基于神经网络的高性能依存句法分析器
“全球人工智能”拥有十多万AI产业用户,10000多名AI技术专家。主要来自:北大,清华,中科院,麻省理工,卡内基梅隆,斯坦福,哈佛,牛津,剑桥...以及谷歌,腾讯,百度,脸谱,微软,阿里,海康威视,英伟达......等全球名校和名企。
一、依存句法分析器综述
谈起依存句法分析,主流的统计句法分析一般分为两大流派——生成式和判决式。
1、生成式句法分析
生成式就是生成一系列句法树,从里面挑选出概率最大的那一棵作为输出。在具体实现的时候,可以选择最大熵等模型去计算单条依存边的概率,利用最大生成树算法来挑选最佳句法树,比如《最大熵依存句法分析器的实现》。
其优点是效果好,但开销大。训练的时候常常要用一份巨大的特征模板,得到的模型中含有大量复杂的特征函数。在解码的时候,这些特征函数的储存和运算成本很高。由于是全局最优,所以可以取得较高的准确率,还可以很方便地处理非投射的句法树。不过也由于搜索的全局性和特征函数的复杂度,模型常常会过拟合,在训练集和测试集上的准确率差别很大。
2、判决式句法分析
判决式一般是基于动作(或称转移)和一个分类器实现的,仿照人类从左到右的阅读顺序,判决式句法分析器不断地读入单词,根据该单词和已构建的句法子树等信息建立分类模型,分类模型输出当前状态下的最佳动作,然后判决式分析器根据最佳动作“拼装”句法树。
二、动作体系简介
一般有两大体系,分别处理投射和非投射两种语言现象。
1、投射
刘群老师在计算语言学讲义中说,大多数语言,包括汉语和英语,满足投射性。
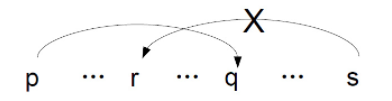
所谓投射性是指:如果词p依存于词q,那么p和q之间的任意词r就不能依存到p和q所构成的跨度之外(用白话说,就是任意构成依存的两个单词构成一个笼子,把它们之间的所有单词囚禁在这个笼子里,只可内部交配,不可与外族通婚)。比如:
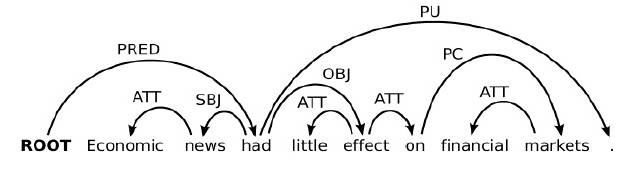
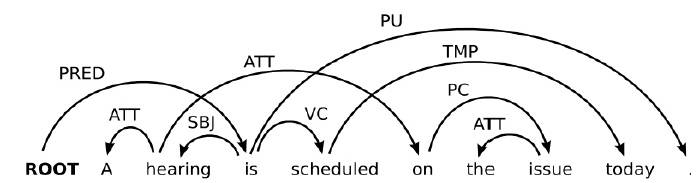
再比如:
处理投射现象的动作体系有Arc-eager和Arc-standard (Nirve, 2004),后者就是本依存句法分析器采用的动作体系,后面会详细阐述。
2、非投射
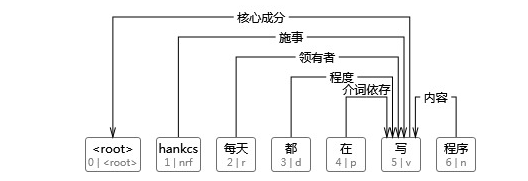
非投射就没有上述限制了,这会导致依存边有交叉,怎么都理不顺:
事实上,不同于刘群老师的观点,Saarbrücken说道,25% or more of the sentences in some languages are non-projective。对于汉语,王跃龙还专门写了《汉语交叉依存类非投射性现象.pdf》进行分门别类地详细研究,比如:

处理非投射的动作体系有Arc standard + swap (Nirve, ACL 2009)。
本Parser无法处理非投射现象,也就是说,即使一个句子本身是非投射的,但分析出来的依存句法树依然是投射的。
三、Arc-standard详解
在arc-standard system中,一次分析任务由一个栈s(题外话,有些人包括维基认为栈也叫堆栈,我强烈反对,堆是heap,栈是stack,heap和stack才混称堆栈),一个队列b,一系列依存弧A构成。如果定义一个句子为单词构成的序列,那么——
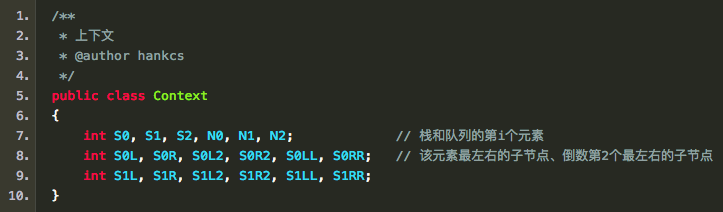
1、栈
栈s是用来储存系统已经处理过的句法子树的根节点的,初始状态下。另外,定义从栈顶数起的第i个元素为si。那么栈顶元素就是s1,s1的下一个元素就是s2:
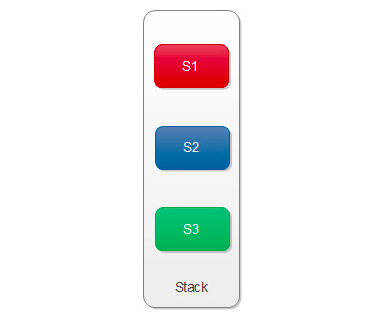
在一些中文论文中习惯使用焦点词这个表述,我觉得该表述更形象,如果我们将栈横着放,亦即让先入栈的元素在左边,后入栈的元素在右边:

则称s2为左焦点词,s1为右焦点词。接下来的动作都是围绕着这两个焦点词展开的。
2、队列
在《A Fast and Accurate Dependency Parser using Neural Networks.pdf》中,使用的是buffer这个单词,与其翻译为缓冲区,我认为这个概念更像一个顺序队列,而不是随机访问的缓冲区。队列模拟的是人眼的阅读顺序,人眼从左到右阅读,系统也从左往右读入单词,未读入的单词就构成一个队列,队列的出口在左边。初始状态下队列就是整个句子,且顺序不变:b=。
3、依存弧
一条依存弧(原文dependency arcs,我认为翻译成变换也许更好)有两个信息:动作类型+依存关系名称l。l视依存句法语料库中使用了哪些依存关系label而定,在arc-standard系统中,一共有如下三种动作:
LEFT-ARC(l):添加一条s1 -> s2的依存边,名称为l,并且将s2从栈中删除。前提条件:。亦即建立右焦点词依存于左焦点词的依存关系,例如:

RIGHT-ARC(l):添加一条s2 -> s1的依存边,名称为l,并且将s1从栈中删除。前提条件:。亦即建立左焦点词依存于右焦点词的依存关系,例如:

SHIFT:将b1出队,压入栈。亦即不建立依存关系,只转移句法分析的焦点,即新的左焦点词是原来的右焦点词,依此类推。例如:

可见当存在种依存关系时,系统一共有种变换。
四、基于神经网络的句法分析器
1、神经网络模型
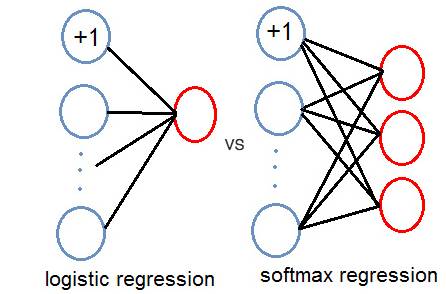
初等神经网络背景知识请参考《反向传播神经网络极简入门》,这并不是本文的重点。《反向传播神经网络极简入门》中介绍的是二分类模型,然而arc-standard转移系统中,一共有种变换,这时候就得将输出层由一个节点换成多个节点。或者由一个节点换成一个softmax层(这也是Chen and Manning (2014)中的标准做法)。单一输出节点和softmax层的区别如图:
假设训练集由m个样本组成:,每个样本的特征维度都是n+1,其中
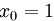
在二分类神经网络模型中,对隐藏层的输出做了一次逻辑斯蒂回归:
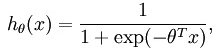
这个假设函数对应y=0的概率,用1减掉这个得到y=1的概率,二分类就是这么简单。而在多分类神经网络模型中,做的是softmax回归:
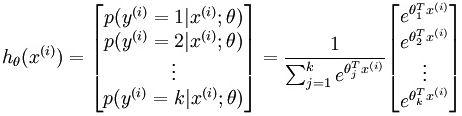
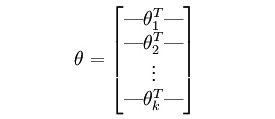
其中,输出是一个k维的向量,k是所有类别的数量。是模型的参数,在实现的时候,一般用一个的矩阵储存:
而则是用于概率分布的归一化。不过,在LTP的实现中,并没有使用softmax层,而是直接用了隐藏层的输出:
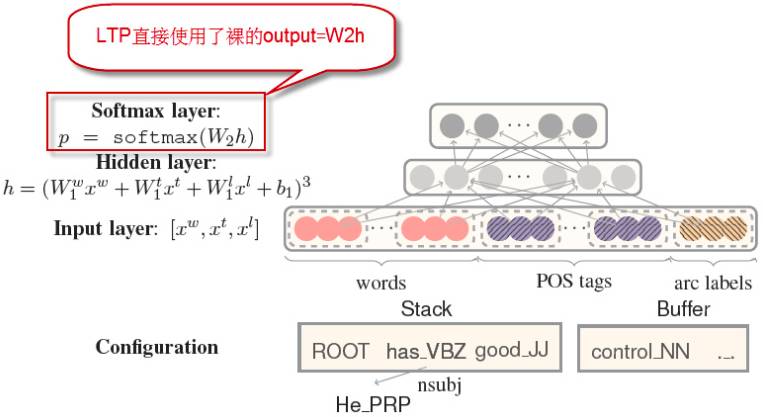
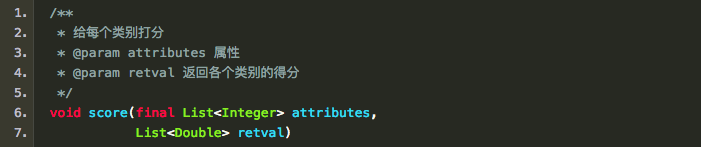
这使得该神经网络模型的输出不再是概率,而是表示概率大小的一个“分值”,所以代码中的方法名为:
2、特征提取
不同于传统句法分析器的人工编写特征模板的作坊式风格,Chen and Manning将一些零散的原始特征直接作为输入传入神经网络模型中。至于它们是如何组合的,不再由人工编写的特征模板决定,而是由神经网络模型的隐藏层自动提取。
如上图所示,Chen and Manning使用了词、词性、依存关系名称等作为了原始特征(这里还有他们的独创做法,且听下文分解)。
具体是哪些词和词性以及依存关系呢?对转移系统的当前状态(亦即上下文)来讲,有如下值得注意的词语:
NeuralNetworkParser#get_basic_features这个方法将它们的词和词性作为原始特征添加到了待分析的实例中。
3、词向量、词性向量、依存向量
词向量就是众所周知的word2vec训练出的向量,英文术语是embedding,我觉得直译成“词嵌入”有些过硬,还是通俗的词向量比较容易理解。
比较先进的句法分析器已经开始用词向量代替词本身来作为特征了,但Chen and Manning还有更绝的,他们把词性和依存关系也向量化了(To our best knowledge, this is the first attempt to introduce POS tag and arc label embeddings instead of discrete representations)。Chen and Manning说,既然词和词之间有相似的关系,那么词性、依存相互之间都应该有相似的关系。这些有相似度的向量导入模型后,对性能有所提升。
这些向量被存在一个矩阵中:

加载完模型后确定向量的维度

以后每个特征(词、词性、依存关系)都直接去这个矩阵里取出一列作为列向量就完成了到向量的转化:

不过,在此之前,还有一个性能提升的措施。
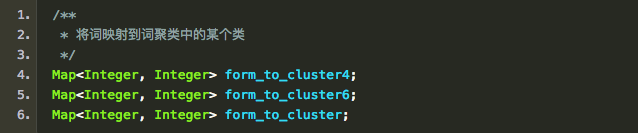
4、词聚类
词聚类也是一种特征的抽象化,相似的词在句法树中的功能也应该是相似的。LTP的文档中指出利用了Guo et. al, (2015)中提出的词聚类特征,然而我并没有找到这篇论文。如果你有,恳请告诉我。
接下来我将通过代码反推词聚类大概的作用。
首先,聚类的第一个问题就是聚成几个类。在代码中,一共聚类了3次,每次的类的数目都不同,从少到多依次是:
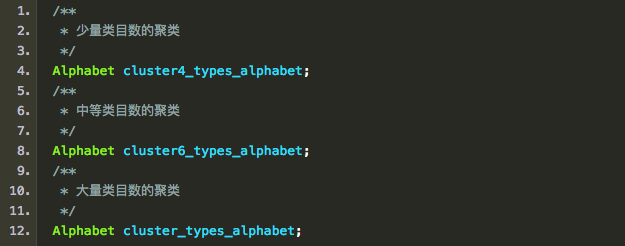
另外,还保留了每个聚类中每个类别的String->ID映射:
接下来就会将词映射到类的ID:
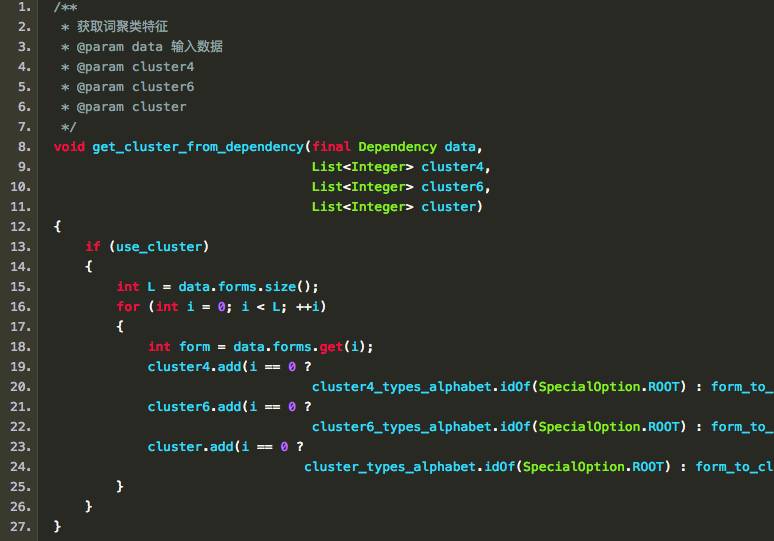
上文的特征提取中的词,其实都指的是词的聚类的ID,这就是上文提到的性能提升的措施。
5、距离和配价特征
Zhang and Nivre (2011)在中指出,两个焦点词的距离和配价(Valency,指的是一个词有几个子节点)都有助于分类决策。在实现中,分别对应:
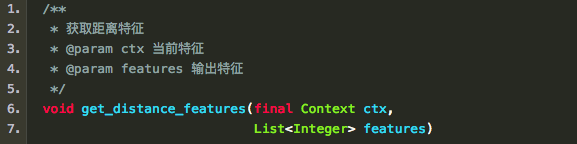
和
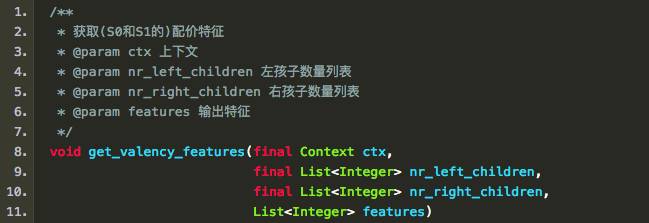
6、立方激活函数
如同《反向传播神经网络极简入门》中介绍的一样,常用的激活函数有tanh和Sigmoid这两种。不过在本句法分析器中,使用的是立方激活函数:
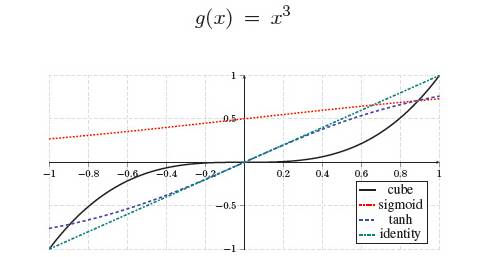
这个函数有什么好处呢?它可以将输入特征充分地组合起来,因为特征来自词、词性、依存这三个大类,假设分别为,那么
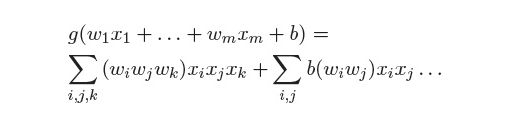
立方展开后将ijk遍历相乘,组合在一起了。据Chen and Manning试验,该立方激活函数在性能上优于传统的激活函数:
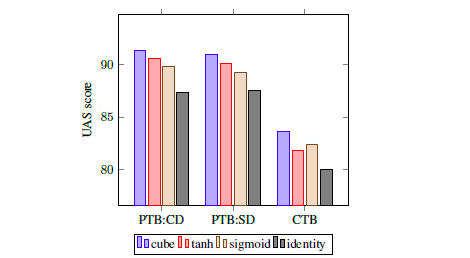
在代码中,对应:


进入全球人工智能学院





