OpenAI:无监督训练加微小调整,只用一个模型即可解决多种NLP任务
编者按:近日,OpenAI在博客上宣布,他们用可扩展的多任务系统,在多语言任务上取得了良好的成绩。研究人员结合了transformer和无监督预训练这两种现有方法。结果证明,监督学习方法和无监督预训练结合得非常好。以下是论智对原博文的编译。
我们的系统工作分为两个阶段:首先,我们在大量数据上训练一个transformer模型,利用语言建模作为训练信号,然后在稍小的监督数据集上对模型进行微调,以帮助解决特殊任务。
在此之前我们曾发布了一篇有关“情感神经元”的研究,其中我们注意到无监督学习技术能产生非常明显的特定。这里,我们想将这一技术进一步拓展:是否能创建一个模型,将其在大量数据上进行无监督训练,之后再在多种不同任务上进行微调?结果证明,这一方法非常有效。模型只需要微小调整就能适应多种任务。
这项工作建立在论文Semi-supervised Sequence Learning所提出的方法上,它展示了如何用LSTM的无监督预训练以及监督式的微调提高文本分类的性能。它还扩展了ULMFiT,该研究展示了单一无数据集的LSTM语言模型可以在多种文本分类数据集上微调后达到最优性能。
而我们的研究展示了一个基于Transformer的模型可以通过这种方法做到除了文本分类以外的事,例如常识推理、语义相似度、阅读理解。它也有点像ELMo,同样也是加入预训练,再用特定任务框架得到最优结果。
为了达到我们的结果只需要微调,并且所有数据集只用了一个前向语言模型,没有任何集成,并且大部分结果用的参数都是相通的。
令人激动的是,我们的方法在COPA、RACE和ROCStories三个数据集上都表现的很好,这三种数据集是用来测试常识推理和阅读理解的。我们的模型在这些数据集上表现出了顶尖的结果,与其他方法的对比十分明显。通常人们认为这些数据集需要多语句推理和丰富的知识,这也表明我们的模型只能靠无监督学习提升水准。这也意味着未来也许能通过无监督技术让模型理解复杂语言。
为什么用无监督学习?
监督学习最近在机器学习的很多方面都取得了成功。然而,成功的背后需要大型、经过清洗的数据集。无监督学习不会有这些问题,也是它受欢迎的原因。由于无监督学习无需人类对数据进行标注,所以在目前计算量增加并且有可用元数据的趋势下,它仍然适应得很好。无监督学习是很受欢迎的研究领域,但是付诸实践的却很少。
最近我们尝试用无监督学习增强系统,进一步研究语言能力。无监督技术训练能通过含有巨大信息量的数据库训练单词的表示,与监督学习结合后,模型的性能会进一步提高。最近,这些NLP领域的无监督技术(例如GLoVe和word2vec)利用了简单模型(词向量)和训练信号。Skip-Thought向量是一种是对这种提升的早期展示。但是目前在用的技术让性能得到了进一步提升。这些都包括了使用预训练句子的模型表示、语境化的词向量、用定制架构连接无监督预训练和监督微调的方法。
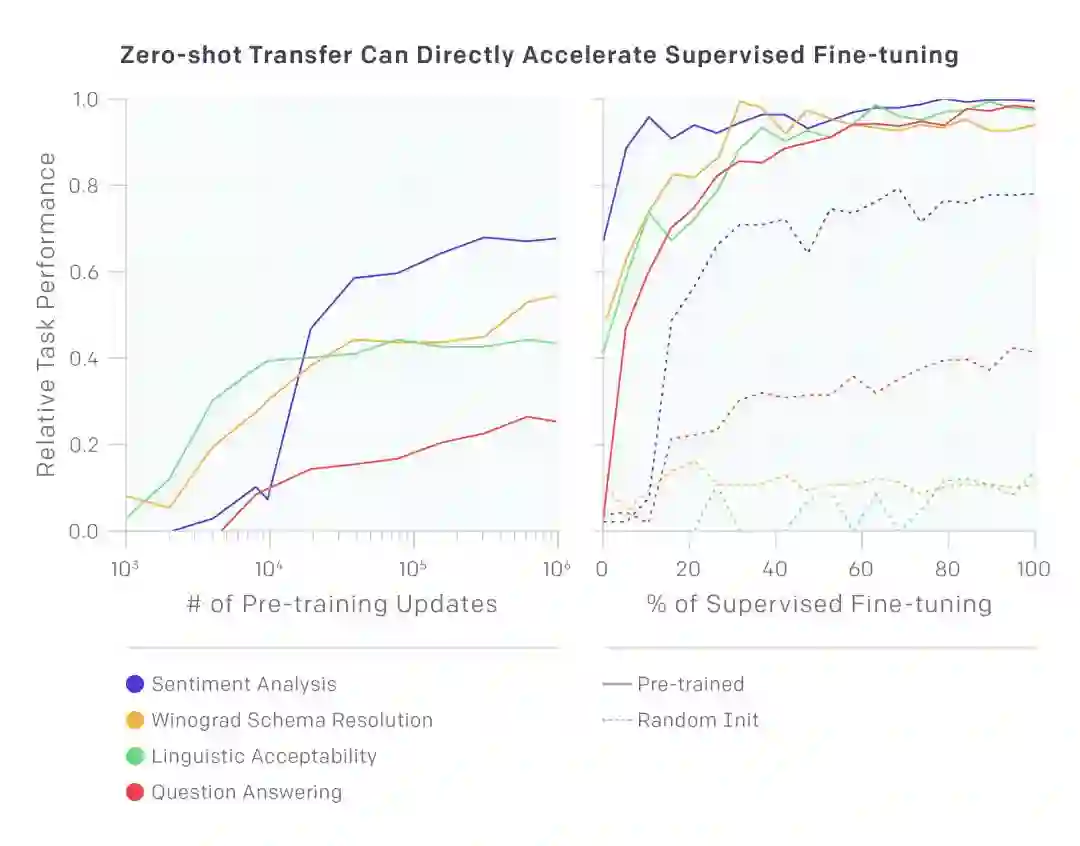
在大量文本语料上对模型进行预训练显著提高了它在自然语言处理上的表现
我们还注意到,我们可以用基础的语言模型直接执行任务,不用训练它们。例如,随着基础语言模型的升级,选择题模型的表现也有了提升。虽然这种方法和监督方法相比结果还是有差距,但是无监督学习方法能在多种任务上执行任务已经很让人兴奋了。
我们还能用模型中现有的语言功能执行情感分析。斯坦福的Sentiment Treebank数据集中包含了许多积极和消极的电影评论,如果在一句话的结尾添加“very”这个词,我们可以用语言模型猜测评论的属性。这种方法完全没用对模型进行适应调整,最终达到了约80%的准确度。
我们的方法也是验证transformer架构的鲁棒性和有用性的标准,这说明想在多种任务上达到顶尖的结果,同时不需要定制化或调参是非常灵活的。
目前存在的缺点
这一项目同时还存在着一些不足之处:
计算需求:此前NLP任务中的许多方法都是从零开始在单个GPU上训练,模型比较小。我们的方法在预训练时需要一个月左右的时间,并且要用8个GPU。幸运的是,预训练只要做一次。不过跟之前的其他工作相比,这算是比较大的计算量和内存了。我们用了一个37层的Transformer架构,训练了最多有512个token的序列,大多数都是在4个或8个GPU系统上进行的。模型可以快速地针对新问题进行微调,这也减少了额外所需要的资源。
在学习时通过文本对世界的理解有偏差和偏见:网络上所能看见的书或文字也许不能涵盖世界所有的信息,也许不准确。最近的研究表明,用文本和通过数据分布建立的模型学习特定的信息很困难。
生成时很脆弱:虽然我们的方法在很多任务中都提高了性能,目前的深度学习NLP模型仍然表现出令人惊讶的反常行为,尤其是系统地进行对抗测试时更加明显。但是我们的方法在这些测试面前很脆弱,尽管有一些进步。对比之前完全用神经网络的方法,我们的方法在词汇鲁棒性上更胜一筹。在Glockner等人的数据集上,我们的模型达到了83.75%的方法,和KIM接近。
未来方向
扩展我们的方法:我们看到在语言模型和其相关的模型上已经有了很大提升。目前我们正在用一个8个GPU的机器和含有上千本书的训练集进行实验,说明还有很大的扩展空间。
改进微调方法:我们的方法目前很简洁。也许未来我们会用更加复杂的调整和迁移技术进行改进。
深入了解为什么生成预训练很有帮助:虽然我们对研究成果做出了解释,但是只有对比其他实验和研究才能有更清晰的认知。例如,技术提升后到底有多少好处?
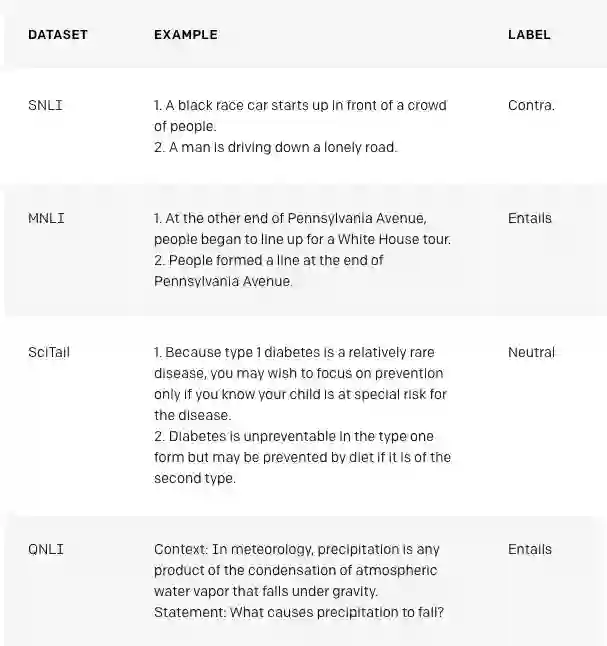
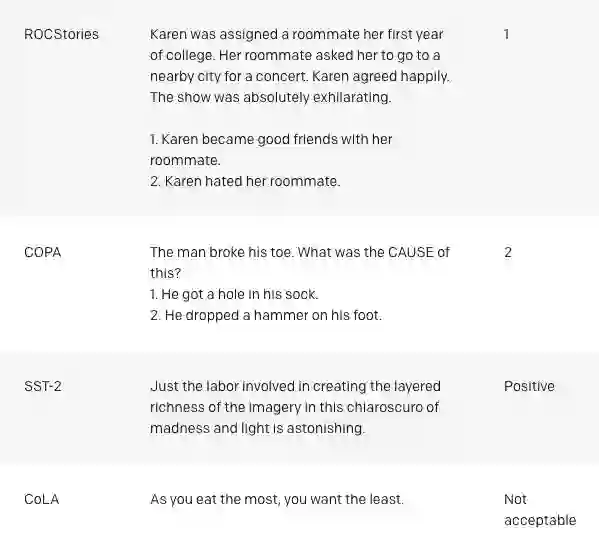
具体案例
扩展我们的方法:我们看到在语言模型和其相关的模型上已经有了很大提升。目前我们正在用一个8个GPU的机器和含有上千本书的训练集进行实验,说明还有很大的扩展空间。
改进微调方法:我们的方法目前很简洁。也许未来我们会用更加复杂的调整和迁移技术进行改进。
深入了解为什么生成预训练很有帮助:虽然我们对研究成果做出了解释,但是只有对比其他实验和研究才能有更清晰的认知。例如,技术提升后到底有多少好处?
具体案例

原文地址:blog.openai.com/language-unsupervised/#content


