【分享】TCSVT 2021丨基于3D人脸动态的图像-视频生成方法

摘要
背景及简介
当前的人脸视频生成方法普遍采用人脸的稀疏特征点(landmarks)来引导图片或视频的生成,然而作者认为使用稀疏的二维特征点引导人脸图像/视频生成的主要缺点有:1、稀疏人脸特征点不能很好地表示人脸图像的几何形状,容易导致人脸整体形状和面部结构细节的缺失,进而导致合成图像的失真和质量损失;2、稀疏的二维特征点不携带源人脸图像的任何内容信息,这可能会导致生成的图像过拟合于只包含训练集的人脸图像中;3、在视频生成过程中应保留人脸身份信息,但稀疏的2D特征点没有身份信息,容易导致合成结果的身份变化。
文章的主要贡献如下:
不同于广泛使用2D稀疏人脸landmarks进行图像/视频的引导生成,文章主要探索包含人脸丰富信息的3D动态信息的人脸视频生成任务;
设计了一个三维动态预测网络(3D Dynamic Prediction,3DDP)来预测时空连续的3D动态序列;
提出了一个稀疏纹理映射算法来渲染预测的3D动态序列,并将其作为先验信息引导人脸图像/视频的生成;
文章使用随机和可控的两种方式进行视频的生成任务,验证提出方法的有效性。
方法描述
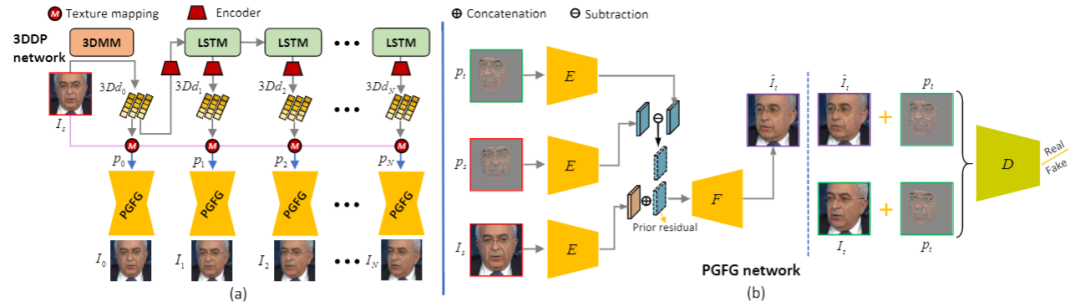
(1)3D人脸重建和稀疏纹理映射
3D形变模型(3D Morphable Model, 3DMM)用来从2D人脸图像中预测相应的3D人脸。其中,描述3D人脸的顶点(vertex)可由一系列2D人脸中的正交基线性加权得出:
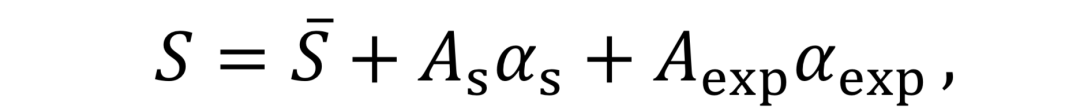
其中,
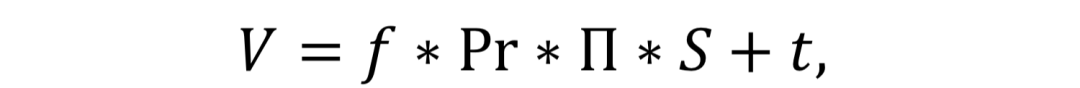
其中,V表示3D顶点在2维平面上的映射坐标,
如图2所示,给定一张源人脸图像(Source Face),其3D形状可以通过改变重建的 3DMM 系数来进行任意的修改, 则目标人脸的稀疏纹理可以由修改后的3DMM 系数获得。在人脸重定向任务中,修改的 3DMM 系数可由参考人脸视频帧得到,而在人脸预测任务中,则由 LSTM 模块预测得到。为了防止在纹理映射中,密集的纹理先验信息太强而导致目标动作中出现不符合期望的结果,因此在纹理映射过程中本文采用间隔采样即稀疏纹理映射,以适应不同的人脸运动变化。
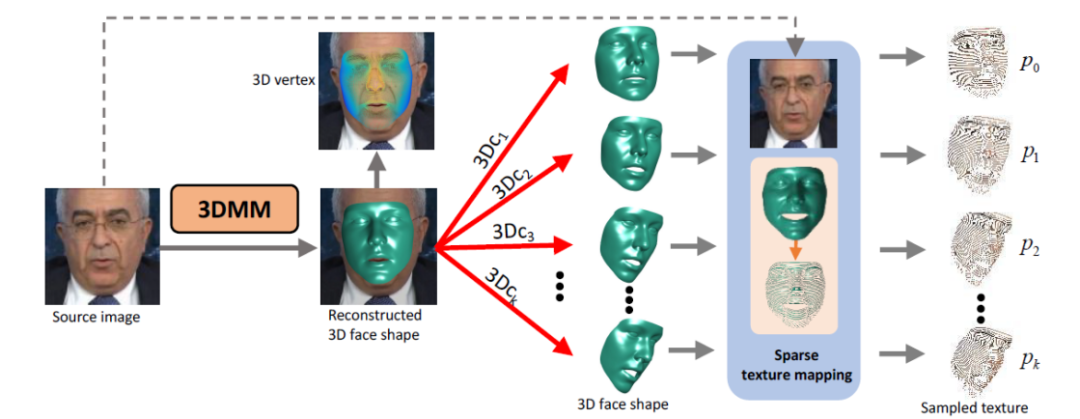
图2. 给定不同的3DMM系数所得到的不同三维人脸重建和稀疏映射的结果
视频预测:给定一个观测到的动态序列(3DMM coefficients),LSTM对其进行编码:
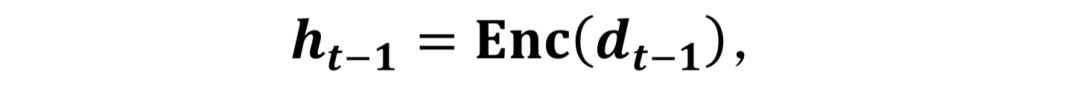
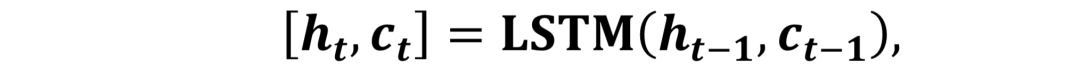
为了预测出一个合理的动作,LSTM不得不首先学习大量的动作输入以识别在姿态序列中运动的种类以及随时间的变化。在训练过程中,未来动态序列可以由下式生成:
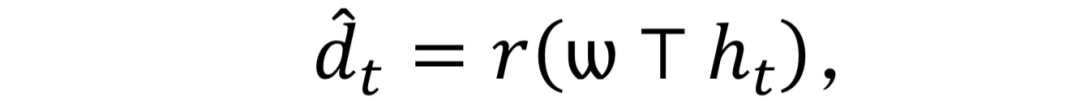
其中
目标驱动的视频预测: 对于LSTM来讲,要实现目标引导的运动生成,模型需要两个输入,即source dynamic和target dynamic。不同于视频预测,作者使用了一个计时器来对target dynamic进行重新赋权。整体的LSTM预测可以用公式表示为:
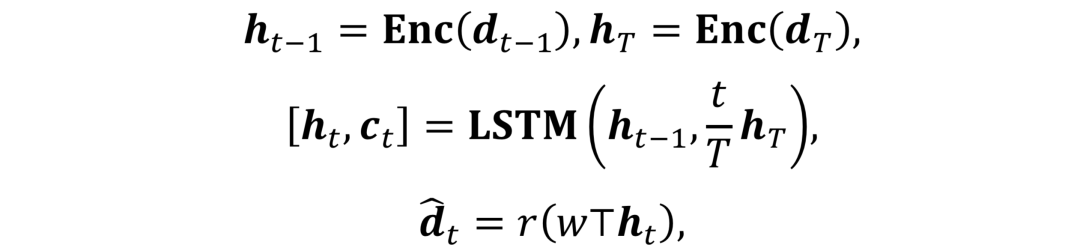
这里
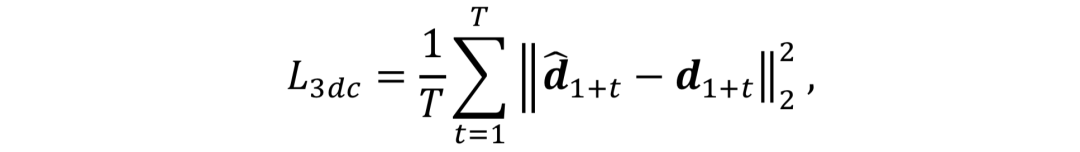
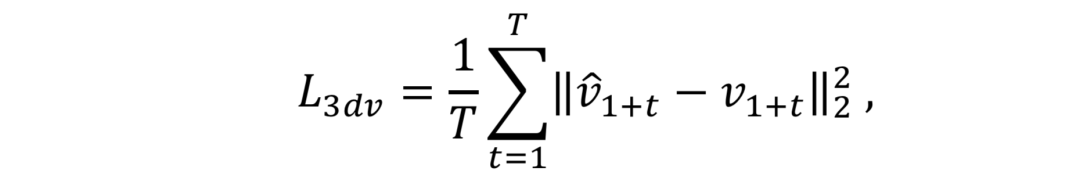
其中
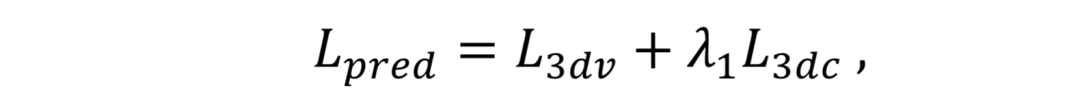
先验引导的人脸生成: 基于提出的稀疏纹理映射,source人脸图像被用于渲染预测的3D dynamics。在这里,稀疏纹理作为引导人脸生成的先验信息。文中提到的网络PGFG (Prior-Guided Face Generation Network)主要由条件GAN网络来组成,其结构如图1(右)所示。
PGFG 网络的结构:PGFG生成器G有三个输入,分别是source人脸
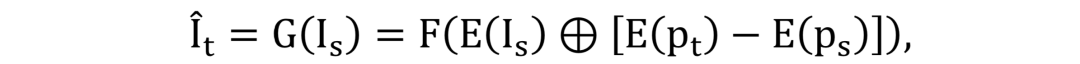
为了进一步利用不同空间位置的特征信息,编码器和解码器均由Dense blocks组成。判别器有两个输入,即目标人脸图像的纹理先验分别和生成人脸、目标人脸结合的输入
损失函数:网络PGFG由三个损失函数进行监督,分别为图像像素间的损失
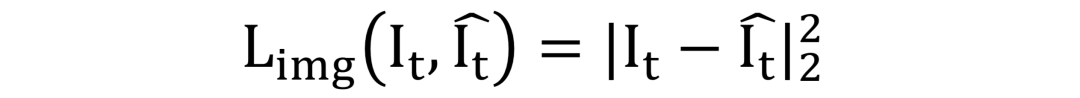
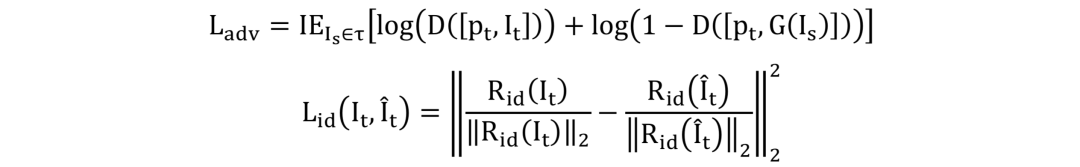
需要注意的是,在身份信息损失中,R为预训练的人脸识别模型。网络整体的损失函数为:
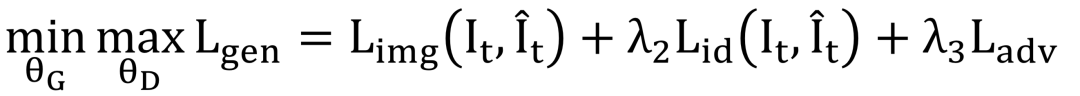
实验结果
作者分别对人脸视频重定向、视频预测以及目标驱动的视频预测三个任务做了相应的大量实验。
人脸视频重定向:在这个任务中,作者分别对人脸表情的重定向以及头部讲话重定向两个子任务进行了实验。实验表明,所提出的 FaceAnime 模型可以很好的将 source人脸图像中的表情和动作重定向到目标图像上,生成相对应的姿态和讲话表情,实验结果如图3 所示。

图 3. FaceAnime的人脸表情重定向(a)和头部讲话重定向(b)实验结果
人脸视频预测:这个任务中包含视频预测以及目标驱动的视频预测两个子任务。对每一个预测任务,实验过程中作者随机选取一张从人脸图像测试集 IJB-C 中抽取的单张人脸图像。对于视频测试,作者首先使用 3DDP 网络从source 人脸中预测一个运动序列,然后用该序列引导人脸视频的生成。而对于目标引导的人脸预测任务,则需要两个输入图像。一个是 source人脸,另一个为 target人脸。3DDP 网络用于预测从 source人脸到 target人脸之间平滑的运动变化,从而引导人脸视频的生成。图4和图5分别展示了视频生成和目标驱动视频生成两个子任务的生成结果。
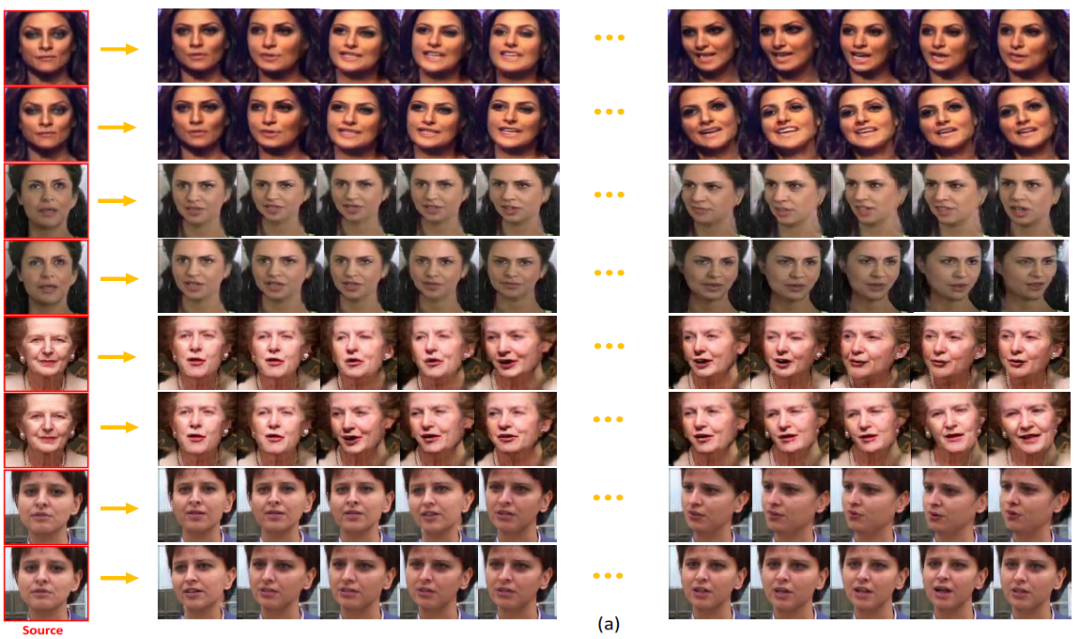 图 4. FaceAnime的视频生成结果
图 4. FaceAnime的视频生成结果
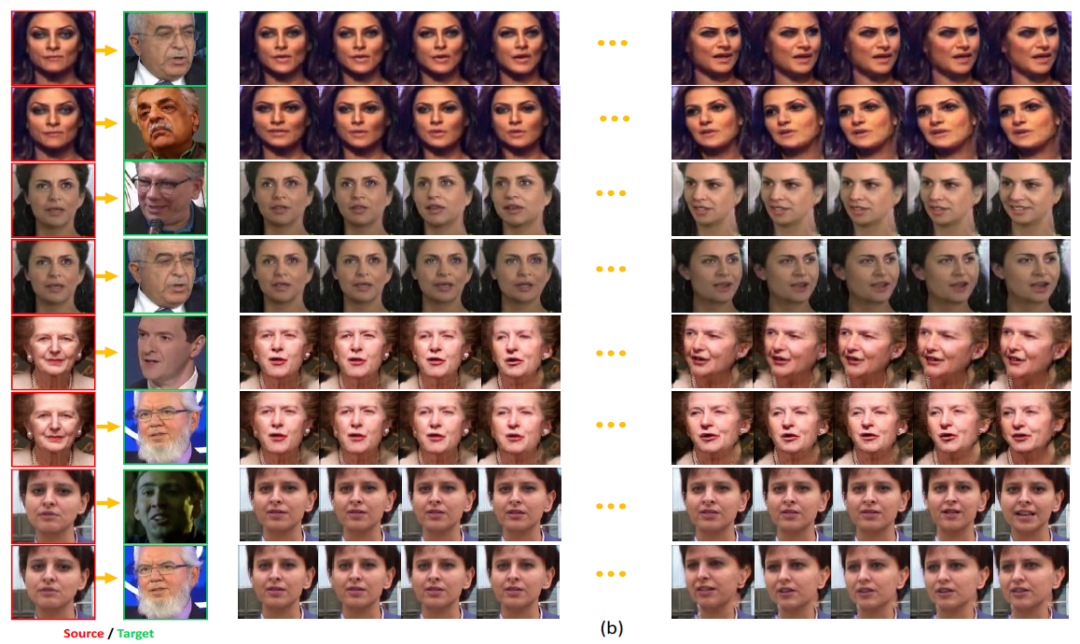
为了展示所提出方法的先进性,作者还同其他类似任务的算法进行了效果对比,部分结果显示如图 6 所示。

通过比较,FaceAnime不仅可以生成高质量且真实的人脸视频序列,同时生成的视频图像可以精确地还原参考视频中人脸表情和姿态变化,还能较好地保持人脸的身份信息。
大量实验表明,作者提出的方法可以将参考视频的姿态和表情变化重定位到 source人脸上,并且对于一个随机的人脸图像,其可以生成合理的未来视频序列。对比其他最先进的人脸生成方法,所提出的方法在生成高质量和身份信息保持的人脸方面具有更好的效果。
参考文献
[1] Tu X, Zhao J, Xie M, et al. 3d face reconstruction from a single image assisted by 2d face images in the wild[J]. IEEE Transactions on Multimedia, 2020, 23: 1160-1172.
[2] B. Maze, J. Adams, J. A. Duncan, N. Kalka, T. Miller, C. Otto, A. K. Jain, W. T. Niggel, J. Anderson, J. Cheney, et al., Iarpa janus benchmarkc: Face dataset and protocol, in: ICB, IEEE, 2018, pp. 158–165.
[3] T.-C. Wang, M.-Y. Liu, J.-Y. Zhu, A. Tao, J. Kautz, B. Catanzaro, Highresolution image synthesis and semantic manipulation with conditional gans, in: CVPR, 2018, pp. 8798–8807.
[4] O. Wiles, A. Sophia Koepke, A. Zisserman, X2face: A network for controlling face generation using images, audio, and pose codes, in: ECCV, 2018, pp. 670–686.
[5] Y. Nirkin, Y. Keller, T. Hassner, Fsgan: Subject agnostic face swapping and reenactment, in: ICCV, 2019, pp. 7184–7193.





