这篇文章介绍的是我和 Luke Zettlemoyer 合作的一项工作,即在整个训练期间保持神经网络的稀疏性从而加速训练速度。这项工作证明,
通过完善稀疏动量算法,可以在短短一次训练中,用稀疏随机权值来初始化一个神经网络,并使其达到密集网络的性能水平。
进一步,如果使用优化的稀疏卷积算法,我们能够将对神经网络的训练速度加快至 VGG 网络训练速度的 3.5倍和宽残差网络(WRNs)训练速度的 12 倍之间。这与一些需多次对卷积层进行剪枝和重新训练且计算成本不菲的方法形成了鲜明的对比,比如 2019 年由 Frankle 和 Carbin 提出的“彩票假设”。
如此一来,我们证明了,将稀疏网络训练到密集网络的性能水平并不需要“中奖的初始化彩票”,但是如果能够结合“以一种明智的方法将权重移至周围的网络”这一方法,则能够依靠随机权重来实现这一点。我们称保持稀疏的同时性能也能维持在密集网络的水平的范式为“稀疏学习”。虽然这项工作表明了实现稀疏学习的可能性,但在下一步工作中,我们希望能够在要求与当前密集网络所需要的计算资源相同甚至更少的前提下,在更多的数据上训练规模更大以及更深的网络。
一、为什么我们选择使用稀疏学习?
计算资源的进步是推动深度学习进步的一个重要因素。从 2010 年到 2018 年,我们可以看到计算 GPU 的性能增加了 9700%。然而,由于达到了半导体技术的物理极限,我们可以预期在未来 5-8 年内,GPU的性能最多只会提高 80%。那么,一个无法对计算能力进一步提高的研究世界将会是什么样子呢?
从自然语言处理(NLP)社区中可以看出这一点,在该社区中,由于 ELMO、GPT、BERT、GPT-2、Grover 和 XL-Net 等经过预训练的语言模型在大多数NLP任务中效果优于其他方法,于是成为了整个领域的主导方法。
这些模型通常非常简单:你在大量文档上训练它们,在给定一系列其他词语后预测出某个词语——这有点像做填空游戏。那你可能会问,这有什么不妥吗?事实上,这些模型是如此之巨大,以至于它们需要耗费远超100 GPUs小时的训练时间。这对于那些想理解这些模型,但又缺乏大公司所拥有的计算资源而无法实现这一训练的学术研究人员来说,尤其令人感到沮丧。要真正理解这些庞大的语言预训练模型,首要目标应该是通过开发更加灵活的训练程序来使这些模型的训练过程更加的大众化。
实现这一目标的一个方法是从人脑中来寻找启发。人脑消耗的能量是 GPU 的1/10,但功能却是GPU的十的九次方倍。是什么使大脑的计算效率如此之高?原因有很多(更多信息可参考:
https://timdettmers.com/2015/07/27/brain-vs-deep-learning-singularity/
),而其中一个原因便是大脑所具有的稀疏性。
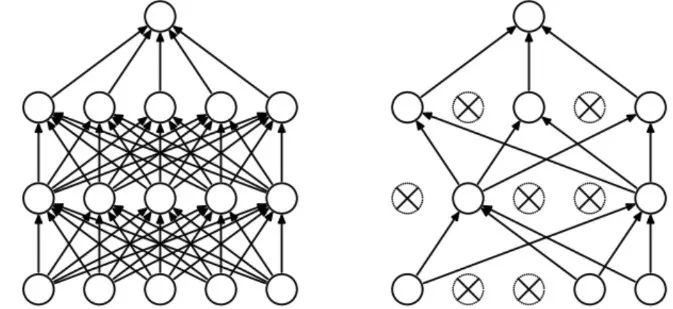
研究发现,灵长目动物大脑中神经元的数量元越多,与其他神经元的连接就越少 (Herculano Houzel 等人,2010)。这与我们设计深层神经网络的方式截然不同——深层神经网络将网络每一层中的每一个新神经元与前一层中所有的神经元连接起来。我们已经了解如何将经过充分训练的密集卷积神经网络压缩为稀疏网络(Han 等人,2015),但研究如何从一个稀疏网络入手并在训练期间保持网络稀疏的情况下顺利开展训练的工作,目前还是比较少。那么,我们该怎么做呢?
二、稀疏动量:一种训练稀疏网络的有效方法
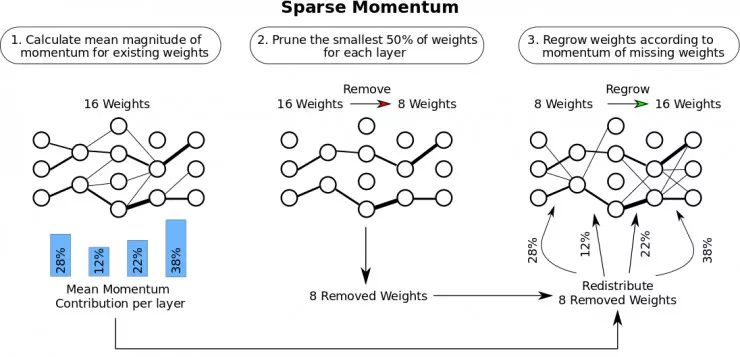
图1:稀疏动量通过查看最近梯度(动量)的加权平均值来确定稀疏网络中新权重的增长位置,从而找到同时减少误差的权重和层。(1)根据平均动量量级确定各层的重要性。(2)在每一层中,我们去掉最小权值的50%。(3)然后,我们根据各层的重要性在层之间重新分配权重。在同一个层中,我们在动量量级较大的地方增加权重。
在稀疏学习中,最重要的事情便是尽可能有效地利用神经网络中的每一个权值。如果把“有效性”定义为“减少误差”,那么我们对于如何推进稀疏学习就有了更加清晰的视角。我们需要找到一种度量方法来描述一个权重在减少误差时的有效性,并去掉所有无效的权重。一旦我们去除了这些权重,我们希望在认为未来有望减少误差的位置重新生成新的权重。
如果我们看权重所对应的误差的梯度,实际上我们是有一个度量方法的。然而,如果连续观察梯度的变化,我们发现梯度可以发生剧烈的波动。例如,如果你有一个将手写数字集从0到9进行分类的神经网络,并且这个权重可以很好地检测到顶部的一条直线,它可能有助于减少对数字5、7的检测误差,但对0、1、2、3、6、8、9,它不但可能没有帮助,甚至可能会适得其反。相反地,在右上角检测曲线模式的权重可能对数字0、2、3、8、9的检测有辅助作用,因此,我们希望该权重比“顶部直线”权重在减少误差时更具有连续性。如何在神经网络中自动检测出这样有效的权值呢?
如果将北极看作局部最小值,将指南针指向局部最小值看作梯度,则可以通过疯狂摇动来使指南针进行旋转,从而模拟更新随机梯度下降。随着每一次指针正对北极,它会减慢速度,并越来越频繁地指向北极方向,然而,由于旋转惯性,它仍然会“越过”这个方向。因此,当北极针还在来回移动,从这两三次的测量结果中你可能还不清楚北极到底在哪里。然而,如果你取平均的方向——某一次指针位于北极方向偏左一些,另一次则偏右一些——那么这些偏差就会消失,你会立刻得到一个非常接近真实中北极方向的指向。
这就是动量优化技术背后的主要思想:我们对连续梯度取平均值,以获得对局部最小值方向的最优估计。与指南针类似,随着时间的推移,指南针方向变化的速度越来越慢,于是我们希望用随机梯度下降中更高的权重来衡量最近的梯度方向。其中一种方法是分配一个加权平均值,即给当前梯度分配一个更大的权重,给之前的梯度分配一个更小的权重——这也被称为指数平滑。通过指数平滑权值的梯度,我们得到一个加权梯度矩阵,这个矩阵就是动量矩阵,通过它可以实现所谓的动量优化。通过这种方法,我们可以识别出哪些权重能够持续地减小误差。
从这里开始,我们对稀疏动量算法进行第一个重要的观察发现:如果一个权重的动量表示它所连续减少误差值的大小,那么网络每层中所有权重的平均动量就表示每层平均误差值减少的大小。我们之所以取这个量值是因为两个不同的权重可能会连续朝着负方向或者正方向变化。我们通过计算各层平均动量,可以很容易地比较各层平均权重的有效性。
这就使得,比如说在降低误差方面的效果,卷积层 A 的平均权重是全连接层 B 的平均权重的1/3,反之亦然。这种方法使我们能够有效地对权重重新分配:如果我们发现“无用的”权重,我们现在就可以准确地知道应该将其放在哪一层。但究竟该将它们放在某一层中的哪个位置呢?
接下来的两个问题更直接:哪些是最无用的权重?在一层中卷积层,应该在某一层中的哪个位置增加权重?
第一个问题是在神经网络压缩研究中的一个常见问题,针对这一问题,研究者普遍采取的方法是使用最小的动量大小来对权重剪枝。这有什么意义呢?如果我们假设所有的权重都是将动量大小相似的输入平均所得到的——在使用批量标准化时,这是一个合理的假设,那么较小的权值对激活神经元的影响也是最小的。去掉这些无用的权重,能够最小限度地改变神经网络在预测方面的性能。
一旦我们去掉了无用的权重,并通过层的平均动量将其重分配到有效权重层,就需要决定在层内将它们确切地分布到哪个位置。如果有人问道:“将哪两个处于非连接状态的神经元连接起来能够连续减少误差?” 这个问题的答案再次指向动量大小。然而这一次,我们想研究下“缺失”或零值权重的动量大小,也就是说想观察下那些之前被我们排除在训练之外的权重。因此,我们在缺失的权重拥有最大动量的地方来增加权重。这就完成了稀疏动量算法,如图1所示。
三、结果分析
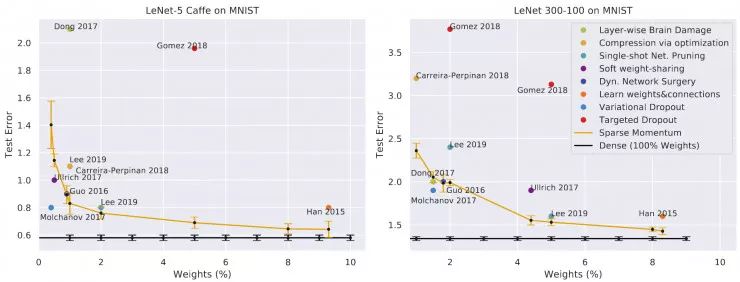
在 MNIST 手写数据集中使用稀疏动量与其他压缩算法来进行比较,结果令人印象深刻。其中,稀疏动量优于其他大多数方法。考虑到从头开始训练一个稀疏网络所使用的压缩方法是从密集网络入手并且往往需要分别进行重复训练,这一结果可以说非常不错了。
另一个令人印象深刻的发现则是:当网络使用 20% 的权重(80%的稀疏度)时,其性能可与密集网络持平甚至更优。
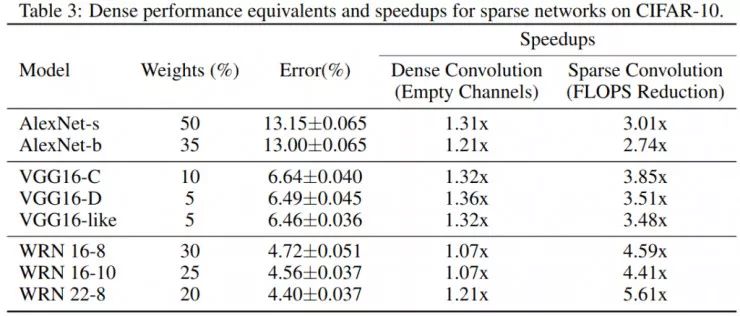
在 CIFAR-10 上,我们将其与单次网络剪枝进行了比较:后者的设计是为了实现简单的结构而不是性能的提高,因此,稀疏动量结果会更好也就不足为奇了。
然而,有趣的是,我们仅仅使用 5% 的权重就能够将 VGG16-D(VGG16 的一个版本,具有两个全连接层)和宽残差网络(WRN)16-10(具有16层结构深且非常宽的 WRN)训练到密集网络的性能水平。对于其他网络,稀疏动量接近密集网络的性能水平。此外,正如我稍后将要展示的,我们使用优化的稀疏卷积算法,将能够在获得相同的性能水平的前提下,将训练速度提升到之前的3.0到5.6倍!
图2:对LeNet-300-100和LeNet-5caffe在MNIST手写数据集中分别使用稀疏动量与神经网络压缩算法进行训练的结果对比图
![]() ImageNet下稀疏动量与相关方法的结果对比。在一个非全稀疏的模型中,第一层卷积层和所有下采样残差的连接从训练开始都是密集的。在一个全稀疏的网络设置中,所有层都是稀疏的。一般来说,稀疏动量比其他方法更有效,并且当所有权重都呈现为稀疏,与其他方法的效果相比,将几乎不分上下。这表明稀疏动量在寻找需要具有高密度的重要卷积层时是很有效的。
在 ImageNet 上,我们无法达到密集网络的性能水平,这表明稀疏动量的改善还有上升空间。然而,我们依旧可以证明在训练过程保持稀疏权重时,稀疏动量与其他的方法相比有着明显的优势。
稀疏学习的一个主要功能是加速训练——那我们成功了吗?既是又不是。如果我们衡量的是稀疏卷积网络可能实现的加速,则稀疏动量是能够有效加速训练进程的,然而如果仅仅最近才将稀疏网络用于训练,那对 GPU 而言,并不存在经优化的稀疏卷积算法,至少对于稀疏动量所表现出来的权重的细粒度稀疏格式而言是不存在的。
因此,我们将加速分成两个部分:如果存在稀疏卷积算法,则可能实现加速,并且如今可以使用标准密集卷积算法来实现加速。那密集卷积如何帮助稀疏网络加速训练进程呢?
如果我们去看网络的稀疏格式,我们会发现卷积通道是完全空的——一个完全为零的卷积滤波器!如果发生了这种情况,我们可以在不改变卷积结果的情况下从计算中去掉通道,从而实现加速。
稀疏动量可以用一小部分权重新复制一系列网络的密集性能水平,从而实现加速。
然而,如果观察各种不同的加速情况,我们会发现稀疏卷积加速和密集卷积加速之间存在显著差异。这一点可以表明 GPU 还需要优化稀疏卷积算法。
ImageNet下稀疏动量与相关方法的结果对比。在一个非全稀疏的模型中,第一层卷积层和所有下采样残差的连接从训练开始都是密集的。在一个全稀疏的网络设置中,所有层都是稀疏的。一般来说,稀疏动量比其他方法更有效,并且当所有权重都呈现为稀疏,与其他方法的效果相比,将几乎不分上下。这表明稀疏动量在寻找需要具有高密度的重要卷积层时是很有效的。
在 ImageNet 上,我们无法达到密集网络的性能水平,这表明稀疏动量的改善还有上升空间。然而,我们依旧可以证明在训练过程保持稀疏权重时,稀疏动量与其他的方法相比有着明显的优势。
稀疏学习的一个主要功能是加速训练——那我们成功了吗?既是又不是。如果我们衡量的是稀疏卷积网络可能实现的加速,则稀疏动量是能够有效加速训练进程的,然而如果仅仅最近才将稀疏网络用于训练,那对 GPU 而言,并不存在经优化的稀疏卷积算法,至少对于稀疏动量所表现出来的权重的细粒度稀疏格式而言是不存在的。
因此,我们将加速分成两个部分:如果存在稀疏卷积算法,则可能实现加速,并且如今可以使用标准密集卷积算法来实现加速。那密集卷积如何帮助稀疏网络加速训练进程呢?
如果我们去看网络的稀疏格式,我们会发现卷积通道是完全空的——一个完全为零的卷积滤波器!如果发生了这种情况,我们可以在不改变卷积结果的情况下从计算中去掉通道,从而实现加速。
稀疏动量可以用一小部分权重新复制一系列网络的密集性能水平,从而实现加速。
然而,如果观察各种不同的加速情况,我们会发现稀疏卷积加速和密集卷积加速之间存在显著差异。这一点可以表明 GPU 还需要优化稀疏卷积算法。
四、为何稀疏学习有效?
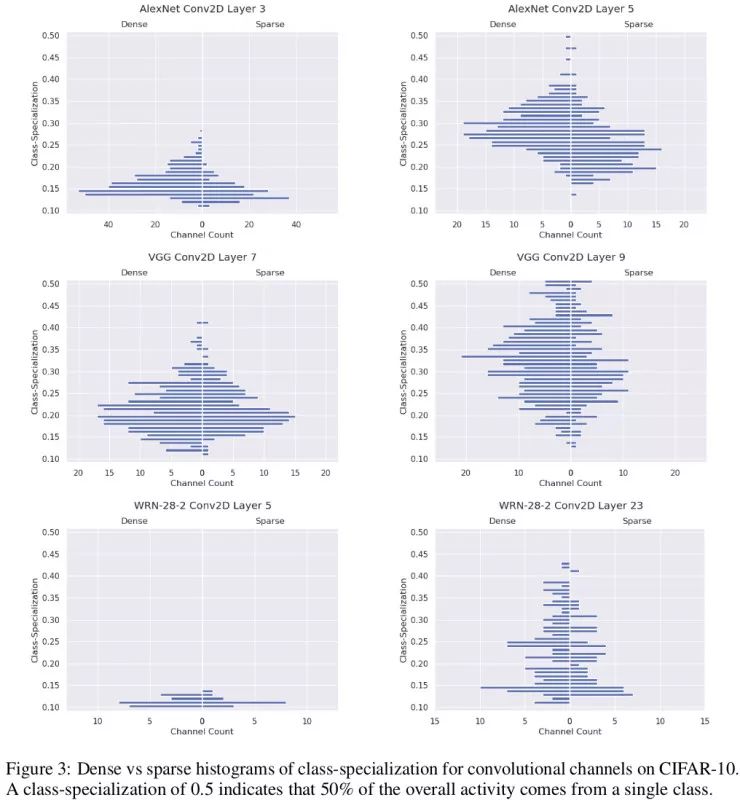
使用稀疏动量训练的一些稀疏网络,其性能与权重仅为 5%的密集网络训练结果相一致。是什么使这5%的权重如此有效,以至于它取得的效果与权重为其 20 倍的神经网络旗鼓相当?
为了探讨这个问题,我们比较了稀疏网络的特征与密集网络的特征。其中,低级特征可能包括边缘检测器之类的东西,中级特征可能是轮子、鼻子、眼睛、爪子,而高级特征可能为汽车的“脸”、猫的脸、冰箱门等。
为了减少特征数量,我们研究卷积通道(相当于卷积网络中的“神经元”)以及该通道对数据集中的类有多大作用。边缘检测器几乎对数据集中所有类都有效——换句话说,它们对于低级别的特征具有特定对应的类;对于中级特征,如眼睛,应该是对于比如猫,狗,和人类有用的类;而高级特性应该对一些选定的类有用,这些类都高度对应高级特征。
图 6: AlexNet、VGG16和WRN 28-2网络对应稀疏和密集网络的特化类直方图
我们发现,大体来说,稀疏网络可以学习对于更广泛的类有用的特征——不过更多情况下它们学习的是普遍的特征。这可能解释了为什么稀疏网络可以用 5%的权重来达到与密集网络相一致的性能。
五、稀疏学习的未来展望
我相信稀疏学习有一个非常光明的未来,这是因为:(1)GPU 在未来几年的性能将停滞不前;(2)用于稀疏工作负载的专用处理器 Graphcore 处理器即将问世。Graphcore 处理器将整个网络存储在它的300 MB缓存中,并将其加速大约 100 倍。
这意味着,如果我们可以在训练期间将网络压缩到 300 MB,那么我们的总体训练速度将提高100倍。使用一个 Graphcore 处理器在 ImageNet 上训练 ResNet-50 大约只需要15分钟。通过稀疏学习,网络大小为 300 MB的限制将不成问题。
我预测,第一个能够在 Graphcore 处理器上成功训练稀疏神经网络的研究团队,将开启一个全新水平的人工智能时代。
除此之外,另一个挑战是将稀疏学习算法应用于自然语言处理(NLP)。不出所料,我在自然语言处理任务转换器上的实验表明,与计算机视觉相比,稀疏学习在自然语言处理中要困难得多——未来我们需要做的工作还有很多!
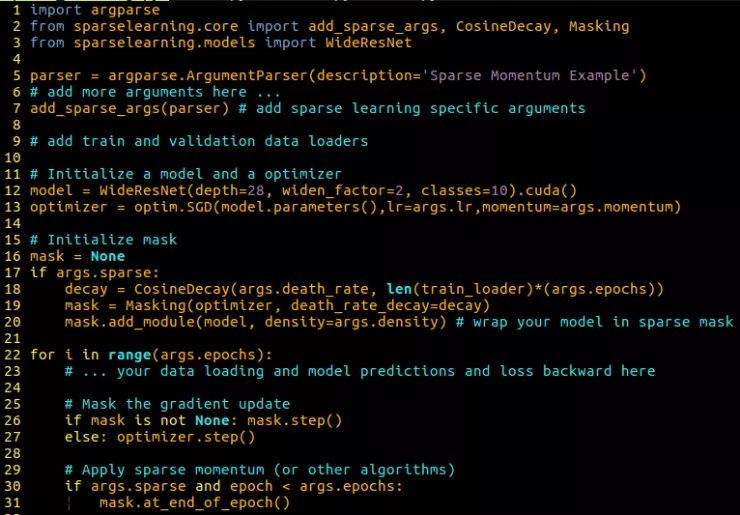
六、尝试使用 10 行代码亲自写稀疏动量模型!
图7:一个通用的稀疏学习脚本示例,您可以将其用于自己的模型。使用sparselearning库很容易使用稀疏动量:(1)导入库,(2)添加解析器选项,(3)用Masking类包装模型,(4)应用mask而不是优化器,(5)在迭代次数结束时应用稀疏动量。该库还可以通过自己的稀疏学习算法轻松地进行扩展,以实现增长、修剪或重分配——完成这一切只需仅仅几行代码!
为了让大家都能更深度地了解稀疏学习,我开发了一个稀疏学习的库,它能够让你将现有的算法如稀疏动量轻易得应用到你自己的模型上,并且能够用少于 10 行代码完成。这个库的设计还使得添加自己的稀疏学习方法变得非常容易。你可以通过以下地址前往GitHub查看这一开发库:
https://github.com/TimDettmers/sparse_learning
参考文献
Frankle, J. and Carbin, M. (2019). The lottery ticket hypothesis: Finding sparse, trainable neural networks. In ICLR 2019.
Han, S., Pool, J., Tran, J., and Dally, W. (2015). Learning both weights and connections for efficient neural network. In Advances in neural information processing systems, pages
1135—1143.
Herculano-Houzel, S., Mota, B., Wong, P., and Kaas, J.H. (2010). Connectivity-driven white matter scaling and folding in primate cerebral cortex. In Proceedings of the National Academy of Sciences of the United States of America, 107 44:19008—13.
via https://timdettmers.com/2019/07/11/sparse-networks-from-scratch/
![]() 点击“阅读原文”查看 解析周志华《机器学习》之特征选择与稀疏学习
点击“阅读原文”查看 解析周志华《机器学习》之特征选择与稀疏学习
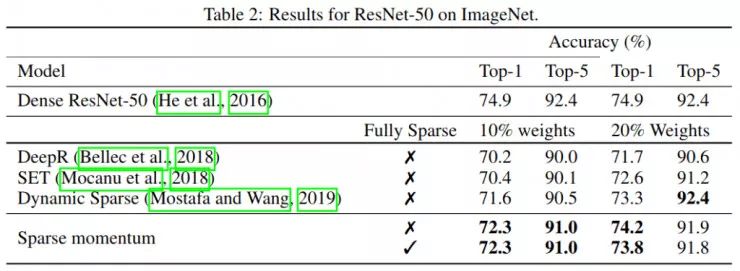 ImageNet下稀疏动量与相关方法的结果对比。在一个非全稀疏的模型中,第一层卷积层和所有下采样残差的连接从训练开始都是密集的。在一个全稀疏的网络设置中,所有层都是稀疏的。一般来说,稀疏动量比其他方法更有效,并且当所有权重都呈现为稀疏,与其他方法的效果相比,将几乎不分上下。这表明稀疏动量在寻找需要具有高密度的重要卷积层时是很有效的。
ImageNet下稀疏动量与相关方法的结果对比。在一个非全稀疏的模型中,第一层卷积层和所有下采样残差的连接从训练开始都是密集的。在一个全稀疏的网络设置中,所有层都是稀疏的。一般来说,稀疏动量比其他方法更有效,并且当所有权重都呈现为稀疏,与其他方法的效果相比,将几乎不分上下。这表明稀疏动量在寻找需要具有高密度的重要卷积层时是很有效的。