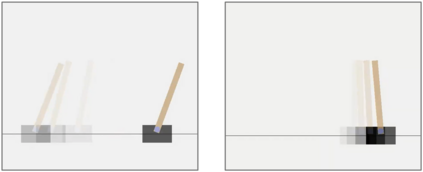
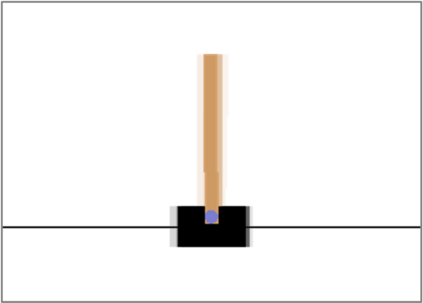
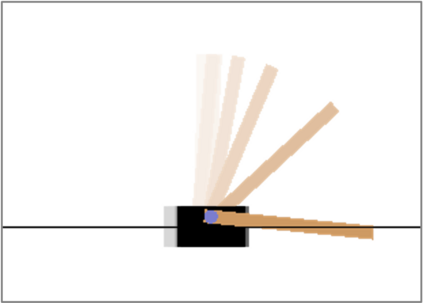
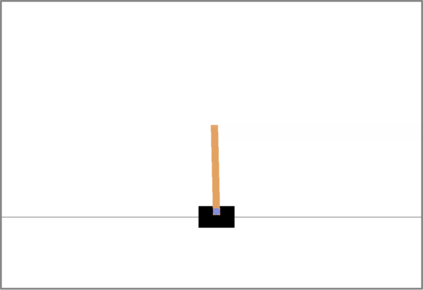
Autonomous agents deployed in the real world need to be robust against adversarial attacks on sensory inputs. Robustifying agent policies requires anticipating the strongest attacks possible. We demonstrate that existing observation-space attacks on reinforcement learning agents have a common weakness: while effective, their lack of temporal consistency makes them detectable using automated means or human inspection. Detectability is undesirable to adversaries as it may trigger security escalations. We introduce perfect illusory attacks, a novel form of adversarial attack on sequential decision-makers that is both effective and provably statistically undetectable. We then propose the more versatile E-illusory attacks, which result in observation transitions that are consistent with the state-transition function of the environment and can be learned end-to-end. Compared to existing attacks, we empirically find E-illusory attacks to be significantly harder to detect with automated methods, and a small study with human subjects suggests they are similarly harder to detect for humans. We conclude that future work on adversarial robustness of \mbox{(human-)AI} systems should focus on defences against attacks that are hard to detect by design.
翻译:在现实世界中部署的自主代理机构需要强力对付对感官投入的对抗性攻击。强有力的代理政策要求预见到最强烈的攻击。我们证明,现有的观测空间对增强学习代理机构的攻击有一个共同的弱点:虽然有效,但缺乏时间一致性使得它们能够使用自动化手段或人体检查被检测出来。对对手来说,可探测性是不可取的,因为它可能引发安全升级。我们引入了完美的幻觉攻击,这是对相继决策者的对抗性攻击的一种新形式,既有效,又在统计上是无法检测的。我们随后建议采用更灵活的电子攻击,从而导致与环境的状态过渡功能相一致的观察过渡,并能够学到端到端到端的学习。与现有的攻击相比,我们从经验上发现,电子智能攻击明显难以用自动化方法探测出来,对人体主体进行的一项小研究表明,它们同样难以为人类探测。我们的结论是,今后关于\mbox(人)AI}系统对抗性强健性的工作应当侧重于防范难以通过设计探测到的攻击。