基于面部表情的学习困惑自动识别法

| 全文共8260字,建议阅读时间17分钟 |
本文由《开放教育研究》杂志授权发布
作者:江波、李万健、李芷璇、叶韵
摘要
学习情绪是学习者模型的重要内容,如何识别学习者的学习情绪是下一代智能教辅系统的关键技术。困惑是最常见的学习情绪之一,及时识别并解决困惑有助于提高学习效果,然而困惑情绪内隐性较强,识别难度较大。本研究设计了一组基于在线测评的困惑诱导实验,提出了一种基于面部表情的学习困惑自动识别算法。研究人员通过设定不同难度的测试题诱导被试产生困惑情绪,同时利用摄像设备实时捕捉学习者的面部表情,提取面部重要特征点,进而利用机器学习算法进行困惑识别。在实验中,本研究使用逻辑回归、支持向量机、K近邻、决策树、随机森林和深度学习等机器学习算法建立学习困惑自动检测模型,并与被试自我报告确定的困惑标签进行对比。实验结果表明,多数分类算法能有效检测学生的学习困惑,随机森林模型的预测性能最佳,平均准确率为71.18%。本研究所提出的方法可为下一代智能教辅系统的学习者情绪建模提供技术支撑。
关键词:学习困惑;面部表情检测;情感计算;机器学习;人工智能
一、引言
近年来,大量实证研究表明情绪与学习之间存在关联(Valiente et al.,2012)。生物学研究也发现情绪影响学习的分子机制(Hu et al.,2007)。《地平线报告》(2016高等教育版)指出,情感计算可能是未来四五年教育领域的重要技术,这一技术旨在开发像人一样思考的计算机,如利用摄像头捕捉面部表情,并利用算法检测和解释学习交互(Johnson et al.,2016)。学习者在学习过程中出现最频繁的情绪有困惑、投入、沮丧、厌倦等(D’Mello&Graesser,2012)。为了区别人类的六种基本情绪(Ekman et al.,2013),雷曼等(Lehman et al.,2010;Lehman et al.,2008)分析学习者与智能教辅系统交互50小时所经历的情绪,发现困惑是其中最常见的。蒂梅洛(D’Mello,2013)对21项研究分析后发现,困惑在最高频次的15种情绪中排名第二。这些研究共包含1430名学习者在多种不同学习情境进行1058小时互动学习产生的学习情绪。
学习情绪是由学习行为的后果引起的,不同时期情绪会发生转化(D’Mello&Graesser,2012)。学习困惑通常会对学习产生消极影响。例如,在MOOC学习过程中,持续的困惑会增加学生的消极情绪,影响学习成绩,甚至最终导致学生辍学(Yang et al.,2015)。反之,学习困惑及时得到解决,会将情绪过渡到积极状态,学生对问题的回答会趋于正确并得到正面反馈,进而提升教学效果(D'Mello,Person&Lehman,2009;D'Mello et al.,2014)。因此,教育工作者对学习困惑进行有效检测,并提供有效干预,将有助于改进学生的学习表现。
在情感计算中,面部表情是识别情绪的重要途径之一。学生有困惑情绪时,常常伴随有特定的面部表情(Grafsgaard et al.,2011)。早期研究发现,困惑是一种较普遍的不对称表情,特别是皱眉肌的不对称性是识别学习过程中困惑情绪是否出现的有效信号。困惑情绪的面部活动主要在眼部周围,如眼睛缩小,眉毛下降汇聚等(Durso,Geldbach,&Corballis,2012;马惠霞等,2015)。
西尔维娅(Silvia,2010)将困惑归类为“知识情感”,认为这是一'种涉及理解和思考的情感,是一'种元认知信号:反映人们对于正在发生事物的不理解。当学生在学习过程中遇到异常、矛盾或僵局,且不确定如何继续下去时,困惑会随之产生。困惑对学习的主要影响体现在两个方面:一方面,学习者长期处于困惑状态,会造成学习积极性减退,导致学习成绩下降以及课程的保留率降低(Lee et al.,2011)。另一方面,当学生能有效调节自身困惑,或者学习环境提供了足够的脚手架帮助学习者解决困惑时,困惑将产生积极影响。对学生情感的准确理解可能有助于改进情感检测,以及设计增加学习参与度的干预措施(Yang et al.,2015)。
学习困惑的检测方法可分四类:基于文本信息、学习行为、生理信号和面部表情。杨等(2015)使用MOOC论坛文本信息和点击数据自动识别表示困惑的帖子后发现,学生表现或暴露于论坛中的困惑越多,他们继续学习MOOC的可能性越低。斯坦福大学的研究人员利用斯坦福oocpost语料库,训练了一组异构的分类器对论坛发帖内容进行多维度分类,并使用信息检索技术为困惑的帖子推荐对应知识的视频片段(Agrawal et al.,2015)。贝克等(Baker et al.,2012)基于ASSISTments平台的学习行为数据,应用八种数据挖掘算法建立分类模型,自动识别困惑等四种常见学习情绪(Wang,Heffeman&Heffeman,2015)。博特略等(Botelho et al.,2017)使用循环神经网络(RNN)、长短时记忆网络(LSTM)和门口循环单元(GRU)等深度学习算法,实现基于网络学习行为的学习困惑识别。王等(Wang et al.,2013)发现利用EEG信号区分学生观看M00C视频片段是否感到困惑的能力很弱,分类器预测学生困惑的准确率较低(平均为51%至56%),与人类观察的效果相差不大。杜尔索等(Durso et al.,2012)用肌电图监测受试者的面部肌肉(皱眉肌和降口角肌),同时要求被试举手表示困惑,结果发现肌电记录的面部肌肉运动规律与被试自我报告的困惑规律之间存在显著相关;后测中被试做出相应的困惑表情,该困惑表情与肌电图检测的结果一致。
然而,上述四种方法存在诸多局限。基于文本信息的检测方法仅针对留下评论记录的学习者,无法对不参与评论的学生有效检测;基于学习行为的识别方法需要针对不同学习系统开发专用的细粒度学习行为采集系统;利用生理信号检测学习困惑需要学习者佩戴采集脑电信号的专业仪器设备,这些设备通常较为昂贵且需要在特定实验环境下才能实施。由于电脑和移动设备的摄像头非常普及,且硬件设备不贵,近年来基于面部表情的学习情绪识别广受关注(Durso et al.,2012;Whitehill et al.,2014;Grafsgaard et al.,2011)。
目前,基于面部表情的学习情绪识别研究主要集中关注投入(Engagement),涉及困惑的研究相对较少。同时,这类研究主要集中在国外,国内相关研究刚刚起步,且不同人种的面部特征存在差异,国际同行提出的模型不一定适用于我国的教育情境。为解决以上问题,本研究设计了一组基于在线测评的困惑诱导实验,提出了一种基于面部表情的学习困惑自动识别算法,并通过设定不同难度的测试题诱导被试产生困惑情绪,同时利用摄像头实时捕捉学生的面部表情,提取面部重要特征点,进而利用机器学习算法进行表情识别。本研究提出基于面部表情的学习困惑识别方法,应用逻辑回归、支持向量机、K近邻、决策树、随机森林和深度前馈神经网络等常见的机器学习算法建立分类模型,自动检测学习困惑。
二、研究方法
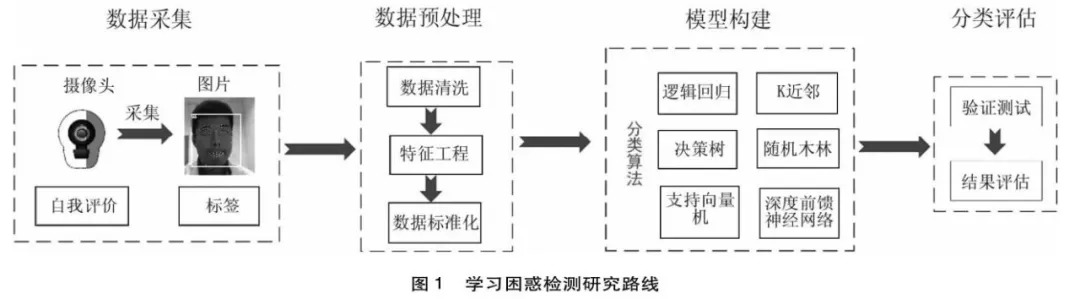
本研究尝试设计实验诱导学生产生困惑情绪,并基于面部表情实现学习困惑的自动识别。整体研究技术路线如下:在实验室环境下,研究人员通过采集学生在英语测试中的面部表情,并经过一系列数据预处理操作提升数据质量,使用六种机器学习分类算法建立学习困惑检测模型,最后对模型进行评估(见图1)。
(一)数据收集
1.实验流程
本实验选取了某大学20名在校研究生进行英语测试,男女比例为1:1;每位被试需完成30道英语测试题,试题来源于知名在线题库“组卷网”(https://www.zujuan.com/)。研究者从题库选择难、中等和容易三种难度的选择题,比例为1:1:1。被试人员英语水平分布为:通过大学生英语六级考试的40%,已通过四级考试的50%,未通过四级考试的10%。本次实验在实验室环境下进行(见图2),被试在电脑上进行试题作答,研究人员用另外一台电脑通过摄像头(型号:Intel No.VF8010)实时采集被试面部表情。研究者采集学生解答每道题时的5张面部表情图片,共采集每个学生150张表情图片,整个实验共计采集3000张表情图片。

2.定义数据标签
在基于面部表情识别情绪的相关研究中,国外同行通常根据研究对象的自我报告定义数据标签(Durso et al.,2012;Whitehillelal.,2014)。因此,在测试完成后,被试需要再次浏览所有试题,确定解答每道试题时的学习困惑状态,并通过自我评价定义困惑标签。为了使被试对困惑标签的定义更客观,本研究仅使用两类学习困惑标签:困惑和不困惑。若被试对英语试题所表达的意思、选项答案、考察知识点等一或多个因素不了解,不知道如何选择则被视为困惑;反之,被试对该道英语试题意思及考察知识点完全清楚,几乎不需太多思考就能选定答案则定义为不困惑。
(二)数据预处理
1.数据清洗
实验中,被试思考和解答试题时常会头部晃动,造成面部偏离图像的中央位置,摄像头不能正确捕捉面部特征点,因此,需要对采集的面部特征图像数据进行筛选。摄像头采集的3000张图片中,有492张未能记录面部特征点或正脸偏离图像中央,删除上述不符合实验要求的数据,共得到2508条有效记录。
2.特征提取
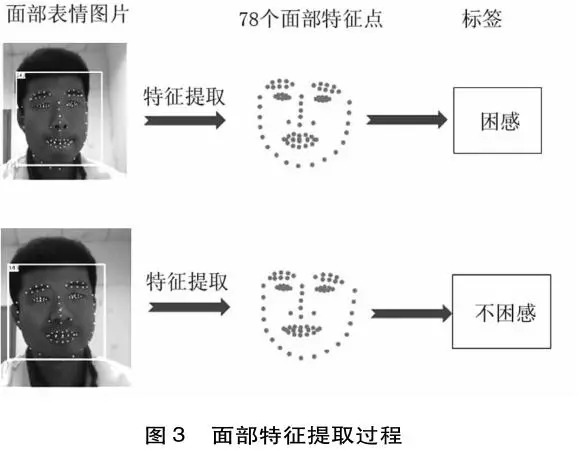
本研究所采集的原始图片规格为640X480的彩色照片,共计307200个特征,包含大量无关特征和背景噪声,因此需要进行特征提取。本研究利用ASMLibrary库直接提取78个面部特征点的二维坐标(见图3)。这些点包括眼睛、眉毛、嘴角等与情绪检测关联较强的面部特征,特征维度为156。利用特征点构成新的数据集进行困惑检测,能减小运算的复杂度,提高算法效率。
3.数据标准化
在开始学习困惑自动识别建模任务前,本研究对原始数据进行了标准化处理,利用规范化后的数据构建模型。数据标准化是将数据按比例缩放,使之落入一个小的特定区间。其中最典型的是对数据做归一化处理,即将数据统一映射到[0,1]区间内。归一化有很多优点,可以提升模型收敛的速度又能提高模型的精度。本文使用的是z-score标准化,也叫标准差标准化,即对原始数据的均值和标准差进行标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:σ。其中,为转化后的值,μ、σ分别为所有样本数据的均值和标准差。
(三)自动检测模型架构
本研究使用逻辑回归、支持向量机、K近邻、决策树、随机森林和深度前馈神经网络建立学习困惑自动检测分类模型。逻辑回归(Logistic Regression,简称LR)是最常见的分类方法之一,常用作预测建模等教育数据挖掘任务(宗阳等,2016)。二元逻辑回归是最简单的形式,即根据一或多个连续或离散自变量预测两个离散因变量的广义线性模型,本研究预测变量只有两个类别,因此使用二元逻辑回归。
支持向量机(Support Vector Machine,简称SVM)是一种具有坚实的统计理论基础的分类技术,可将数据映射到高维空间进行非线性分类。SVM应用于高维数据,可有效避免维度灾难问题,本研究采用的支持向量机核函数为高斯核。K近邻(K-Nearest Neighbor,简称KNN)是一'种基于度量实例间的相似性或距离的“惰性学习”算法,通过距离度量找出训练集中与其最靠近的K个训练样本,并使用“投票法”,选择K个样本中出现最多的类别作为预测结果。本研究K值设置为3,即通过最邻近的三个样本确定分类标签。
决策树(Decision Tree,简称DT)是一种解释性很强的分类算法,模型可以通过由节点和分支组成的树形结构展现出来。常见的决策树算法有ID3、C4.5、C5.0和CART等,本研究使用的是CART算法。随机森林(Random Forest,简称RF)是一种以决策树为基础分类器的集成方法,其优势是为决策树的训练加入属性的随机选择。具体过程分三步:首先,利用bootstrap抽样从原始训练集中抽取N个样本,且每个样本的容量与原始训练集相同;其次,对N个样本分别建立N个决策树模型,得到N种分类结果;最后,根据N种分类结果对每个记录进行投票表决,决定最终分类(周志华,2016)。
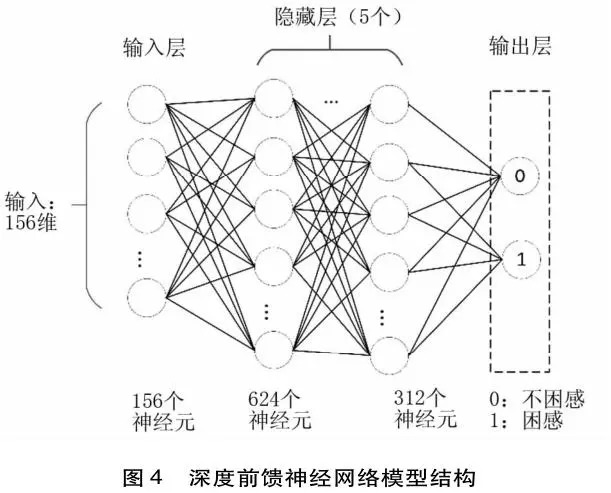
深度前馈神经网络也叫多层感知机(Multi-Layer Perceptron,简称MLP),是典型的深度学习模型。本研究的深度前馈神经网络由五部分组成(见图4):一个输入层,五个隐藏层和一个输出层。输入数据的维数为156,五个隐藏层的神经元数分别为624、624、312、312和156,输出为0或1(0:不困惑;1:困惑)。每个神经元以不同权重与前一层所有神经元相连,数据由输入层经过多个隐藏层传递到输出层。此外,本研究使用反向传播算法最小化当前输出和实际期望输出之间的误差,此过程可降低神经网络在学习迭代过程中的全局误差。为防止反向传播过程中的梯度消失,除输出层的激活函数使用sigmoid函数外,其余各层使用ReLU函数(Rumelhart et al.,1986)。
三、结果及讨论
(一)分类性能评估
本研究使用准确率、精度、召回率和F值作为评价指标比较各分类器的性能。四种评价指标的计算公式见表一,其中“真正”(True Positive,简称TP)对应分类模型正确预测的样本数,“假负”(False Negative,简称FN)对应分类模型错误预测为负类的正样本数,“假正”(FalsePositive,简称FP)对应分类模型错误预测的正类的样本数,“真负”(True Negative,简称TN)对应分类模型正确预测的负样本数(Tan et al.,2005)。
(二)自动识别学习困惑结果比较
本研究通过Python编程语言的scikit-leam机器学习库建立学习困惑自动检测模型。由于面部特征点输入属性有156维,维度较高,为防止过拟合现象,本研究采用10折交叉验证方法进行学习困惑模型训练,通过交叉验证提升模型的泛化能力(Kohavi,1995)。
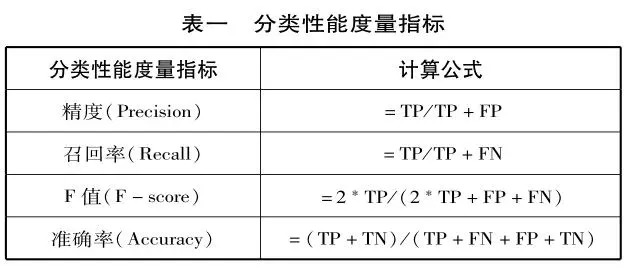
1.六种分类模型学习困惑检测结果
利用逻辑回归、K近邻、支持向量机、决策树、随机森林和深度前馈神经网络建立的分类模型预测结果见表二,六种分类算法可较好地检测学习困惑,准确率均高于58.83%。其中,随机森林预测的准确率最高,为71.8%,K近邻也取得与随机森林相当的预测准确率,超过70%;支持向量机、决策树和深度前馈神经网络三种分类模型均可得到约65%的预测准确率;逻辑回归模型预测的准确率最低,仅为58.83%,表现最差。
从表二可以看出,对困惑数据检测的表现整体低于不困惑数据。对于不困惑样本数据,K近邻取得的精度最高,为0.74,支持向量机的召回率和F值最高,分别为0.95和0.77。对于困惑样本的数据,支持向量机的精度虽最高,召回率却最低。综合表二困惑和不困惑两种样本的平均精度、召回率和F值,可得随机森林和支持向量机的平均精度最高,为0.71;K近邻和随机森林的平均召回率最高,为0.71;随机森林的F值也是六种分类算法中最高的,为0.71;逻辑回归的平均精度、召回率和F值均最低,分别是0.58、0.59和0.59。
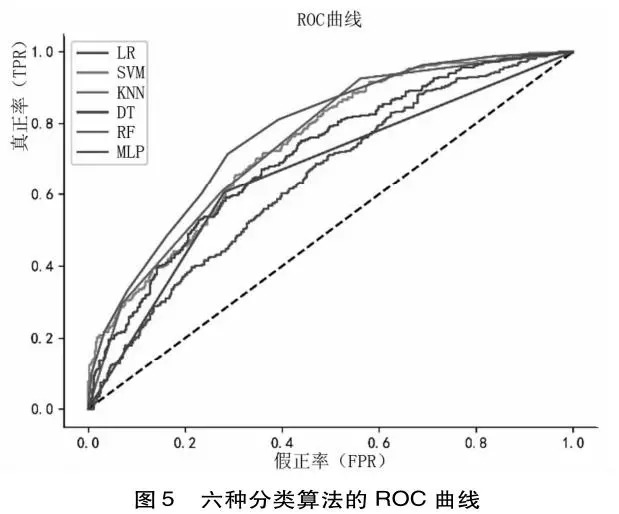
2.R0C曲线
学习困惑的检测ROC曲线见图5。该曲线是显示分类器真正率(TPR)和假正率(FPR)之间折中的图形化方法(Tan et al.,2005)。真正率沿y轴绘制,FPR显示在x轴,在ROC曲线中,好的模型靠近左上角部分。图5中,随机森林模型在最外侧,最靠近图形的左上角,为最优学习困惑检测模型;相反,表现最差的逻辑回归模型,离左上角距离最远。R0C曲线下方的面积是另一个评估分类器的指标,面积越大,预测性能越优。总体来看,模型的预测准确率越高,其面积越大。当FPR小于0.2时,决策树的模型预测能力最弱;当FPR大于0.2小于0.5时,学习困惑分类结果最好的三种算法分别为:随机森林、K近邻和支持向量机。从总面积看,随机森林面积最大,逻辑回归最小,分别对应最佳和最差的分类效果。因此,从ROC的曲线面积和位置可有效比较学习困惑检测模型的分类性能好坏。
3.各分类器表现差异的原因
随机森林取得了最高的预测精度,原因在于这是一种集成的方法,将若干决策树模型组合起来,故比单独的决策树模型取得更好的预测表现(周志华,2016)。通过对K近邻算法中参数的调整,在K为3时,取得了超过70%的预测准确率。支持向量机对核函数的参数较为敏感,准确率与决策树相当,为67.33%。由于本研究数据的维度较高,决策树的深度较深,可能会造成过拟合现象,最终影响预测的准确率,仅为66.27%。本研究的深度前馈神经网络有5个隐藏层,取得了65%左右的准确率。有研究表明,随着深度神经网络隐藏层数目的增加,准确率会有所提高,但模型训练的参数和难度也会随之增加(Homik et al.,1989)。
(三)学习困惑检测意义及应用
计算机通过对学习者的情感进行获取、分类和识别,能减轻人们使用计算机的挫败感,帮助理解学习者的情感世界(夏洪文,2008)。使用机器学习分类算法建立学习困惑自动检测模型,及时获取学习者的情感状态,并采取相应的干预手段,可以及时纠正学生的学习行为,对提高教学质量和学习成绩均有积极影响(丁梦美等,2017;Pool&Qualter,2012)。教学干预在解决学习困惑的同时,有助于学生的知识内化与建构,实现智慧学习。
学习情绪的识别是下一代智能教辅系统的重要组成部分,应用学习困惑检测技术可促进个性化学习(Vail et al.,2016)。学习者在使用智能教学系统时,如果对某些知识点感到困惑,系统将为其推荐相关的学习资源,如与知识点相关的网页、文本和视频片段等,帮助学生摆脱困惑情绪,提升学习效果(陈凯泉等,2017;Agrawal et al.,2015)。此外,将困惑检测技术应用于在线学习平台,有助于降低课程的辍学率(Yang et al.,2015)。
四、结论与展望
学习困惑检测是设计有效的教学策略和干预措施的重要一步。本研究尝试基于面部表情的困惑识别方法:在英语测试时诱导困惑情绪的产生,并利用摄像头实时采集学生的面部表情,后测中被试通过自我评价确定每道题的困惑标签,对原始数据进行预处理后,应用六种分类算法建立学习困惑自动检测模型。研究表明,六种机器学习分类算法能较好地检测学习困惑,其中,随机森林对学习困惑的检测综合性能最好,是最佳分类模型,这类模型对于未来智能教学系统中学习者困惑的检测有一定参考价值,可为处于困惑状态的学生提供有效的教学干预,对提高学习成绩有一定促进作用。
本研究应用基于面部表情的检测方法,取得了较高的精度,可为学习困惑的识别提供参考,但仍存在较多不足。首先,在图像采集过程中,由于被试答题有时头部会晃动,造成摄像头对特征点的提取不准确,影响数据质量。其次,在后测环节,每位被试需完成30道测试题所需时间较长,通过自我评价确定困惑标签准确性会受到时间的影响,可能会造成实验结果的偏差。再次,本研究仅考虑自动检测学习情绪中两种水平的困惑,未来研究可考虑多种学习情绪的多水平识别方法。例如,学习困惑存在多个不同水平(Wang et al.,2013),如参与(Whitehill el al.,2014)、无聊(Kim et al.,2014;Botelho et al.,2017)、沮丧(Cleveland-Innes&Campbell,2012)等学习情绪也会对学习产生显著影响。最后,本研究所使用的六种常见数据挖掘算法在某些方面仍存在局限,后续研究可考虑使用其他更高效的算法,如卷积神经网络,其优势在于特征的自动提取,对复杂图像的检测精度更高。






基金项目:国家自然科学基金项目“基于多目标稀疏优化的多视图聚类方法”(61503340)。
作者简介:江波,博士,副教授,硕士研究生导师,浙江工业大学教育科学与技术学院,研究方向:学习分析、教育数据挖掘、情感计算;李万健,硕士研究生,浙江工业大学教育科学与技术学院;李芷璇,硕士研究生,浙江工业大学教育科学与技术学院;叶韵,硕士研究生,浙江工业大学教育科学与技术学院。
转载自:《开放教育研究》第24卷 第4期
排版、插图来自公众号:MOOC(微信号:openonline)
喜欢我们就多一次点赞多一次分享吧~
有缘的人终会相聚,慕客君想了想,要是不分享出来,怕我们会擦肩而过~