【硬核书】迁移学习多智能体强化学习系统,131页pdf

学习解决顺序决策任务是困难的。人类花了数年时间,基本上以一种随机的方式探索环境,直到他们能够推理,解决困难的任务,并与他人合作实现一个共同的目标。人工智能智能体在这方面和人类很像。强化学习(RL)是一种众所周知的通过与环境的交互来训练自主智能体的技术。遗憾的是,学习过程具有很高的样本复杂性来推断一个有效的驱动策略,特别是当多个智能体同时在环境中驱动时。
然而,以前的知识可以用来加速学习和解决更难的任务。同样,人类通过关联不同的任务来构建技能并重用它们,RL代理可能会重用来自先前解决的任务的知识,以及来自与环境中其他智能体的知识交换的知识。事实上,目前RL解决的几乎所有最具挑战性的任务都依赖于嵌入的知识重用技术,如模仿学习、从演示中学习和课程学习。
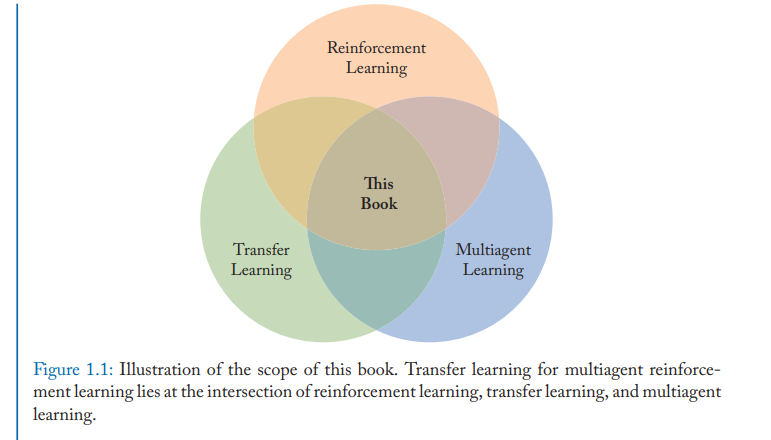
本书概述了多agent RL中关于知识重用的文献。作者为重用知识定义了最先进的解决方案的统一分类,提供了该领域最近进展的全面讨论。在这本书中,读者将发现关于知识在多智能体顺序决策任务中重用的许多方法的全面讨论,以及在哪些场景中每种方法更有效。作者还提供了他们对该地区目前低垂的发展成果的看法,以及仍然开放的大问题,可能导致突破性的发展。最后,本书为想要加入这一领域或利用这些技术的研究人员提供了资源,包括会议、期刊和实现工具的列表。
这本书将对广大读者有用;并有望促进社区间的新对话和该地区的新发展。
https://www.morganclaypool.com/doi/10.2200/S01091ED1V01Y202104AIM049



专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“TMRS” 就可以获取《【硬核书】迁移学习多智能体强化学习系统,131页pdf》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2022年9月12日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年9月12日