RecSys'18 论文中的公式 [10]。
RecSys'18 论文中的公式 [10]。