专栏 | 数据 + 进化算法 = 数据驱动的进化优化?进化算法 PK 数学优化(附网盘文献)
机器之心专栏
来源公众号:运筹 OR 帷幄
作者:杨翠娥 & 王源
数据驱动的进化优化是什么,仅仅就是数据 + 优化算法吗?数据驱动的进化优化适用于哪些应用场景?传统的数学优化方法是否迎来了新一轮的挑战。本文将为您深入浅出的解答以上问题。文末我们还附上了相关资料与参考文献的大礼包,这些资料并非一个简单的书单,是经过本文两位作者多年的研究经验和学习历程精心挑选整理的,有顶级期刊的优质论文,也有科普大众的通俗讲义。
我们会收集相关的数据驱动优化经典文献和进化计算相关的课程 PPT 等资料做成网盘链接放到后边。
Ⅰ
先说一说 数据驱动进化优化的 Motivation

简单来说,数据驱动的进化优化(Data-driven evolutionary computation)就是借助数据和进化算法求解优化问题。首先为什么用进化算法呢?举几个例子,一些优化问题很难获取其数学优化模型的,如仿真实验软件,可以看成是黑箱的优化问题。另有一些问题,虽然知道数学表达式,但是表达式存在非凸,不可导,不可微等性质。这些问题很难用基于梯度的传统数学优化方法求解的,这时,智能优化算法就隆重上场了,如遗传算法,粒子群算法,差分算法等。那为什么还要借助数据呢?我们知道,智能优化算法都是基于种群迭代的优化算法的,种群包含几十个甚至几百个的个体(每个个体就是一个解),并且需要迭代几百代才能找出比较好的解,这种情况下优化问题就需要进行很多次评估(计算解的函数值)。比如说对于种群是 100,迭代次数 100 代的智能优化算法,优化问题就需要评估 10000 次!然而,有些优化问题评估代价是很高的,比如风洞实验评估一次就需要好几个小时;又比如制药工程,一次试药过程需要话费昂贵的代价(一次试药就关系到小白鼠的生命)。对于智能优化算需要上千次及上万次的评估,优化问题是无法承受的,这种情况下,学者们就想出了利用优化问题的历史数据来辅助优化过程,以减少优化问题的评估次数,从而降低优化问题评估的代价。
Ⅱ
数据驱动进化优化算法
那么,数据驱动的进化优化是怎样进行的呢?过程如图 1 所示(来自文献 [1])。先用优化过程优化问题(图中的 Exact function evaluation,以下称为真实优化问题)产生的数据建立个模型,这个模型称为代理模型(Surrogate),所以以前数据驱动的进化优化算法也叫代理模型辅助的进化优化算法(Surrogate-Assisted Evolutionary Algorithm,SAEA)。代理模型的目的就是逼近真实问题。在优化过程中,这个代理模型和真实问题相互合作评估个体,这个相互合作就是所谓的模型管理(Surrogate Management)。代理模型和真实优化问题相互合作有两个方面的原因,一方面是代理模型由真实问题的数据训练得到,和真实问题有着相似性,用代理模型代替优化问题对解进行评估,预选出真实问题的比较好的解,以减少真实问题的评估次数。另一方面是代理模型和真实问题存在偏差,用真实问题对解进行评估以防止代理模型误导解偏离真实问题,将真实问题评估的解加入训练数据集(就是图中的虚线那块)修正代理模型。那么代理模型是怎么建立的?模型管理是什么呢?
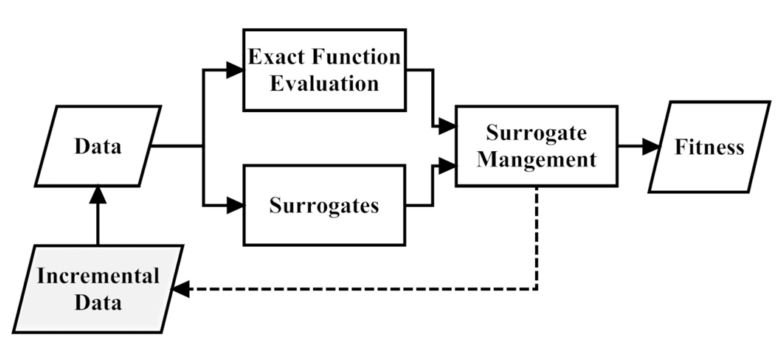
图 1. 数据驱动的进化优化算法流程(来自文献 1)
一般来说,机器学习的那些建模方法都可以拿来训练代理模型,如高斯过程,神经网络,SVM,RBF 还有各种集成模型。不过用的比较多的是高斯过程(讲到后面模型管理就知道了)。
模型管理常用的方法在学术上称为基于代和个体的混合方法。意思就是算法先以代理模型为优化问题进行优化若干代,然后从最后一代中选取一部分个体重新送给真实问题重新评估。 这里的重点和难点(也是 SAEA 问题)是从代理模型中选择出哪些解能够快速辅助真实问题的收敛,也就是前面提到的怎样预选出好的解。如何从代理模型中选择真实问题评估解的策略在 SAEA 中有个专业名词叫 Infill Sampling Criteria.
一个想法是选择代理模型最好的一部分解给真实问题重新评估,在这种情况下,如果代理模型足够准确,也是就代理模型和真实优化问题很近似,那么选择出的这些解更有助于真实问题的收敛。如图 2 所示。
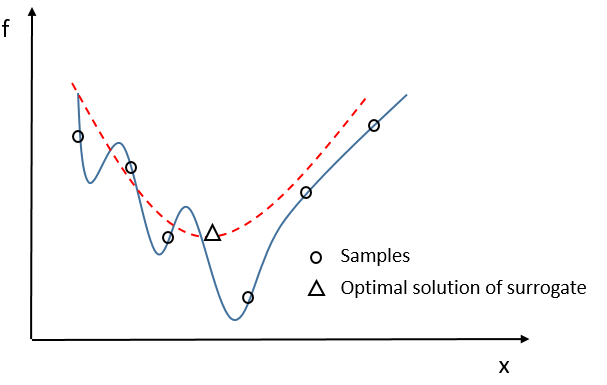
但是训练足够准确的代理模型是不太现实的,特别是在 SAEA 中收集到的小数据。因此,另一种选择重新评估解的方法就是选择代理模型认为不确定的解(简单的理解是离其它个体比较远的那些个体),如图 3 所示(来自文献 2)。这时就能体现出高斯过程的优势了,既能直接给出解的评估值还能给出评估值的确定性(一个讲解高斯过程的网址http://www.ppvke.com/Blog/archives/24049)。选择这些不确定的解有两方面好处:这些个体所在的区域还很少被搜索(图 3a),传递给真实问题能够提高真实问题的探索能力。另一个好处是由于这些个体分布在稀疏的区域,用真实问题评估过后加入训练集提高了训练集的多样性,从而在在代理模型修正过程能很大程度提高代理模型的准确度(图 3b)。
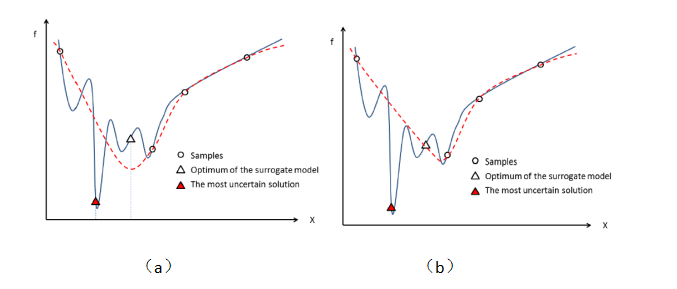
图 3. 选择代理模型最不确定的解(来自文献 2)
最后一种方法,也是最常用的方法是选择那些兼顾上述两种情况的个体。如高斯过程模型常用的 LCB 指标,ExI 指标如公式(1)和(2)。
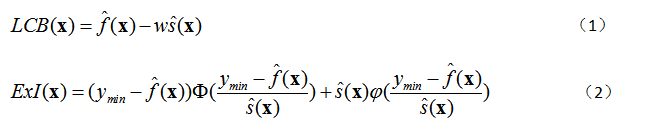
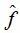
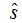
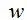
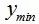
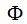
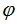
对于其它不能给出解不准确度的模型,SAEA 研究领域提出了各种各样的策略。比如说建立局部代理模型,选择局部代理模型的最优解;对于集成模型,用各个子模型评估的差异性代表个体评估的准确性等。
最后真实问题的最优解(集)就从训练集里面选出(真实问题评估过的解)。以上所述就是数据驱动进化优化算法的简单过程。详细的介绍推荐综述 [3] 和挑战[4]。
Ⅲ
进化算法 VS 数学优化(以下的讨论均基于单目标优化问题)
上面的章节对数据驱动的进化优化给出了一个简单介绍,看到这里大家可能想问一下进化算法和数学优化(如果不熟悉数学优化是什么可以参考这篇文章https://zhuanlan.zhihu.com/p/25579864)各自的优势和不足是什么。实际上做进化算法和数学优化都是为了解决优化问题,但是出发的角度是有很大不同的,我们经常会见到以下情景。


进化算法只需计算目标函数的值即可,对优化问题本身的性质要求是非常低的,不会像数学优化算法往往依赖于一大堆的条件,例如是否为凸优化,目标函数是否可微,目标函数导数是否 Lipschitz continuity 等等。本人还曾经研究过带有偏微分方程约束的优化问题,很多时候你根本就不知道那个目标函数凸不凸,可导不可导。这一点是进化算法相对数学优化算法来说最大的一个优势,实际上同时也是进化算法一个劣势,因为不依赖问题的性质(problem-independent)对所有问题都好使往往意味着没有充分的利用不同问题的特性去进一步加速和优化算法(这里很具有哲学辩证思想的是有优点往往就会派生出缺点)。这样看来数学优化算法的条条框框实际上是划定了,数学优化算法的适用范围,出了这个范围好使不好使不知道,但是在这个范围内数学优化就能给出一个基本的理论保证。
结论:对问题结构确定的优化问题,有充分的关于优化问题的信息来利用的时候数学优化一般来说有优势,例如线性规划,二次规划,凸优化等等。反之,可能使用进化算法就会有优势。对于一些数学优化目前不能彻底解决的问题例如 NP hard 问题,进化算法也有很大的应用前景。
进化算法的计算速度比较慢一直是大家的共识,这一点也很好理解,每迭代一次都需要计算 M 次目标函数,M 是种群规模一般是 30-50 左右。进化算法的前沿的研究方向其中一个就是针对大规模优化问题的(large-scale), 我也曾查阅过相关顶级期刊的论文发现进化算法里的 large-scale 的规模对数学优化算法来讲可能根本构不成 large-scale。所以侧面反应出了进化算法在计算速度的瓶颈限制了其在大规模优化问题上的应用。值得一提的是近几年来随着深度学习的崛起,人们对计算力的要求越来越高,基于 GPU 的并行计算和分布式计算的架构被广泛的应用到人工智能的各个领域。由于进化算法本身天生具有良好的并行特性,基于 GPU 并行计算的进化算法是否能够在一定程度上解决进化算法速度慢的问题绝对是一个值得研究的 topic。
综上所述:进化算法也好,数学优化也好都只是认识问题解决问题的工具之一,工具本身并不存在绝对的优劣之分,每种工具都有其适用的场景,辨别它们的长短,找到它们合适的应用场景是我们这些用工具的人应该做的。
Ⅳ
小结
数据驱动进化优化算法用来解决计算代价昂贵的问题,也有看到应用在其它优化领域,如鲁棒优化问题,大规模优化问题等,因为这些问题求解过程也耗费大量计算时间,其本质还是减少真实问题的评估次数。此外,离线的数据驱动优化也开始研究(也称为仿真优化)[1],也就是说优化过程中只能使用代理模型,无法用真实问题验证。
[1] Wang H, Jin Y, Jansen J O. Data-driven surrogate-assisted multiobjective evolutionary optimization of a trauma system[J]. IEEE Transactions on Evolutionary Computation, 2016, 20(6): 939-952.
[2] http://www.saeopt.ex.ac.uk/media/HandingWang:2016.pdf
[3] Jin Y. Surrogate-assisted evolutionary computation: Recent advances and future challenges[J]. Swarm and Evolutionary Computation, 2011, 1(2): 61-70.
[4] Jin Y. Data Driven Evolutionary Optimization of Complex Systems: Big Data Versus Small Data[C]//Proceedings of the 2016 on Genetic and Evolutionary Computation Conference Companion. ACM, 2016: 1281-1282.

资源截图图示
资源截图图示
作者:杨翠娥,东北大学流程工业综合自动化国家重点实验室与新加坡国立大学联合培养博士,研究方向—多目标优化,数据驱动的进化优化。
作者:王源,东北大学流程工业综合自动化国家重点实验室博士,研究方向 - 数学优化与机器学习交叉学科。
本文为机器之心经授权转载,转载请联系原作者获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



