如何用张量分解加速深层神经网络?(附代码)

本文为雷锋字幕组编译的技术博客,原标题 Accelerating deep neural networks with tensor decompositions,作者为 Jacob。
翻译 | 林立宏 整理 | 凡江
背景
在这篇文章中,我将介绍几种低秩张量分解方法,用于在现有的深度学习模型中进行分层并使其更紧凑。我也将分享 PyTorch 代码,它使用 Tensorly(http://t.cn/REo7W8V ) 来进行在卷积层上的 CP 分解和 Tucker 分解。
尽管希望大部分帖子都是可以独立阅读的,关于张量分解的回顾可以在这里(http://t.cn/R5ZXkVo )找到。Tensorly 的作者也写了于 Tensor 的基础内容非常棒的 notebook(http://t.cn/REo7EyZ )。这帮助我很好的开始学习这块内容,建议你阅读一下这些内容。
加上裁剪(pruning),张量分解是加快现有深度神经网络的实用工具,我希望这篇文章能让这些内容更加容易理解。
这些方法需要将一个层分解成几个更小的层。尽管在分解后会有更多的层,但是浮点运算次数和权重的总数会变小。一些报告的结果是整个网络的 x8 倍的速度提升(不针对像 imagenet 这样的大型任务),或者 imagenet 中的特定层中 x4 倍的提升。我的结论是用这些分解方式,我能够获得 x2 到 x4 倍的加速,这取决于我愿意牺牲多少的精度。
在这篇文章(http://t.cn/RoaTgHT )中我介绍了一些称为裁剪(pruning)的技术以减少模型中的参数数量。在一个数据集上正向传递(有时是反向传递)裁剪(pruning),然后根据网络中激活的一些标准对神经元进行排序。
完全不同的是,张量分解的办法只用到层的权重,假设网络层是参数化的,它的权重能够用一个矩阵或者是一个低秩的张量来表示。这意味这个它们在参数化的网络下效果最佳。像 VGG 神经网络设计为完全参数化的。另外一个关于参数化模型的例子是使用更少的类别对网络进行微调以实现更简单的任务。
和裁剪(pruning)相似,分解之后通过模型需要微调来恢复准确性。
在我们会深入讨论细节之前,最后一件要说明的事是,虽然这些方法是实用的,并给出了很好的结果,但它们有一些缺点:
它们能够在一个线性权重上执行(比如一个卷积或者一个全连接的层),忽略了任何非线性的内容。
它们是贪婪,自认为聪明地分解层,忽略了不同层之间的相互作用。
目前还要试图解决这些问题,而且它仍然是一个活跃的研究领域。
截断 SVD 用于分解完全连接的层
第一份我能找到的使用这个来加速深度神经网络的是在 Fast-RNN 论文中,Ross Girshick 使用它来加速用于检测的全连接层。代码可以在这里找到:pyfaster-rcnn implementation(http://suo.im/4Gkl8I )。
SVD 概况
奇异值分解使我们能够分解任何具有 n 行和 m 列的矩阵 A:

S 是一个对角矩阵,其对角线上有非负值(奇异值),并且通常被构造成奇异值按降序排列的。U 和 V 是正交矩阵:
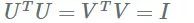
如果我们取最大的奇异值并将其余的归零,我们得到 A 的近似值:

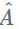
在全连接层上的 SVD
一个全连接层通常是做了矩阵乘法,输入一个矩阵 A 然后增加一个偏差 b:
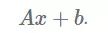
我们可以取 A 的 SVD,只保留第一个奇异值。
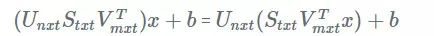
这不是一个完全连接的层,而是指导我们如何实现它作为两个较小的:
第一个将有一个 mxt 的形状,将没有偏差,其权重将取自
。
第二个将有一个 txn 的形状,将有一个等于 b 的偏差,其权重将取自
。
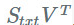
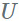
权重总数从 nxm 下降到 t(n + m)。
在卷积层上张量分解
二维卷积层是一个多维矩阵(后面用 - 张量),有四个维度:
cols x rows x input_channels x output_channels.
遵循 SVD 的例子,我们想要以某种方式将张量分解成几个更小的张量。卷积层转换为几个较小近似的卷积层。
为此,我们将使用两种流行的(至少在 Tensor 算法的世界中)张量分解:CP 分解和 Tucker 分解(也称为高阶 SVD 或其他名称)。
1412.6553 使用微调 CP 分解加速卷积神经网络
1412.6553 Speeding-up Convolutional Neural Networks Using Fine-tuned CP-Decomposition(https://arxiv.org/abs/1412.6553 ) 这篇论文说明了如果 CP 分解能够用于卷积层的加速,正如我们会看到的,这将卷积层纳入类似移动网络的东西。
他们使用它来加速网络的速度,而不会明显降低精度。在我自己的实验中,我可以使用这个在基于 VGG16 的网络上获得 x2 加速,而不会降低准确度。
我使用这种方法的经验是,需要非常仔细地选择学习率,微调以使其工作,学习率通常应该非常小(大约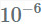
一个秩 R 矩阵可以被视为 R 秩和 1 矩阵的和,每个秩 1 矩阵是一个列向量乘以一个行向量:
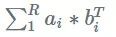
SVD 为我们提供了使用 SVD 中的 U 和 V 列来写矩阵和的方法:
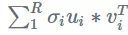
如果我们选择一个小于矩阵满秩的 R,那么这个和就是一个近似值,就像截断 SVD 的情况一样。
CP 分解让我们推广了张量。
使用 CP 分解,我们的卷积核,一个四维张量公式,可以近似为一个选定的 R:
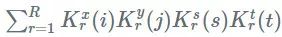
我们希望 R 对于有效的分解是小的,但是对保持近似高精度是足够大的。
带 CP 分解的卷积正向传递
为了传递图层,我们使用输入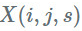
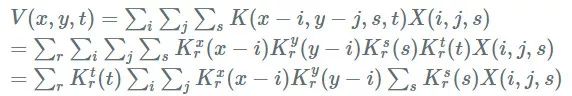
这给了我们一个办法来解决这个问题:
1. 首先做一个 wise(1x1xS)与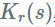
2. 用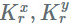
3. 做另一个逐点卷积来改变从 R 到 T 的通道数量如果原始卷积层有一个偏差,在这一点上加上它。
注意像在移动网中的逐点和深度卷积的组合。在使用 mobilenets 的时候,你必须从头开始训练一个网络来获得这个结构,在这里我们可以把现有的图层分解成这种形式。
与移动网络一样,为了获得最快的速度,需要一个有效实现深度可分离卷积的平台。
用 PyTorch 和 Tensorly 卷积层 CP 分解

1511.06530 用于快速和低功率移动应用的深度卷积神经网络的压缩
1511.06530 Compression of Deep Convolutional Neural Networks for Fast and Low Power Mobile Applications(https://arxiv.org/abs/1511.06530 ) 这一篇非常酷的论文,说明了如何使用 Tucker 分解来加速卷积层来得到更好的结果。我也在基于 VGG 的参数化网络用了这种加速,比 CP 分解的精度要好。作者在论文中指出,它可以让我们使用更高的学习率(我用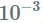
Tucker 分解也称为高阶奇异值分解(HOSVD)或者其他名称,是对张量进行奇异值分解的一种推广。
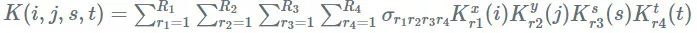
它认为 SVD 的推广的原因是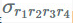
在上面描述的 CP 分解中,沿着空间维度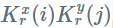
Trucker 分解有用的性质是,它不必沿着所有的轴(模式)分解。我们可以沿着输入和输出通道进行分解(模式 2 分解):
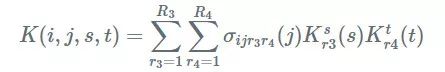
卷积正向传递与塔克分解
像 CP 分解一样,写一下卷积公式并插入内核分解:
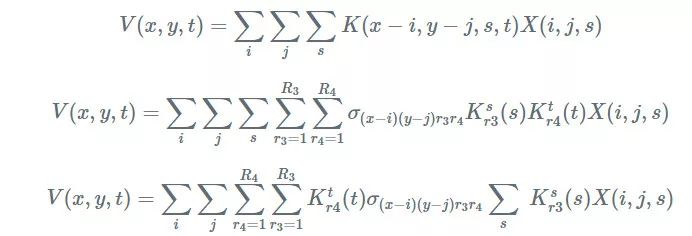
这给了我们以下用 Tucker 分解进行卷积的配方:
1. 与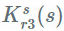
2. 用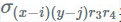
3. 用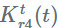
我们如何选择分解行列?
一种方法是尝试不同的值并检查准确性。尝试后的启发是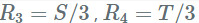
理想情况下,选择行列应该是自动的。
作者提出使用变分贝叶斯矩阵分解(VBMF)(Nakajima 等,2013,http://t.cn/REowSL3 )作为估计等级的方法。
VBMF 很复杂,不在本文的讨论范围内,但是在一个非常高层次的总结中,他们所做的是将矩阵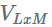
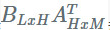
为了将其用于 Tucker 分解,我们可以展开原始权重张量的 s 和 t 分量来创建矩阵。然后我们可以使用 VBMF 估计
我用这个在 Python 上实现的 VBMF(http://t.cn/REowRAj ),相信它可以工作。
VBMF 通常返回的秩,非常接近我之前,仔细和乏味的手动调整得到的结果。
这也可以用于估计完全连接层的截断 SVD 加速的等级。
用 PyTorch 和 Tensorly 卷积层 Tucker 分解

总结
在这篇文章中,我们讨论了几个张量分解的方法来加速深度神经网络。
截断的 SVD 可用于加速完全连接的层。
CP 分解将卷积层分解成类似移动网络的东西,尽管它更具侵略性,因为它在空间维度上也是可分的。
Tucker 分解减少了二维卷积层操作的输入和输出通道的数量,并且使用逐点卷积来切换 2D 卷积之前和之后的通道数量。
我觉得有趣的是网络设计中的常见模式,逐点和深度卷积,自然而然出现在这些分解中!
博客原址 https://jacobgil.github.io/deeplearning/tensor-decompositions-deep-learning
更多文章,关注 AI 研习社,添加雷锋字幕组微信号(leiphonefansub)为好友
备注「我要加入」,To be a AI Volunteer !

NLP 工程师入门实践班:基于深度学习的自然语言处理
三大模块,五大应用,手把手快速入门 NLP
海外博士讲师,丰富项目经验
算法 + 实践,搭配典型行业应用
随到随学,专业社群,讲师在线答疑
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
如何运用深度学习进行位姿测量?
▼▼▼



