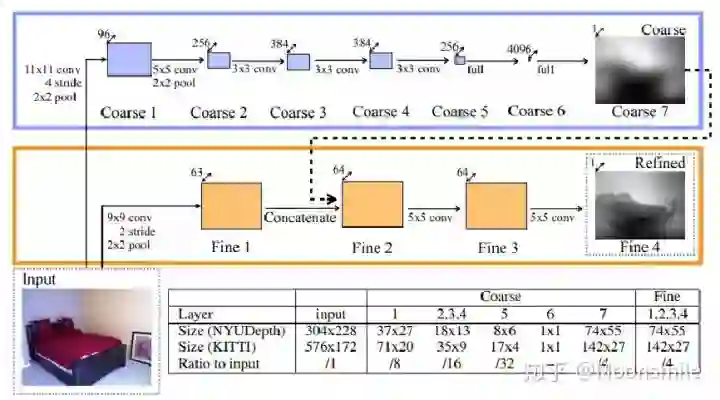
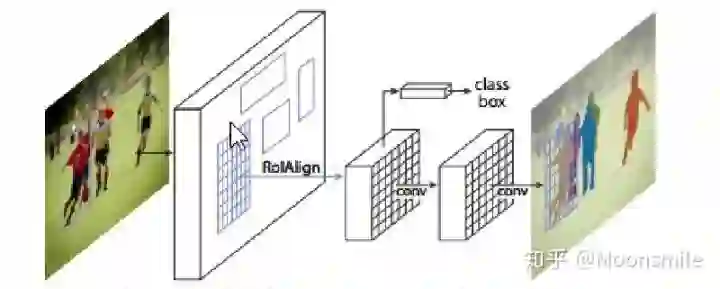
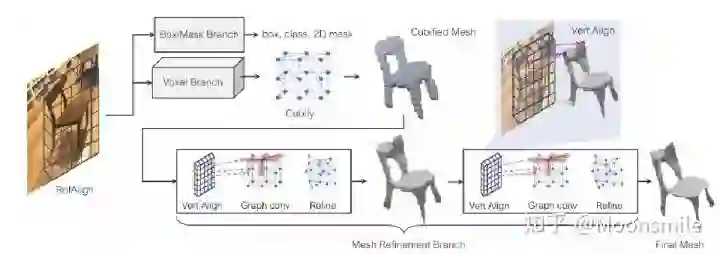
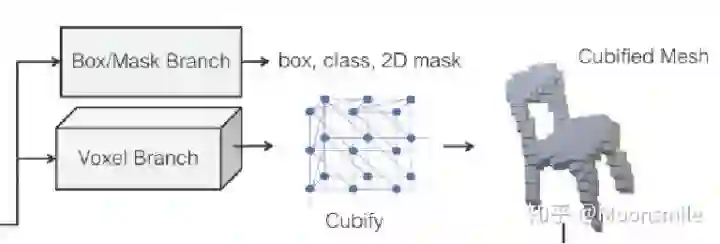
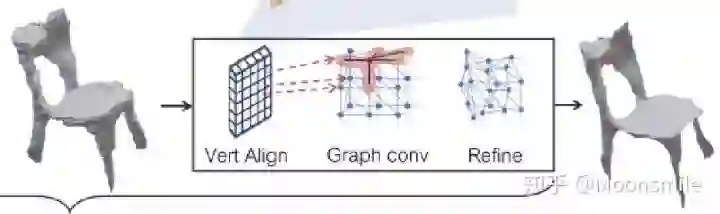
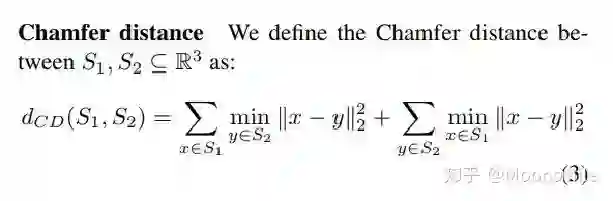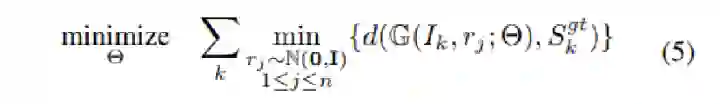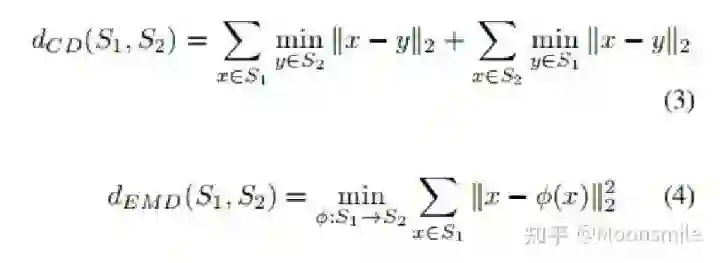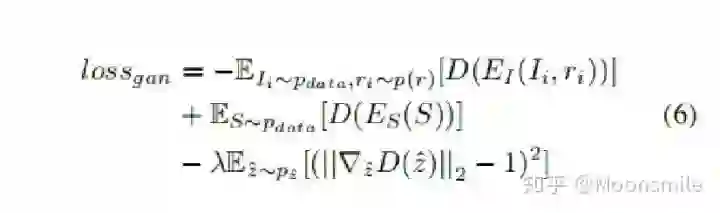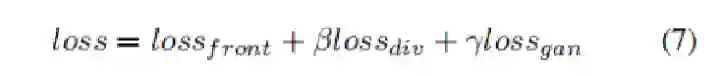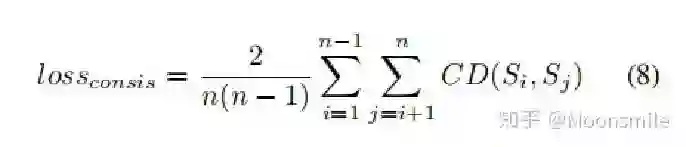Depth, NIPS 2014, Cited by 1011这篇论文思路很简单,算是用深度学习做深度图估计的开山之作,网络分为全局粗估计和局部精估计,对深度由粗到精的估计,并且提出了一个尺度不变的损失函数。主体网络Scale-invariant Mean Squared Error本文总结(1)提出了一个包含分为全局粗估计和局部精估计,可以由粗到精估计的网络。(2)提出了一个尺度不变的损失函数。
二、用体素来做单视图或多视图的三维重建
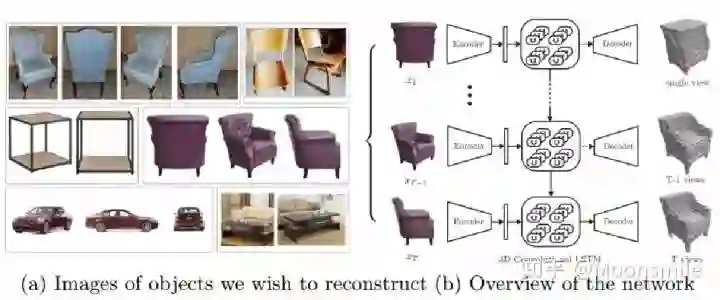
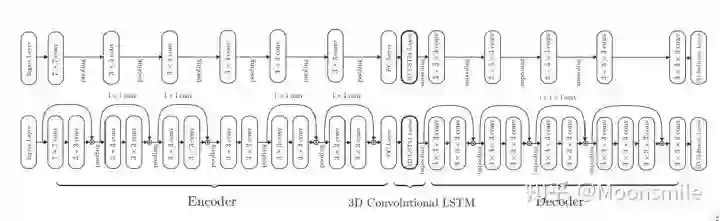
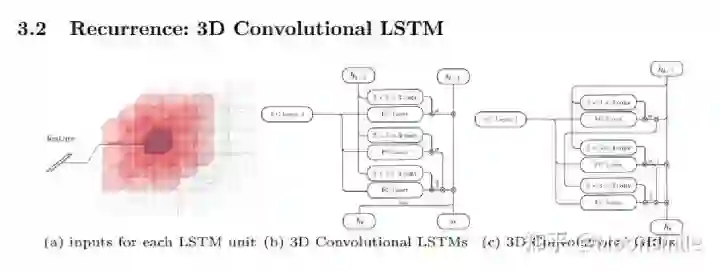
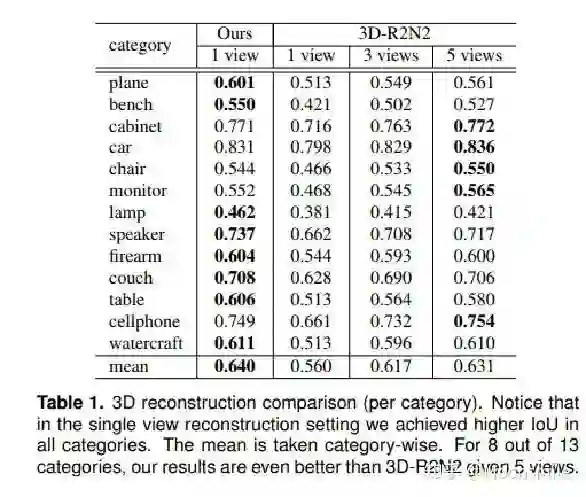
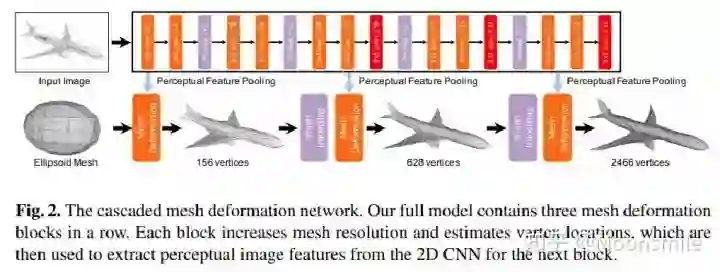
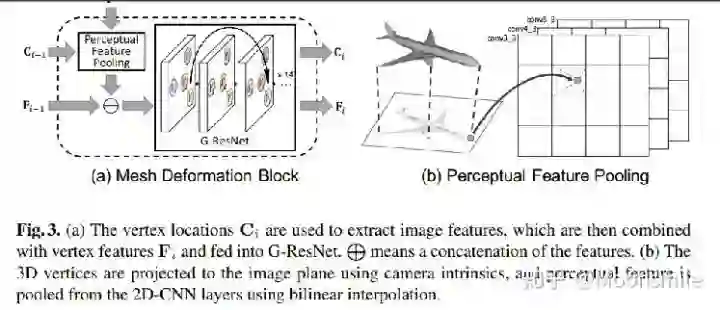
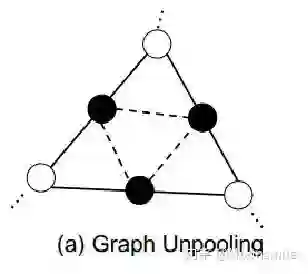
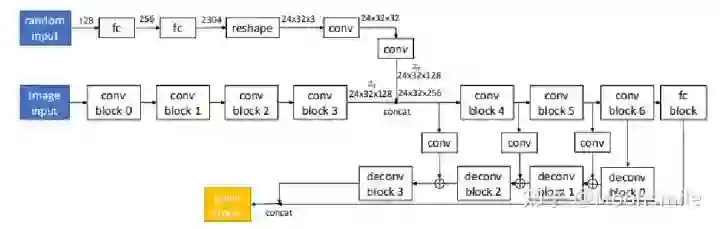
Voxel, ECCV 2016, Cited by 342这篇文章挺有意思,结合了LSTM来做,如果输入只有一张图像,则输入一张,输出也一个结果。如果是多视图的,则将多视图看作一个序列,输入到LSTM当中,输出多个结果。FrameworkFramework如主框架所示,这篇文章采用深度学习从2D图像到其对应的3D voxel模型的映射: 首先利用一个标准的CNN结构对原始input image 进行编码;再利用一个标准 Deconvolution network 对其解码。中间用LSTM进行过渡连接, LSTM 单元排列成3D网格结构, 每个单元接收一个feature vector from Encoder and Hidden states of neighbors by convolution,并将他们输送到Decoder中. 这样每个LSTM单元重构output voxel的一部分。总之,通过这样的Encoder-3DLSTM-Decoder的网络结构就建立了2D images -to -3D voxel model的映射。3D LSTM 和 3D GRU损失函数采用的是二分类的交叉熵损失,类似于在三维空间做分割,类别是两类,分别是占有或者不占有。损失函数除了交叉熵loss可以用作评价指标,还可以把预测结果跟标签的IoU作为评价指标,如下图所示:IoU可作为评价指标Single Real-World Image ReconstructionReconstructing From Different Views本文总结(1)采用深度学习从2D图像到其对应的3D voxel模型的映射,模型设计为Encoder+3D LSTM + Decoder。(2)既适用单视图,也适用多视图。(3)以体素的表现形式做的三维重建。(4)缺点是需要权衡体素分辨率大小(计算耗时)和精度大小。
三、用点云来做单张RGB图像的三维重建
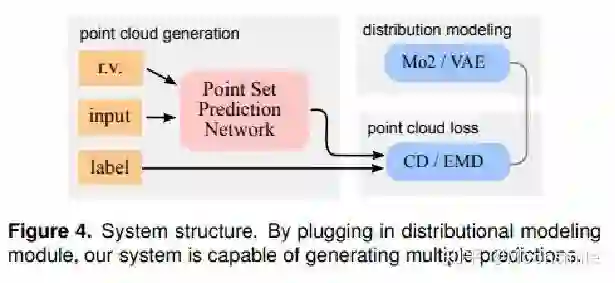
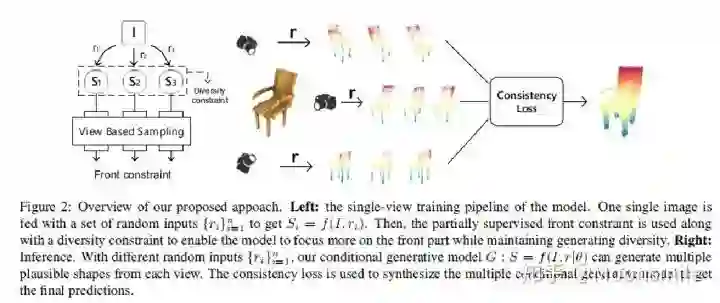
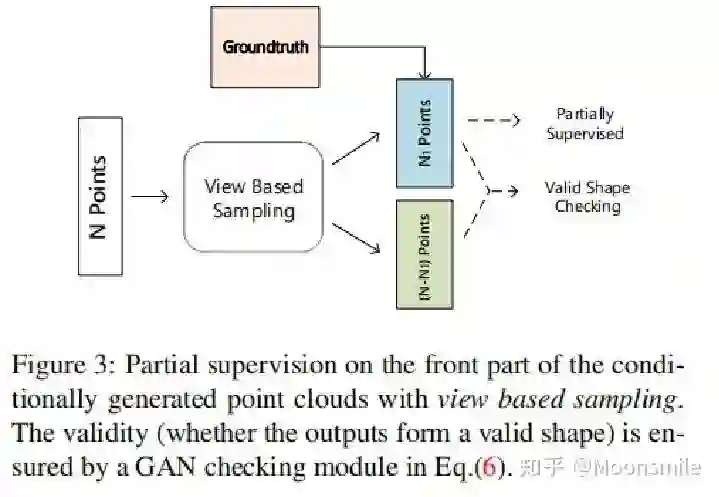
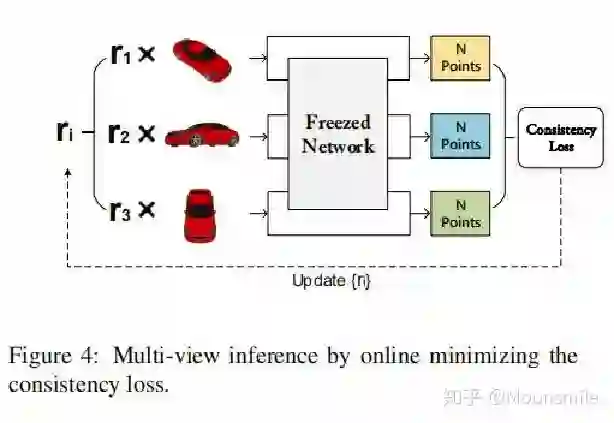
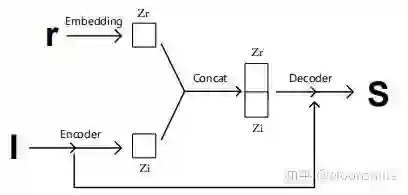
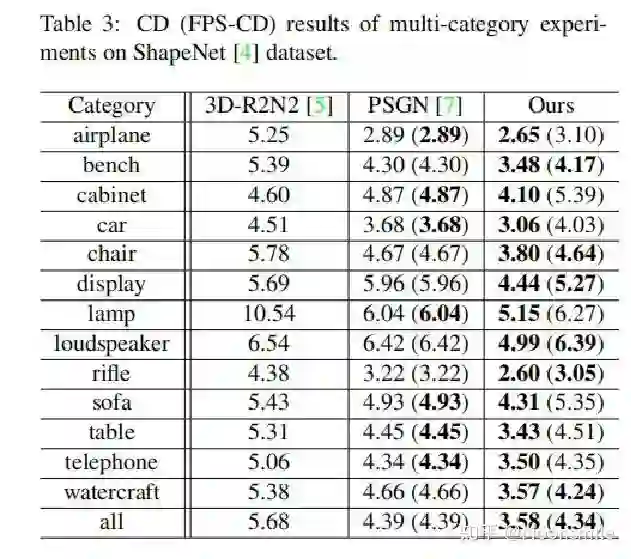
Point Cloud, CVPR 2017, Cited by 274大多数现存的工作都在使用深度网络进行3D 数据采用体积网格或图像集合(几何体的2D视图)。然而,这种表示导致采样分辨率和净效率之间的折衷。在这篇论文中,作者利用深度网络通过单张图像直接生成点云,解决了基于单个图片对象生成3D几何的问题。点云是一种简单,统一的结构,更容易学习,点云可以在几何变换和变形时更容易操作,因为连接性不需要更新。该网络可以由输入图像确定的视角推断的3D物体中实际包含点的位置。模型最终的目标是:给定一张单个的图片(RGB或RGB-D),重构出完整的3D形状,并将这个输出通过一种无序的表示——点云(Point cloud)来实现。点云中点的个数,文中设置为1024,作者认为这个个数已经足够表现大部分的几何形状。主框架鉴于这种非正统的网络输出,作者面临的挑战之一是如何在训练期间构造损失函数。因为相同的几何形状可能在相同的近似程度上可以用不同的点云来表示,因此与通常的L2型损失不同。本文使用的 loss倒角距离搬土距离对于解决2D图片重构后可能的形状有很多种这个问题,作者构造了一个 Min-of-N loss (MoN) 损失函数。Min-of-N loss 的意思是,网络G通过n个不同的r扰动项进行n次预测,作者认为从直觉上来看,我们会相信n次中会至少有一次预测会非常接近真正的答案,因此可以认为这n次预测与真正的答案的距离的最小值应该要最小。实验可视化结果实验可视化结果实验数值结果本文总结该文章的贡献可归纳如下:(1)开创了点云生成的先例(单图像3D重建)。(2)系统地探讨了体系结构中的问题点生成网络的损失函数设计。(3)提出了一种基于单图像任务的三维重建的原理及公式和解决方案。总体来说,该篇文章开创了单个2D视角用点云重构3D物体的先河,是一篇值得一看的文章。