
◆
精彩推荐
◆
由易观携手CSDN联合主办的第三届易观算法大赛正在火热进行中!冠军奖3万元,每团队不超过5人参赛。
本次比赛主要预测访问平台的相关事件的PV,UV流量(包括Web端,移动端等),大赛将会提供相应事件的流量数据,以及对应时间段内的所有事件明细表和用户属性表等数据,进行模型训练,并用训练好的模型预测规定日期范围内的事件流量。

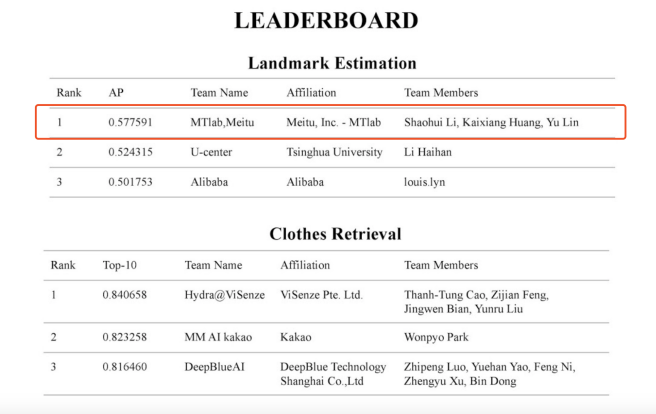
【导读】近日,ICCV DeepFashion2 Challenge 2019公布了比赛结果,首次参赛的美图影像实验室MTlab凭借其在综合检测精度上的优势,以明显差距斩获服饰关键点估计(Landmark Estimation)赛道的冠军。DeepFashion2 Challenge此次共吸引18支国内外顶级技术团队参与,包括清华大学、阿里巴巴等知名企业及学术机构。
图 1 ICCV DeepFashion2 Challenge 2019
据介绍,DeepFashion2 Challenge是基于DeepFashion1和DeepFashion2 公开数据集基础上的计算机视觉领域技术竞赛。今年的比赛分为两个赛道,服饰关键点估计及服饰检索(Clothes Retrieval)。
此次美图参与的是服饰关键点估计赛道,服饰关键点估计比赛包含193,000个图像训练数据,32,000个验证集图像数据,63,000个测试集图像数据。比赛任务中包含13个不同的服饰类别,每个类别都有独立的8到37个关键点,共计294个关键点。
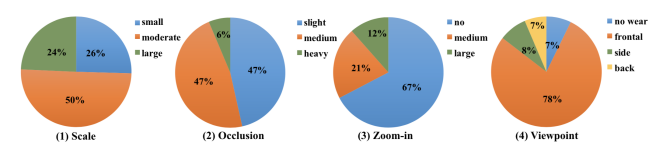
如何实现同时检测多个类别共294个关键点是此次比赛的难点之一。此外,如图2所示,DeepFashion2数据集包含了多种尺度、遮挡、视角等复杂情况下的服饰图像数据,因此提升模型对服饰在不同情况下的鲁棒性也是比赛的一大挑战,需要投入大量的研发精力。
图 2 DeepFashion2数据类型分布
在本次比赛中,MTlab团队所建立的模型在综合检测精度表现出明显优势,该模型可以同时对13个类别的服饰进行关键点估计,相较于多个模型而言,大大降低了算法复杂度以及使用成本。其次,该模型还具备良好的扩展性,通过类别信息的使用,可以一次应对多类别的数据。
目前基于多目标的关键点估计方法大致可以分为自下而上(Bottom-up)和自上而下(Top-down)两类。自上而下的方法主要包含两个步骤,首先通过目标检测算法将图像中的每一件服饰检测出来,随后针对每一个检测出来的服饰区域图像估计其关键点位置。
自下而上的方法也包含两个步骤,首先将图片中所有的服饰关键点检测出来,然后通过一定计算方式将关键点聚类到不同的服饰上。为了提高模型的扩展性与应用性,并且缓解单图多目标交叉重叠导致的关键点错位等问题,MTlab采用了基于自上而下方法的关键点检测方案,即将该任务分解成多目标框检测及单目标关键点估计,并将这两步操作进行单独优化。
基于自上而下的方法,第一步是进行服饰检测。目标检测是计算机视觉中的核心任务之一。目标检测即自动找到图像中所有目标物体,包含物体的定位和物体分类两个子任务,同时确定物体的类别与位置。当前对目标检测的研究是学术界的一个热点,R-CNN、Fast R-CNN、Faster R-CNN、YOLO及SSD等一系列模型的提出大大加速了该领域的发展,比如人脸检测、行人检测及车辆检测等在工业界也得到了很好的应用。但是针对服饰数据的目标检测任务当前少有研究也应用不足,一个主要的原因是服饰数据标注难度较大,且公开的高质量标注数据集少。
此次比赛的数据集除了服饰关键点标签外还提供了包含服饰检测框外的多种标注标签,据此,MTlab团队可以进行服饰检测的模型训练学习。此外,基于自上而下的方案,由于最终关键点是基于目标检测的结果来做估计的,所以服饰检测的好坏对最后成绩的影响至关重要。
第二步进行单服饰的关键点估计。目前对关键点的估计应用最多的是人体骨骼点估计, 已有的方法在模型上可分为单阶段的(One-stage)以及多阶段的(Multi-stage),在输出上可分为基于坐标回归(Coordinate)、热力图(Heatmap)以及热力图结合偏移信息(Heatmap + Offsets)。
相对于人体骨骼数据,服饰关键点数据在遮挡、角度、尺度以及非刚性变形尤为严重,这也使得服饰关键点估计异常困难。
在最终的实施方案中,MTlab首先在图上做目标框检测,找出可能为服饰的目标框,由此可以获得较多粗略的服饰框。再基于这些框的检测结果去做单服饰目标框的关键点估计,并同时对框进行额外的打分,给出最终有效的关键点。
通过这种方案,可以分开优化多目标框检测模型和单目标关键点估计模型,降低模型优化复杂度,从而可以更充分地利用计算资源以提高该模型的准确度。而在应用层面上,服饰检测与服饰关键点识别有不同的应用领域,两个模型均可独立使用,后续模型仍可以有效地通过不同数据持续优化提高。
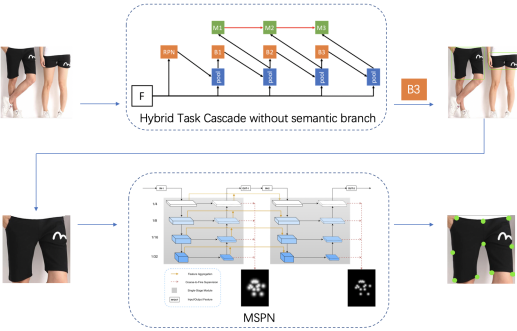
图 3 服饰关键点预测流程图
在比赛的多目标框检测阶段,MTlab采用了Hybrid Task Cascade model (如图3上图所示)作为基础模型。而在单目标关键点估计阶段,则以Multi-stage Pose Estimation Network (图3下图所示)的肢体关键点估计模型作为基础模型。在两个基础模型上,MTlab基于服饰关键点检测任务的特点以及评价指标,针对模型的不同方面进行了深入的优化及改进:
由于服饰检测任务较为复杂,各种尺度及遮盖等情况往往会造成误检、漏检等问题,所以MTlab使用多尺度训练及多尺度测试的检测方案对模型进一步优化。同时利用该方案two stage的特性,在目标框检测过程中优化了模型的召回率,在关键点估计模型中除了给出关键点,还会对目标检测阶段给出的框基于置信度打分,这样有助于提高算法的精确度,从而达到在mAP指标上的的整体优化。
该任务中需要检测的关键点一共包含13个不同服饰类别的294个关键点,每个类别都有自己独立的一组关键点。为了实现一个模型可以同时检测所有类别的关键点,MTlab将第一步目标框检测中给出的类别信息作为先验知识,通过与输入数据在通道维度上的concatenate ,加入到关键点估计模型中,给予一个强的先验知识,可以帮助关键点估计模型降低学习难度,并且提高了置信度打分的精度。
在关键点估计模型中,各个类别中的关键点间存在着一定的结构关系,为了更好地挖掘这种空间相关信息,MTlab在模型中引入non-local 的结构进行特征信息融合计算,替代了部分原始模型的resblock,从而提高整体关键点的准确性。
在关键点模型中,为了让模型能一步步地定位到更为精细的关键点位置,在计算各个scale和stage的损失函数时,MTlab针对不同scale和不同stage采用不同的损失权重。除此之外,为了提高较难检测关键点的预测精确度,MTlab通过对不同scale的输出采用不同的OHKM的策略来计算损失权重。虽然最终以最后一个stage的最大scale输出作为模型,但它依赖于前面所有尺度的计算结果,因此对不同尺度的输出进行优化则相当于优化了最终的输出结果。
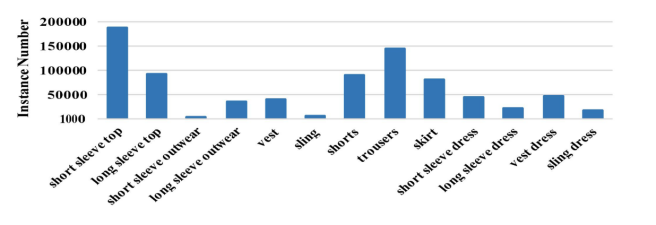
通过图4不难发现,DeepFashion2官方给出的数据集中有较为严重的数据不均衡情况,数据量最多的类别的数目是最少的约180倍之多,该情况对模型的训练带来了较大的影响。为了解决这个问题,MTlab的模型在目标框检测阶段与关键点估计阶段的loss计算中,引入了针对不同类别的attention,以减少训练中不同类别数据不均衡的情况对关键点模型的影响。
图 4 DeepFashion2 衣服类别数量分布
通过对基础模型进行多维度的强化,MTlab团队最终在测试集上获得了0.5775 mAP的分数,意味着在结合召回率与精确度的综合指标上超过了其他参赛团队。
图5 预测结果图
MTlab作为美图公司的核心算法研发部门,在计算机视觉、深度学习、增强现实等领域深耕多年,具备强大的研发实力。其中,基于服饰的计算机视觉技术也是MTlab重点研究方向之一。据悉,服饰信息识别技术目前已成功应用在美图秀秀动漫化身功能中,系统可以识别用户上传人像的服装风格,并匹配生成穿着同款服饰的卡通形象。谈及该技术未来的应用前景,MTlab负责人说道:“服饰作为衣食住行的一个重要方面,是一项刚需。因此,与服饰相关的视觉识别技术,有着广泛的应用场景,比如时尚趋势分析、营销数据分析等,对商品精准推荐、服饰潮流捕捉等方面都有着重要意义。”
据MTlab介绍,服饰信息识别技术是人工智能算法在服饰电商、内容媒体和线下服装零售等行业实现应用落地的基础。对于商家而言,该技术有利于在实现数据智能化管理,平台智能化运营,降低人力成本的同时提高运营效率。而对于用户来说,该技术可以为用户提供个性化推荐、智能搭配、虚拟试穿和一键购物等服务,有效提升了用户的购物体验。
具体来看,在服饰电商领域,该技术可以融入到电商平台的一些智能化业务之中,包括拍照购物、搭配推荐和用户个性化等。一方面有助于电商平台为用户提供更优质的用户购衣体验,从而提高店铺转化率和客单价;另一方面电商平台可以实现智能化运营,降低人力成本的同时提高运营效率。
在内容媒体方面,该技术可以辅助内容媒体更高效地产出时尚图片、短视频等优质内容,也可以让时尚媒体的优秀内容产品被轻松检索、关联和推荐。而在线下服装零售中,该技术在未来可以结合到智能硬件及其他技术一体化解决方案中,从而为门店客户提供一键购衣试衣、智能搭配和推荐等服务。通过智能化服务,为消费者带来全新购衣体验。
从服装电商、信息检索、个性化推荐到智能试衣,服饰相关技术日趋成熟,为科技赋能商业增添了更多的可能性。MTlab负责人对此表示:“未来我们会加速服饰相关技术算法的应用落地,将算法与更多的业务结合,对模型进行优化以适配不同的使用场景。同时也将充分利用该模型结构的可拓展性,服务于服饰以外的更多领域。”值
得一提的是,美图公司于今年4月正式上线美图AI开放平台,并且已成功服务于诸多业务场景,包括医疗美容、美妆门店、智能硬件、移动互联网等领域。
References:
[1] Kai Chen et al. Hybrid task cascade for instance segmentation. In: IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[2] Wenbo Li et al. Rethinking on Multi-Stage Networks for Human Pose Estimation. 2019. arXiv:1901.00148
◆
精彩推荐
◆
由易观携手CSDN联合主办的第三届易观算法大赛正在火热进行中!冠军奖3万元,每团队不超过5人参赛。
本次比赛主要预测访问平台的相关事件的PV,UV流量(包括Web端,移动端等),大赛将会提供相应事件的流量数据,以及对应时间段内的所有事件明细表和用户属性表等数据,进行模型训练,并用训练好的模型预测规定日期范围内的事件流量。