![]()
如果你是一名机器学习从业者,一定不会对基于梯度下降的优化方法感到陌生。对于很多人来说,有了 SGD,Adam,Admm 等算法的开源实现,似乎自己并不用再过多关注优化求解的细节。然而在模型的优化上,梯度下降并非唯一的选择,甚至在很多复杂的优化求解场景下,一些非梯度优化方法反而更具有优势。而在众多非梯度优化方法中,演化策略可谓最耀眼的那颗星!
对于深度学习模型的优化问题来说,随机梯度下降(SGD)是一种被广为使用方法。然而,实际上 SGD 并非我们唯一的选择。当我们使用一个「黑盒算法」时,即使不知道目标函数 f(x):Rn→R 的精确解析形式(因此不能计算梯度或 Hessian 矩阵)你也可以对 f(x) 进行评估。经典的黑盒优化方法包括「模拟退火算法」、「爬山法」以及「单纯形法」。演化策略(ES)是一类诞生于演化算法(EA)黑盒优化算法。在本文中,我们将深入分析一些经典的演化策略方法,并介绍演化策略在深度强化学习中的一些应用。
目录
1、均值更新
2、步长控制
3、协方差自适应
1、自然梯度
2、使用费舍尔(Fisher)信息矩阵进行估计
3、NES 算法
1、OpenAI 用于强化学习的演化策略
2、演化策略的探索方式
3、 CEM-RL:结合演化策略和梯度下降方法的强化学习策略搜索
1、超参数调优:PBT
2、网络拓扑优化:WANN
一、演化策略是什么?
演化策略(ES)从属于演化算法的大家族。ES 的优化目标是实数向量 x∈Rn。
演化算法(EA)指的是受自然选择启发而产生的一类基于种群的优化算法。自然选择学说认为,如果某些个体具有利于他们生存的特性,那么他们就可能会繁衍几代,并且将这种优良的特性传给下一代。演化是在选择的过程中逐渐发生的,整个种群会渐渐更好地适应环境。
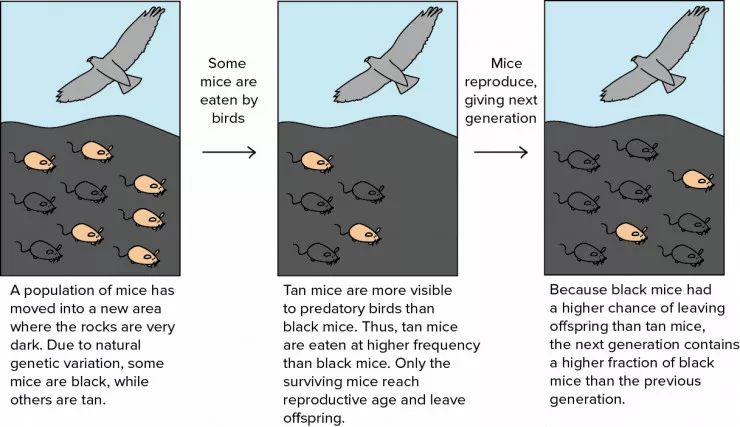
图 1:自然选择工作原理示意图(图片来源:可汗学院「达尔文、进化与自然选择」:https://www.khanacademy.org/science/biology/her/evolution-and-natural-selection/a/darwin-evolution-natural-selection)。
(左)一群老鼠移动到了一个岩石颜色非常暗的地区。由于自然遗传的变异,有些老鼠毛色是黑色,有的则是棕褐色。(中)相较于黑色的老鼠来说,棕褐色的老师更容易被肉食性鸟类发现。因此,褐色老鼠比黑色老鼠更频繁地被鸟类捕食。只有存活下来的老鼠到了生育年龄后会留下后代。(右)由于黑色老鼠比褐色老鼠留下后代的机会更大,在下一代老鼠中黑色的占比上一代更高。
我们可以通过以下方式将演化算法概括为一种通用的优化方案:
假设我们想要优化一个函数 f(x),而且无法直接计算梯度。但是,我们在给定任意 x 的情况下仍然可以评估 f(x),而且得到确定性的结果。我们认为随机变量 x 的概率分布 pθ(x) 是函数 f(x) 优化问题的一个较优的解,θ 是分布 pθ(x) 的参数。目标是找到 θ 的最优设置。
在给定固定分布形式(例如,高斯分布)的情况下,参数 θ 包含了最优解的知识,在一代与一代间进行迭代更新。
假设初始值为 θ,我们可以通过循环进行下面的三个步骤持续更新 θ:
-
1. 生成一个样本的种群 D={(xi,f(xi)},其中 xi∼pθ(x)。
-
-
3. 根据适应度或排序,选择最优的个体子集,并使用它们来更新 θ。
在遗传算法(GA,另一种流行的演化算法子类)中,x 是二进制编码的序列,其中 x∈{0,1}n。但是在演化策略中,x 仅仅是一个实数向量,x∈Rn。
二、简单的高斯演化策略
高斯演化策略是最基础、最经典的演化策略(相关阅读可参考:http://blog.otoro.net/2017/10/29/visual-evolution-strategies/)。它将 pθ(x) 建模为一个 n 维各向同性的高斯分布,其中 θ 仅仅刻画均值 μ 和标准差 σ。
1. 初始化 θ=θ(0) 以及演化代数计数器 t=0。
2. 通过从高斯分布中采样生成大小为 Λ 的后代种群:
3. 选择出使得 f(xi) 最优的 λ 个样本组成的子集,该子集被称为「精英集」。为了不失一般性,我们可以考虑 D(t+1) 中适应度排名靠前的 k 个样本,将它们放入「精英集」。我们可以将其标注为:
4. 接着,我们使用「精英集」为下一代种群估计新的均值和标准差:
三、协方差矩阵自适应演化策略(CMA-ES)
标准差 σ 决定了探索的程度:当 σ 越大时,我们就可以在更大的搜索空间中对后代种群进行采样。在简单高斯演化策略中,σ(t+1) 与 σ(t) 密切相关,因此算法不能在需要时(即置信度改变时)迅速调整探索空间。
「协方差矩阵自适应演化策略」(CMA-ES)通过使用协方差矩阵 C 跟踪分布上得到的样本两两之间的依赖关系,解决了这一问题。新的分布参数变为了:
其中,σ 控制分布的整体尺度,我们通常称之为「步长」。
在我们深入研究 CMA-ES 中的参数更新方法前,不妨先回顾一下多元高斯分布中协方差矩阵的工作原理。作为一个对称阵,协方差矩阵 C 有下列良好的性质(详见「Symmetric Matrices and Eigendecomposition」:http://s3.amazonaws.com/mitsloan-php/wp-faculty/sites/30/2016/12/15032137/Symmetric-Matrices-and-Eigendecomposition.pdf;以及证明:http://control.ucsd.edu/mauricio/courses/mae280a/lecture11.pdf):
令矩阵 C 有一个特征向量 B=[b1,...,bn] 组成的标准正交基,相应的特征值分别为 λ12,…,λn2。令 D=diag(λ1,…,λn)。
yi(t)∈Rn:xi(t)=μ(t−1)+σ(t−1)yi(t)
D(t):对角线上的元素为 C 的特征值的对角矩阵
αcλ:矩阵 C 的秩 min(λ, n) 更新的学习率
CMA-ES 使用 αμ≤1 的学习率控制均值 μ 更新的速度。通常情况下,该学习率被设置为 1,从而使上述等式与简单高斯演化策略中的均值更新方法相同:
参数 σ 控制着分布的整体尺度。它是从协方差矩阵中分离出来的,所以我们可以比改变完整的协方差更快地改变步长。步长较大会导致参数更新较快。为了评估当前的步长是否合适,CMA-ES 通过将连续的移动步长序列相加
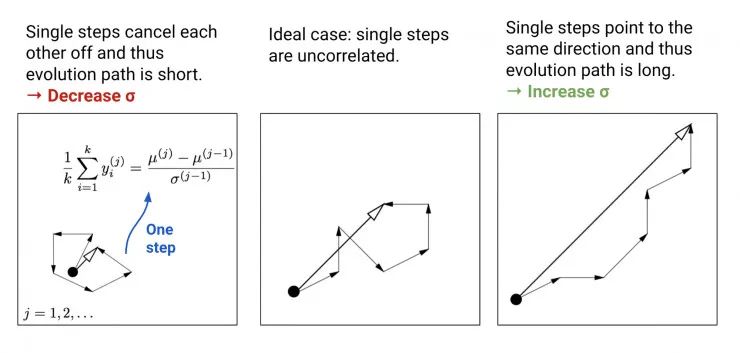
![]() ,构建了一个演化路径(evolution path)pσ。通过比较该路径与随机选择(意味着每一步之间是不相关的)状态下期望会生成的路径长度,我们可以相应地调整 σ(详见图 2)。
图 2:将每一步演化以不同的方式关联起来的三种情况,以及它们对步长更新的影响。(左)每个步骤之间互相抵消,因此演化路径很短。(中)理想情况:每个步骤之间并不相关。(右)每个步骤指向同一个方向,因此演化路径较长。(图片来源:CMA-ES 教程论文中图 5 的附加注释,https://arxiv.org/abs/1604.00772)
每次演化路径都会以同代中的平均移动步长 yi 进行更新。
,构建了一个演化路径(evolution path)pσ。通过比较该路径与随机选择(意味着每一步之间是不相关的)状态下期望会生成的路径长度,我们可以相应地调整 σ(详见图 2)。
图 2:将每一步演化以不同的方式关联起来的三种情况,以及它们对步长更新的影响。(左)每个步骤之间互相抵消,因此演化路径很短。(中)理想情况:每个步骤之间并不相关。(右)每个步骤指向同一个方向,因此演化路径较长。(图片来源:CMA-ES 教程论文中图 5 的附加注释,https://arxiv.org/abs/1604.00772)
每次演化路径都会以同代中的平均移动步长 yi 进行更新。
通过与 C-1/2 相乘,我们将演化路径转化为与其方向相独立的形式。
![]() 的工作原理如下:
1. B(t) 包含 C 的特征向量的行向量。它将原始空间投影到了正交的主轴上。
2.
的工作原理如下:
1. B(t) 包含 C 的特征向量的行向量。它将原始空间投影到了正交的主轴上。
2.
![]() 将各主轴的长度放缩到相等的状态。
将各主轴的长度放缩到相等的状态。
为了给最近几代的种群赋予更高的权重,我们使用了「Polyak平均 」算法(平均优化算法在参数空间访问轨迹中的几个点),以学习率 ασ 更新演化路径。同时,我们平衡了权重,从而使pσ 在更新前和更新后都为服从 N(0,I) 的共轭分布(更新前后的先验分布和后验分布类型相同)。
随机选择得到的Pσ 的期望长度为 E‖N(0,I)‖,该值是服从 N(0,I) 的随机变量的 L2 范数的数学期望。按照图 2 中的思路,我们将根据 ‖pσ(t+1)‖/E‖N(0,I)‖ 的比值调整步长:
其中,dσ≈1 是一个衰减参数,用于放缩 lnσ 被改变的速度。
我们可以使用精英样本的 yi 从头开始估计协方差矩阵(yi∼N(0,C))
只有当我们选择出的种群足够大,上述估计才可靠。然而,在每一代中,我们确实希望使用较小的样本种群进行快速的迭代。这就是 CMA-ES 发明了一种更加可靠,但同时也更加复杂的方式去更新 C 的原因。它包含两种独立的演化路径:
-
秩 min(λ, n) 更新:使用 {Cλ} 中的历史,在每一代中都是从头开始估计的。
-
秩 1 更新:根据历史估计移动步长 yi 以及符号信息
第一条路径根据 {Cλ} 的全部历史考虑 C 的估计。例如,如果我们拥有很多代种群的经验,
就是一种很好的估计方式。类似于 pσ,我们也可以使用「polyak」平均,并且通过学习率引入历史信息:
第二条路径试图解决 yiyi⊤=(−yi)(−yi)⊤ 丢失符号信息的问题。与我们调整步长 σ 的方法相类似,我们使用了一个演化路径 pc 来记录符号信息,pc 仍然是种群更新前后都服从于 N(0,C) 的共轭分布。
我们可以认为 pc 是另一种计算 avgi(yi) 的(请注意它们都服从于 N(0,C)),此时我们使用了完整的历史信息,并且能够保留符号信息。请注意,在上一节中,我们已经知道了
![]() ,pc的计算方法如下:
当 k 较小时,秩 1 更新方法相较于秩 min(λ, n) 更新有很大的性能提升。这是因为我们在这里利用了移动步长的符号信息和连续步骤之间的相关性,而且这些信息可以随着种群的更新被一代一代传递下去。
在上面所有的例子中,我们认为每个优秀的样本对于权重的贡献是相等的,都为 1/λ。该过程可以很容易地被扩展至根据具体表现为抽样得到的样本赋予不同权重 w1,…,wλ 的情况。详情请参阅教程:「The CMA Evolution Strategy: A Tutorial」(https://arxiv.org/abs/1604.00772)
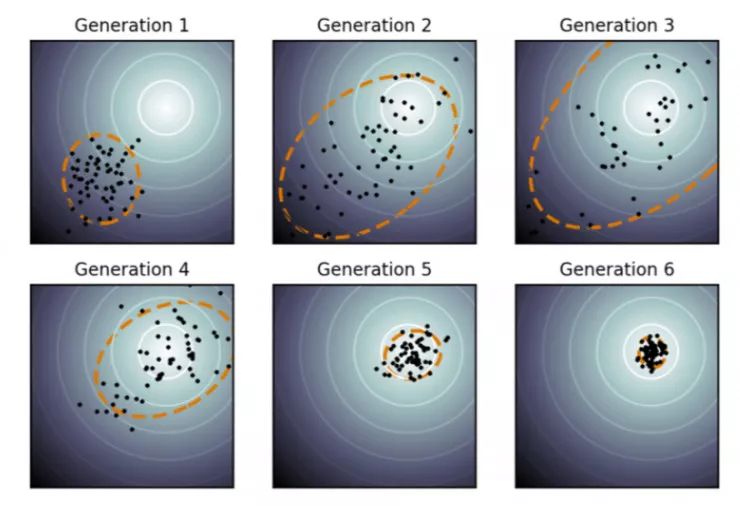
图 3:CMA-ES 在二维优化问题上的工作原理示意图(颜色越亮的部分性能越好)。黑点是当前代中的样本。样本在初始阶段较分散,但当模型在后期较有信心找到较好的解时,样本在全局最优上变得非常集中。样本在初始阶段较分散,但当模型在后期以更高的置信度找到较好的解时,样本会集中于全局最优点。
,pc的计算方法如下:
当 k 较小时,秩 1 更新方法相较于秩 min(λ, n) 更新有很大的性能提升。这是因为我们在这里利用了移动步长的符号信息和连续步骤之间的相关性,而且这些信息可以随着种群的更新被一代一代传递下去。
在上面所有的例子中,我们认为每个优秀的样本对于权重的贡献是相等的,都为 1/λ。该过程可以很容易地被扩展至根据具体表现为抽样得到的样本赋予不同权重 w1,…,wλ 的情况。详情请参阅教程:「The CMA Evolution Strategy: A Tutorial」(https://arxiv.org/abs/1604.00772)
图 3:CMA-ES 在二维优化问题上的工作原理示意图(颜色越亮的部分性能越好)。黑点是当前代中的样本。样本在初始阶段较分散,但当模型在后期较有信心找到较好的解时,样本在全局最优上变得非常集中。样本在初始阶段较分散,但当模型在后期以更高的置信度找到较好的解时,样本会集中于全局最优点。
四、自然演化策略
自然演化策略(Wierstra 等人于 2008 年发表的 NES,论文地址:https://arxiv.org/abs/1106.4487)在参数的搜索分布上进行优化,并将分布朝着自然梯度所指向的高适应度方向移动。
给定一个参数为 θ 的目标函数 J(θ),我们的目标是找到最优的 θ,从而最大化目标函数的值。朴素梯度会以当前的 θ 为起点,在很小的一段欧氏距离内找到最「陡峭」的方向,同时我们会对参数空间施加一些距离的限制。换而言之,我们在 θ 的绝对值发生微小变化的情况下计算出朴素梯度。优化步骤如下:
不同的是,自然梯度用到了参数为 θ, pθ(x)(在 NES 的原始论文中被称为「搜索分布」,论文链接:https://arxiv.org/abs/1106.4487)的概率分布空间。它在分布空间中的一小步内寻找最「陡峭」(变化最快)的方向,其中距离由 KL 散度来度量。在这种限制条件下,我们保证了每一步更新都是沿着分布的流形以恒定的速率移动,不会因为其曲率而减速。
但是,如何精确地计算出 KL[pθ‖pθ+Δθ] 呢?通过推导 logpθ+d 在 θ 处的泰勒展式,我们可以得到:
请注意,pθ(x) 是概率分布。最终,我们得到了:
其中,Fθ 被称为 Fisher 信息矩阵。由于E[∇θlogpθ]=0,所以 Fθ 也是 ∇θlogpθ 的协方差矩阵:
![]() 其中 dN∗仅仅提取了忽略标量 β−1 的情况下,在 θ 上最优移动步长的方向。
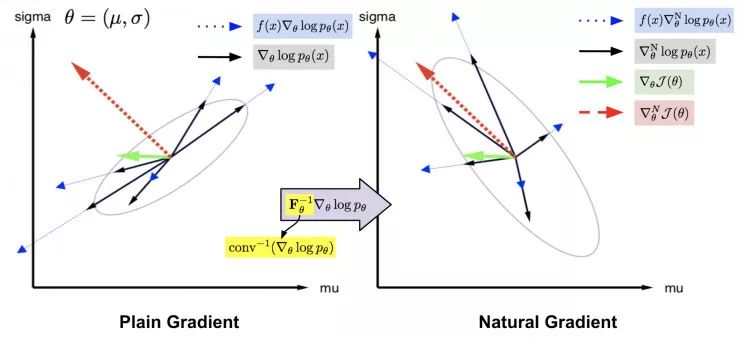
图 4:右侧的自然梯度样本(黑色实箭头)是左侧的朴素梯度样本(黑色实箭头)乘以其协方差的逆的结果。这样一来,可以用较小的权重惩罚具有高不确定性的梯度方向(由与其它样本的高协方差表示)。因此,合成的自然梯度(红色虚箭头)比原始的自然梯度(绿色虚箭头)更加可信(图片来源:NES 原始论文中图 2 的附加说明,https://arxiv.org/abs/1106.4487)
我们将与一个样本相关联的适应度标记为 f(x),关于 x 的搜索分布的参数为 θ。我们希望 NES 能够优化参数 θ,从而得到最大的期望适应度:
在这里,我们使用与蒙特卡洛策略梯度强化中相同的似然计算技巧:
除了自然梯度,NES 还采用了一些重要的启发式方法让算法的性能更加鲁棒。
其中 dN∗仅仅提取了忽略标量 β−1 的情况下,在 θ 上最优移动步长的方向。
图 4:右侧的自然梯度样本(黑色实箭头)是左侧的朴素梯度样本(黑色实箭头)乘以其协方差的逆的结果。这样一来,可以用较小的权重惩罚具有高不确定性的梯度方向(由与其它样本的高协方差表示)。因此,合成的自然梯度(红色虚箭头)比原始的自然梯度(绿色虚箭头)更加可信(图片来源:NES 原始论文中图 2 的附加说明,https://arxiv.org/abs/1106.4487)
我们将与一个样本相关联的适应度标记为 f(x),关于 x 的搜索分布的参数为 θ。我们希望 NES 能够优化参数 θ,从而得到最大的期望适应度:
在这里,我们使用与蒙特卡洛策略梯度强化中相同的似然计算技巧:
除了自然梯度,NES 还采用了一些重要的启发式方法让算法的性能更加鲁棒。
-
NES 应用了基于排序的适应度塑造(Rank-Based Fitness Shaping)算法,即使用适应度值单调递增的排序结果,而不是直接使用 f(x)。它也可以是对「效用函数」进行排序的函数,我们将其视为 NES 的一个自由参数。
-
NES 采用了适应性采样(Adaptation Sampling)在运行时调整超参数。当进行 θ→θ′ 的变换时,我们使用曼-惠特尼 U 检验( [Mann-Whitney U-test)对比从分布 pθ 上采样得到的样本以及从分布 pθ′ 上采样得到的样本。如果出现正或负符号,则目标超参数将减少或增加一个乘法常数。请注意,样本 xi′∼pθ′(x) 的得分使用了重要性采样权重 wi′=pθ(x)/pθ′(x)。
五、应用:深度强化学习中的演化策略
将演化算法应用于强化学习的想法可以追溯到很久以前的论文「Evolutionary Algorithms for Reinforcement Learning」(论文地址:https://arxiv.org/abs/1106.0221),但是由于计算上的限制,这种尝试仅仅止步于「表格式」强化学习(例如,Q-learning)。
受到 NES 的启发,OpenAI 的研究人员(详见 Salimans 等人于 2017 年发表的论文「Evolution Strategies as a Scalable Alternative to Reinforcement Learning」,论文链接:https://arxiv.org/abs/1703.03864)提出使用 NES 作为一种非梯度黑盒优化器,从而寻找能够最大化返回函数 F(θ) 的最优策略参数 θ。
这里的关键是,为模型参数 θ 加入高斯噪声 ε,并使用似然技巧将其写作高斯概率密度函数的梯度。最终,只剩下噪声项作为衡量性能的加权标量。
假设当前的参数值为 θ^(区别于随机变量 θ)。我们将 θ 的搜索分布设计为一个各向同性的多元高斯分布,其均值为 θ^,协方差矩阵为 σ2I
其中,高斯分布为
![]() 。
。
![]() 是我们用到的似然计算技巧。
在每一代中,我们可以采样得到许多 εi,i=1,…,n,然后并行地估计其适应度。一种优雅的设计方式是,无需共享大型模型参数。只需要在各个工作线程之间传递随机种子,就足以事主线程节点进行参数更新。随后,这种方法又被拓展成了以自适应的方试学习损失函数。详情请查阅博文「Evolved Policy Gradient」:
是我们用到的似然计算技巧。
在每一代中,我们可以采样得到许多 εi,i=1,…,n,然后并行地估计其适应度。一种优雅的设计方式是,无需共享大型模型参数。只需要在各个工作线程之间传递随机种子,就足以事主线程节点进行参数更新。随后,这种方法又被拓展成了以自适应的方试学习损失函数。详情请查阅博文「Evolved Policy Gradient」:
-
https://lilianweng.github.io/lil-log/2019/06/23/meta-reinforcement-learning.html#meta-learning-the-loss-function
图 5:使用演化策略训练一个强化策略的算法(图片来源:论文「ES-for-RL」,https://arxiv.org/abs/1703.03864)
为了使算法的性能更加鲁棒,OpenAI ES 采用了虚拟批量归一化(Virtual BN,用于计算固定统计量的 mini-batch 上的批量归一化方法),镜面采样(Mirror Sampling,采样一对 (−ϵ,ϵ) 用于估计),以及适应度塑造(Fitness Shaping)技巧。
在强化学习领域,「探索与利用」是一个很重要的课题。上述演化策略中的优化方向仅仅是从累积返回函数 F(θ) 中提取到的。在不进行显式探索的情况下,智能体可能会陷入局部最优点。
新颖性搜索(Novelty-Search)演化策略(NS-ES,详见 Conti 等人于 2018 年发表的论文「Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents」,论文地址:https://arxiv.org/abs/1712.06560)通过朝着最大化「新颖性得分」的方向更新参数来促进探索。
「新颖性得分」取决于一个针对于特定领域的行为特征函数 b(πθ)。对 b(πθ) 的选择取决于特定的任务,并且似乎具有一定的随机性。例如,在论文里提到的人形机器人移动任务中,b(πθ) 是智能体最终的位置 (x,y)。
1. 将每个策略的 b(πθ) 加入一个存档集合 A。
2. 通过 b(πθ) 和 A 中所有其它实体之间的 K 最近邻得分衡量策略 πθ 的新颖性。(文档集合的用例与「情节记忆」很相似)
在这里,演化策略优化步骤依赖于新颖性得分而不是适应度:
NS-ES 维护了一个由 M 个独立训练的智能体组成的集合(「元-种群」),M={θ1,…,θM}。然后选择其中的一个智能体,将其按照与新颖性得分成正比的程度演化。最终,我们选择出最佳策略。这个过程相当于集成,在 SVPG 中也可以看到相同的思想。
其中,N 是高斯扰动噪声向量的数量,α 是学习率。
NS-ES 完全舍弃了奖励函数,仅仅针对新颖性进行优化,从而避免陷入极具迷惑性的局部最优点。为了将适应度重新考虑到公式中,研究人员又提出了两种变体。
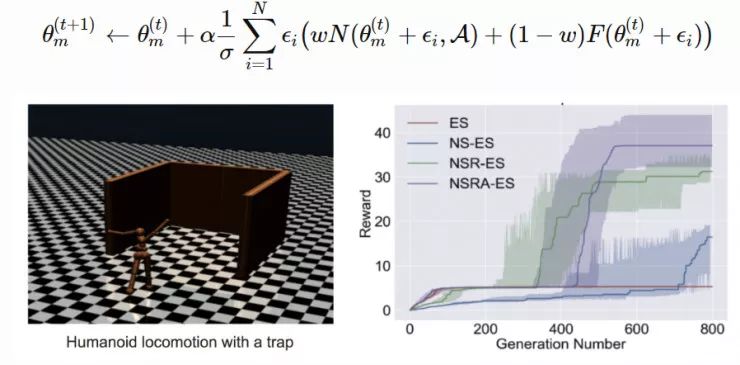
NSRAdapt-ES (NSRA-ES):
自适应的权重参数初始值为 w=1.0。如果算法的性能经过了很多代之后没有变化,我们就开始降低 w。然后,当性能开始提升时,我们停止降低 w,反而增大 w。这样一来,当性能停止提升时,模型更偏向于提升适应度,而不是新颖性。
图 6:(左图)环境为人形机器人移动问题,该机器人被困在一个三面环绕的强中,这是一个具有迷惑性的陷阱,创造了一个局部最优点。(右图)实验对比了 ES 基线和另一种促进探索的变体。(图片来源,论文「NS-ES」,https://arxiv.org/abs/1712.06560)
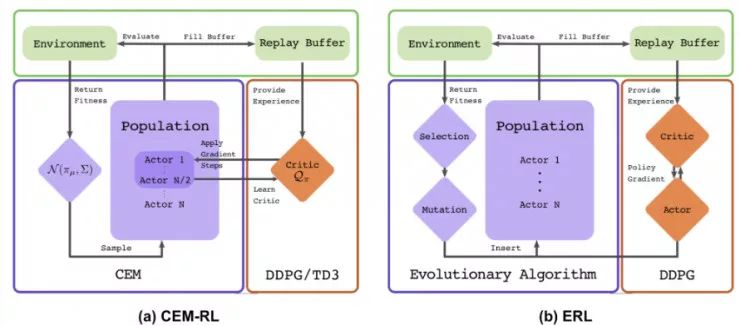
图 7:CEM-RL 和 ERL 算法(https://papers.nips.cc/paper/7395-evolution-guided-policy-gradient-in-reinforcement-learning.pdf)的架构示意图(图片来源:论文「CEM-RL」,https://arxiv.org/abs/1810.01222)
CEM-RL 方法(详见 Pourchot 和 Sigaud 等人于 2019 年发表的论文「CEM-RL: Combining evolutionary and gradient-based methods for policy search」,论文地址:https://arxiv.org/abs/1810.01222)结合了交叉熵方法(CEM)和 DDPG 或 TD3。
在这里,CEM 的工作原理与上面介绍的简单高斯演化策略基本相同,因此可以使用 CMA-ES 替换相同的函数。CEM-RL 是基于演化强化学习(ERL,详见 Khadka 和 Tumer 等人于 2018 年发表的论文「Evolution-Guided Policy Gradient in Reinforcement Learning」,论文地址:https://papers.nips.cc/paper/7395-evolution-guided-policy-gradient-in-reinforcement-learning.pdf)的框架构建的,它使用标准的演化算法选择并演化「Actor」的种群。随后,在这个过程中生成的首次展示经验也会被加入到经验回放池中,用于训练强化学习的「Actor」网络和「Critic」网络。
1. πμ 为 CEM 种群的「Actor」平均值,使用随机的「Actor」网络对其进行初始化。
2. 「Critic」网络 Q 也将被初始化,通过 DDPG/TD3 算法对其进行更新。
-
在分布 N(πμ,Σ) 上采样得到一个「Actor」的种群。
-
评估一半「Actor」的种群。将适应度得分用作累积奖励 R,并将其加入到经验回放池中。
-
将另一半「Actor」种群与「Critic」一同更新。
-
使用性能最佳的优秀样本计算出新的 πmu 和 Σ。也可以使用 CMA-ES 进行参数更新。
六、拓展:深度学习中的演化算法
(本章并没有直接讨论演化策略,但仍然是非常有趣的相关阅读材料。)
演化算法已经被应用于各种各样的深度学习问题中。「POET」(详见 Wang 等人于 2019 年发表的论文「Paired Open-Ended Trailblazer (POET): Endlessly Generating Increasingly Complex and Diverse Learning Environments and Their Solutions」,论文地址:https://arxiv.org/abs/1901.01753)就是一种基于演化算法的框架,它试图在解决问题的同时生成各种各样不同的任务。关于 POET 的详细介绍请参阅下面这篇关于元强化学习的博文:https://lilianweng.github.io/lil-log/2019/06/23/meta-reinforcement-learning.html#task-generation-by-domain-randomization。
另一个例子则是演化强化学习(ERL),详见图 7(b)。
下面,我将更详细地介绍两个应用实例:基于种群的训练(PBT),以及权重未知的神经网络(WANN)
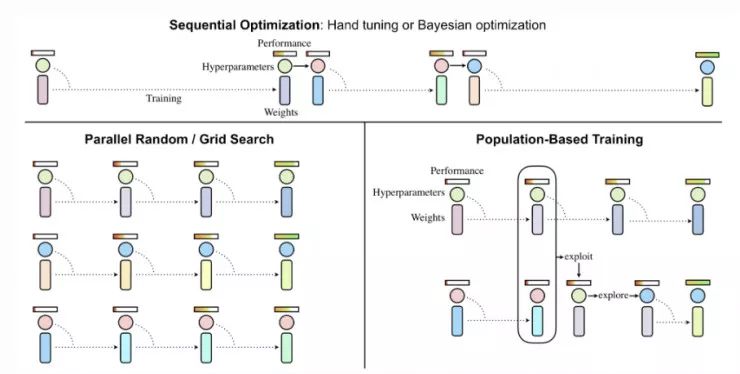
图 8:对比不同的超参数调优方式的范例(图片来源:论文「Population Based Training of Neural Networks」,https://arxiv.org/abs/1711.09846)
基于种群的训练(PBT,详见 Jaderberg 等人于 2017 年发表的论文「Population Based Training of Neural Networks」,论文地址:https://arxiv.org/abs/1711.09846)将演化算法应用到了超参数调优问题中。它同时训练了一个模型的种群以及相应的超参数,从而得到最优的性能。
PBT 过程起初拥有一组随机的候选解,它们包含一对模型权重的初始值和超参数 {(θi,hi)∣i=1,…,N}。我们会并行训练每个样本,然后周期性地异步评估其自身的性能。当一个成员准备好后(即该成员进行了足够的梯度更新步骤,或当性能已经足够好),就有机会通过与整个种群进行对比进行更新:
-
「exploit()」:当模型性能欠佳时,可以用性能更好的模型的权重来替代当前模型的权重。
-
「explore()」:如果模型权重被重写,「explore」步骤会使用随机噪声扰动超参数。
在这个过程中,只有性能良好的模型和超参数对会存活下来,并继续演化,从而更好地利用计算资源。
图 9:基于种群的训练算法示意图。(图片来源,论文「Population Based Training of Neural Networks」,https://arxiv.org/abs/1711.09846)
权重未知的神经网络(WANN,详见 Gaier 和 Ha 等人于 2019 年发表的论文「Weight Agnostic Neural Networks」,论文地址:https://arxiv.org/abs/1906.04358)在不训练网络权重的情况下,通过搜索最小的网络拓扑来获得最优性能。
由于不需要考虑网络权值的最佳配置,WANN 更加强调网络架构本身,这使得它的重点与神经网络架构搜索(NAS)不同。WANN 在演化网络拓扑的时候深深地受到了一种经典的遗传算法「NEAT」(增广拓扑的神经演化,详见 Stanley 和 Miikkulainen 等人于 2002 年发表的论文「Efficient Reinforcement Learning through Evolving Neural Network Topologies」,论文地址:http://nn.cs.utexas.edu/downloads/papers/stanley.gecco02_1.pdf)的启发。
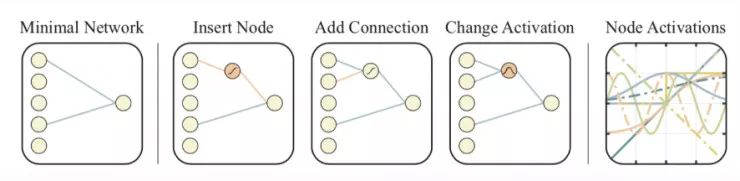
WANN 的工作流程看上去与标准的遗传算法基本一致:
图 10: WANN 中用于搜索新网络拓扑的变异操作。(从左到右分别为)最小网络,嵌入节点,增加连接,改变激活值,节点的激活。
在「评估」阶段,我们将所有网络权重设置成相同的值。这样一来,WANN 实际上是在寻找可以用最小描述长度来描述的网络。在「选择」阶段,我们同时考虑网络连接和模型性能。
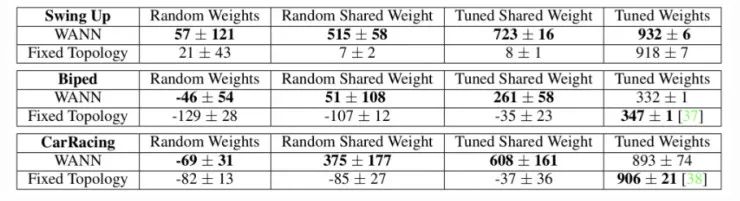
图 11:将 WANN 发现的网络拓扑在不同强化学习任务上的性能与常用的基线 FF 网络进行了比较。「对共享权重调优」只需要调整一个权重值。
如图 11 所示,WANN 的结果是同时使用随机权重和共享权重(单一权重)评估得到的。有趣的是,即使在对所有权重执行权重共享并对于这单个参数进行调优的时候,WANN 也可以发现实现非常出色的性能的拓扑。
参考文献
[1] Nikolaus Hansen. “The CMA Evolution Strategy: A Tutorial” arXiv preprint arXiv:1604.00772 (2016).
[2] Marc Toussaint. Slides: “Introduction to Optimization”
[3] David Ha. “A Visual Guide to Evolution Strategies” blog.otoro.net. Oct 2017.
[4] Daan Wierstra, et al. “Natural evolution strategies.” IEEE World Congress on Computational Intelligence, 2008.
[5] Agustinus Kristiadi. “Natural Gradient Descent” Mar 2018.
[6] Razvan Pascanu & Yoshua Bengio. “Revisiting Natural Gradient for Deep Networks.” arXiv preprint arXiv:1301.3584 (2013).
[7] Tim Salimans, et al. “Evolution strategies as a scalable alternative to reinforcement learning.” arXiv preprint arXiv:1703.03864 (2017).
[8] Edoardo Conti, et al. “Improving exploration in evolution strategies for deep reinforcement learning via a population of novelty-seeking agents.” NIPS. 2018.
[9] Aloïs Pourchot & Olivier Sigaud. “CEM-RL: Combining evolutionary and gradient-based methods for policy search.” ICLR 2019.
[10] Shauharda Khadka & Kagan Tumer. “Evolution-guided policy gradient in reinforcement learning.” NIPS 2018.
[11] Max Jaderberg, et al. “Population based training of neural networks.” arXiv preprint arXiv:1711.09846 (2017).
[12] Adam Gaier & David Ha. “Weight Agnostic Neural Networks.” arXiv preprint arXiv:1906.04358 (2019).
via https://lilianweng.github.io/lil-log/2019/09/05/evolution-strategies.html
![]() 点击“
阅读
原文
”查看
深度学习的图像修复
点击“
阅读
原文
”查看
深度学习的图像修复

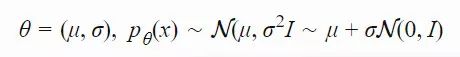
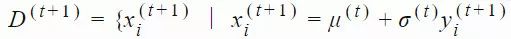
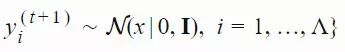
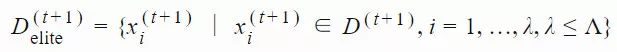
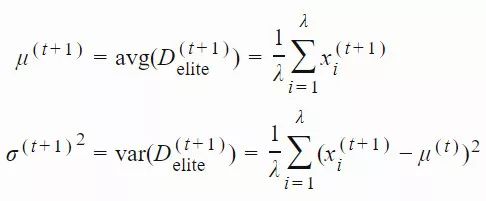
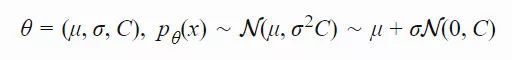
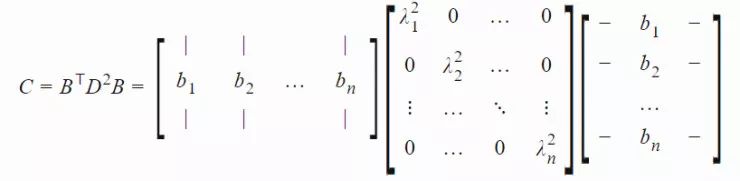
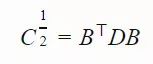
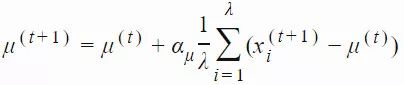
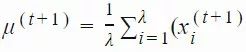
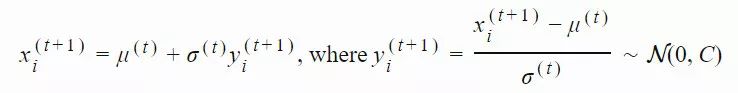
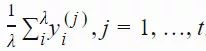 ,构建了一个演化路径(evolution path)pσ。通过比较该路径与随机选择(意味着每一步之间是不相关的)状态下期望会生成的路径长度,我们可以相应地调整 σ(详见图 2)。
,构建了一个演化路径(evolution path)pσ。通过比较该路径与随机选择(意味着每一步之间是不相关的)状态下期望会生成的路径长度,我们可以相应地调整 σ(详见图 2)。
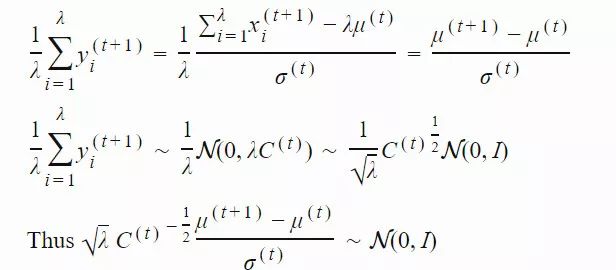


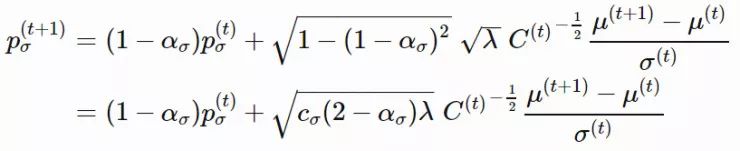
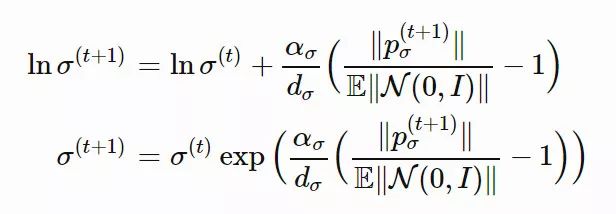
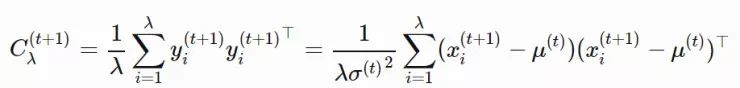
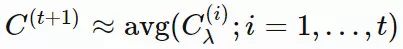
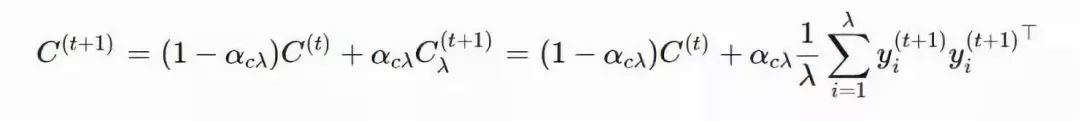
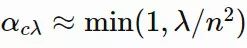
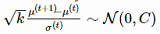 ,pc的计算方法如下:
,pc的计算方法如下:
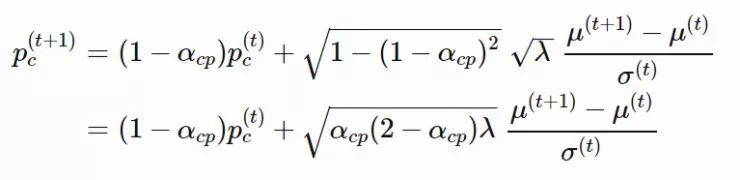
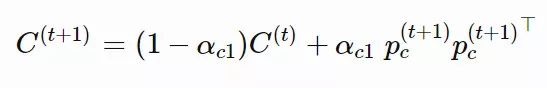
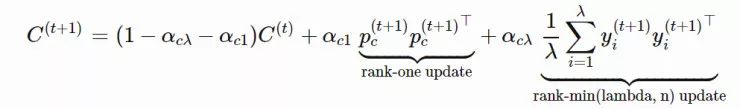

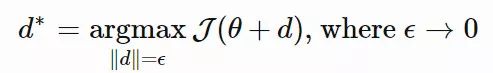
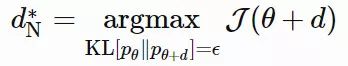
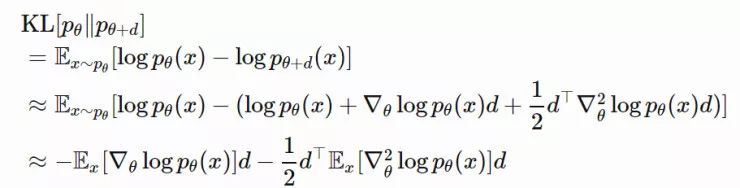
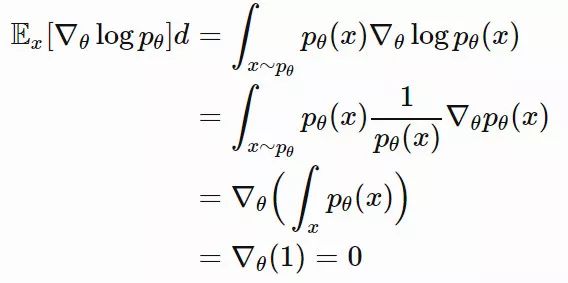
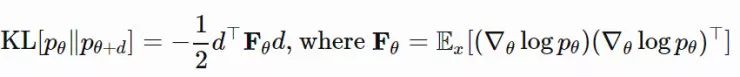
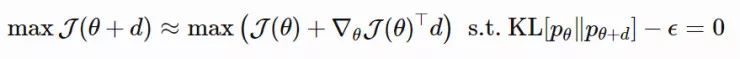
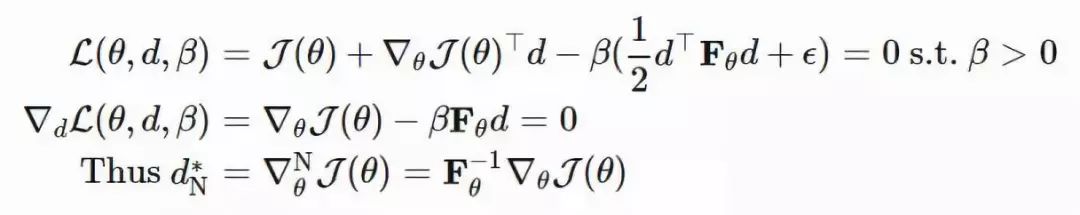 其中 dN∗仅仅提取了忽略标量 β−1 的情况下,在 θ 上最优移动步长的方向。
其中 dN∗仅仅提取了忽略标量 β−1 的情况下,在 θ 上最优移动步长的方向。
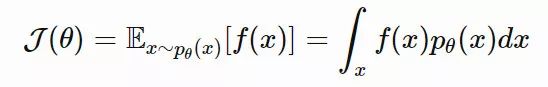

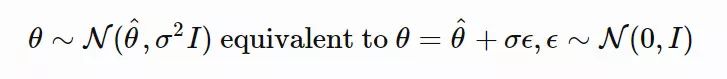
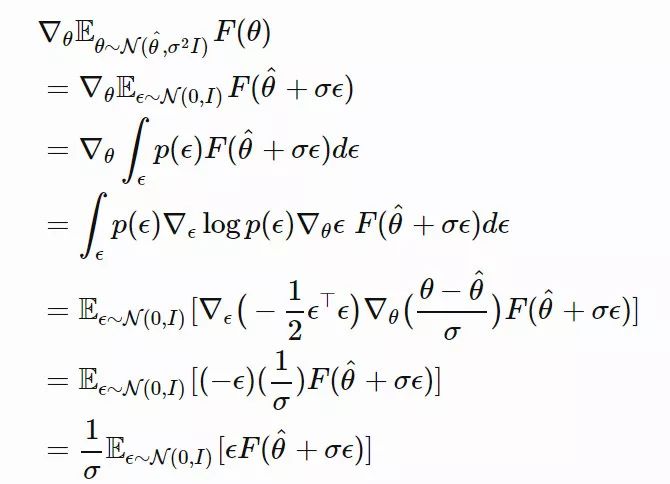
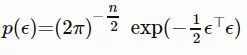 。
。
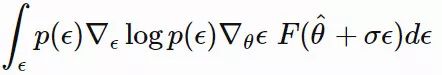 是我们用到的似然计算技巧。
是我们用到的似然计算技巧。

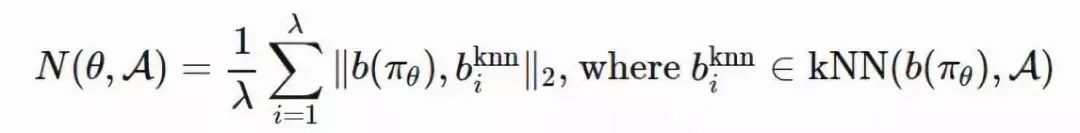
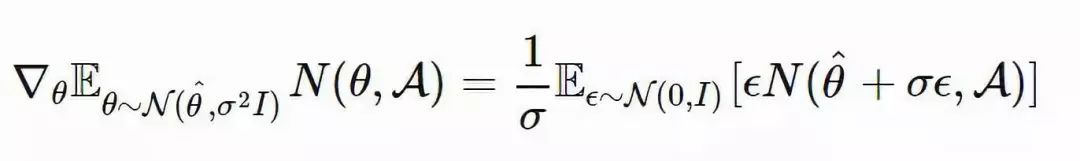
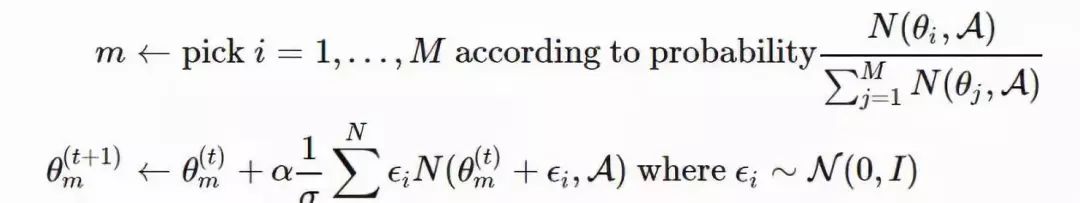
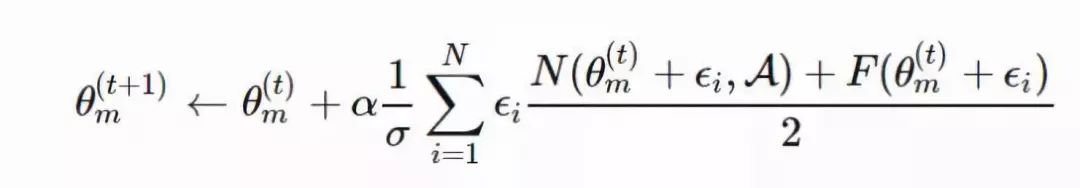



 点击“
阅读
原文
”查看
深度学习的图像修复
点击“
阅读
原文
”查看
深度学习的图像修复




