3D重建:硬派几何求解vs深度学习打天下?
机器之心原创
作者:Yuanyuan Li
编辑:Hao Wang
一直以来,研究人员都希望能够赋予机器和人类感官一样的感知,其中就包含视觉。作为人类最重要的感官之一,人类接受到的信息中超过 70% 来源于双眼。人的眼睛可以感知到 3D 信息,由于双目视觉的存在,即使面对一张照片也可以比较轻易的从中获取深度信息。然而,这对计算机来说却是一个难点——3D 世界中形状不同的物体可以在 2 维世界中拥有一模一样的投影,3D 形状的估计实际上是一个非适定性问题(ill-posed problem)。传统研究主要利用各类几何关系或者先验信息,而近年来随着深度学习的流行,对几何方法的研究似有所忽视。
不久之前,加州大学伯克利分校马毅教授也在微博表示,「……没有任何工具或算法是万灵药。至少在三维重建问题上,没有把几何关系条件严格用到位的算法,都是不科学的—根本谈不上可靠和准确。」

本文试图对 3D 重建做一个简单介绍,并对目前流行的两类方法进行探讨和对比。
术语介绍 (Terminology)
3D 重建是指对物体的真实形状和外观的获取过程,其建模方法可以分为主动式(Active method)和被动式(Passive method)。
主动式(Active method):
在主动式方法中,物体的深度信息是给定的——这可以通过使用激光等光源或能量源向物体发射信号,然后解析返回的信号来获得——重建主要是利用数值近似来还原物体的 3D 轮廓。其中几种主要的方法有:
莫尔条纹法:这是由 Andrew P. Witkin 在 1987 年提出的一种方法,当时他还在 SRI international 的 AI 中心工作。莫尔条纹法依赖的是栅栏状条纹重叠下所产生的干涉影像。该方法的优点是精度高,比较稳健,但是对物体的要求很高——表面必须具有规则纹理。
结构光法:结构光法对物体本身的颜色和纹理稳健,它使用投影仪将被编码的结构光投射到被拍摄物体身上,然后由摄像头进行拍摄。由于被拍摄物体上的不同部分相对于相机的距离和方向不同,结构光编码的图案的大小和形状也会发生改变。这种变化可以被摄像头捕获,然后通过运算单元将其换算成深度信息,再获取三维轮廓。根据编码方式的不同,可以分为直接编码(direct coding)、时分复用编码(time multiplexing coding)和空分复用编码(spatial multiplexing coding)。结构光法实现简单,目前已经大量运用在工业产品中,比如微软的 Kinect,苹果的 iPhone X。但是该方法受强光影响比较大,也受到投影距离的限制。
三角测距法:该方法以三角测量原理为基础,实际上大量运用了几何中相似三角形的原理。三角测距法要求测量系统包含一个激光发射器和一个 CCD 图像传感器。激光发射器发射的一束激光被物体反射后被图像传感器检测到,通过对比在物体发生位移后图像传感器检测到的激光的偏移,可以求解出发射器与物体之间的距离。这种方法的精度较高,成本也低,因而被广泛运用在民用和商用产品中,比如扫地机器人。
被动式(Passive method):
被动式方法在 3D 重建过程中不会与被重建物体产生任何「交互」,主要是利用周围环境获取图像,然后通过对图像的理解来推理物体的 3D 结构。可以分为三类:
单目视觉法(Monocular stereo vision)
主要使用一台摄像机拍摄一张照片来进行 3D 重建。其中又分为:
阴影恢复法 (Shape From Shading,SFS):利用图像的阴影来估计物体的轮廓特征,要使用几种不同光照条件来对比图像的明暗程度和得到的阴影,来估计物体的深度信息。可以想到,SFS 要求光源参数准确,因而在具有复杂光线的场景下无法使用。
纹理恢复形状法 (Shape From Texture,SFT):SFT 主要研究纹理在经过透视等变形后在图像上的变化——如使用鱼眼镜头拍摄的棋盘格子照片,照片边缘的格子会被拉扯变形——并通过这种变形来逆向计算深度数据。该方法要求对畸变信息的了解,同时对物体表面的纹理也有很多限制,很少运用在实际产品中。
双目视觉法(Binocular stereo vision)
在这种方法中,图像是由两个处在不同位置的相机同时对物体进行拍摄而获取的,或者由一个相机不断移动到不同的视点对物体进行拍摄。显然,这一方法试图模拟人类利用双眼感知图像视差而获取深度信息的情况。双目视觉法依赖于图片像素匹配,可以使用模板比对或者对极几何法。
立体视觉法(Multi-view stereo,MVS)
立体视觉法最初是由上述两个研究自然发展而来的,立体视觉法将多个相机设置于视点,或用单目相机在多个不同的视点拍摄图像以增加稳健性,见图 1 示例。在发展的过程中,这一研究领域遇到了许多新的问题——比如,计算量暴增——并演变成一种不同类型的问题。目前这一研究领域十分活跃。

图 1:使用单目相机在不同视点拍摄多张照片用于 3D 重建。图源:Multi-View 3D Reconstruction https://vision.in.tum.de/research/image-based_3d_reconstruction/multiviewreconstruction
早期的立体视觉研究主要在实验室环境中进行,所以相机参数都是已知的。但随着研究者越来越多的使用网络上下载的照片等非实验室环境下获取的图像,在重建工作之前必须首先求得相机位置和 3D 点来估计相机参数。
术语「相机参数」是指描述相机配置的一组值,即,由位置和方向组成的相机姿势信息,以及诸如焦距和像素传感器尺寸的相机固有属性。目前有许多不同的方法或「模型」来参数化这种摄像机配置,一般最常用的是针孔摄像机模型。
这些参数是必须的,因为相机将拍摄的 3D 世界的物体投影到 2D 图像上,而现在我们需要用 2D 图像反推 3D 世界信息。可以说,相机参数是确定物体的世界点和图像点之间相互关系的几何模型的参数。
目前计算摄像机参数主要使用的算法是 Structure from Motion(SfM),MVS 发展成功也在很大程度上依赖于 SfM 的成功。与 SfM 齐名的还有 VSLAM 算法,两者都依赖于图片像素匹配以及场景是刚性的假设。SfM 最常用于计算无序图像集的相机模型,通常是离线的,而 VSLAM 专门从视频流计算摄像机的位置,通常是实时的。
Structure from Motion
大概在初中的物理课上,我们接触过小孔成像的原理。以图 2 为例,我们考虑如何将物体 X 投影到图像上的 x 点。投影中心是 c——又称为相机中心(camera center)——以此为原点可以画出相机坐标系,则物体 X 的坐标为(X,Y,Z)。经过相机中心,并垂直于图像平面的中心线被称为主轴(principle axis),也就是图 2 中的 Z 轴。主轴和相机平面的交点被称为 principal point,并成为图像坐标系的原点 p。p 点和相机中心 c 点的距离为 f,也就是焦距。
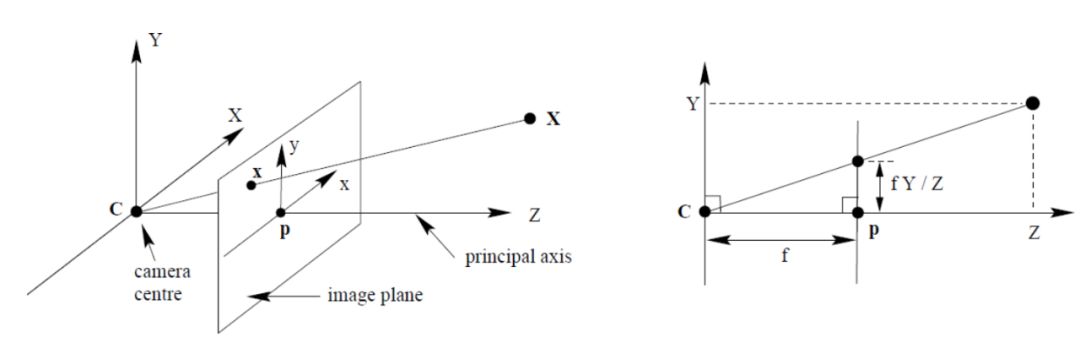
图 2:针孔摄像机模型。图源:Richard Hartley and Andrew Zisserman. Multiple view geometry in computer vision. Cambridge university press, 2003.
根据相似三角形原理(图 2 右侧),我们可以轻易得出相机坐标系和图像坐标系的关系:Z/f = Y/y = X/x
整理后可以得到:
x = f*X/Z
y = f*Y/Z
z = f
即点(X,Y,Z)在图像坐标系中对应的坐标是(fX/Z,fY/Z,f)。这个映射关系对坐标 Z 来讲是非线形的,我们需要通过扩展坐标维度对其线性化,从而进行矩阵运算:
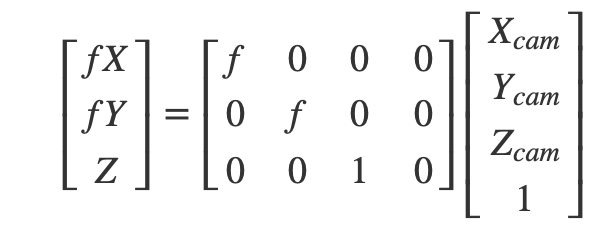
上式中我们使用的图像坐标系以成像平面的中心为原点,实际上我们一般会使用图像的一个角——一般是左上角——作为原点,以水平线为 x 轴,垂直线为 y 轴。因此我们需要对成像坐标系进行缩放和平移,来吻合像素的实际坐标。将图像坐标系上的点在 x 和 y 轴方向上分别缩放 m_x 倍和 m_y,在分别平移 p_x 和 p_y 个点,调整后的矩阵变为:
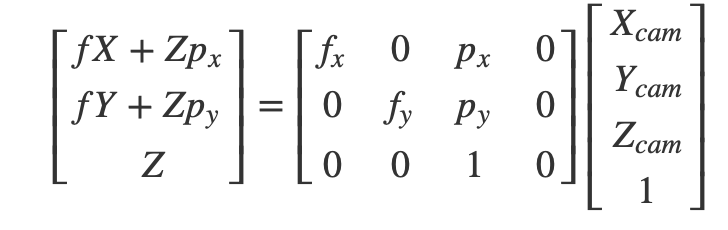
其中 f_x = f*m_x,f_y=f*m_y,有时也写作\alpha_x,\alpha_y。
上式中,等式右边的第一个矩阵就是相机的内参矩阵 K:
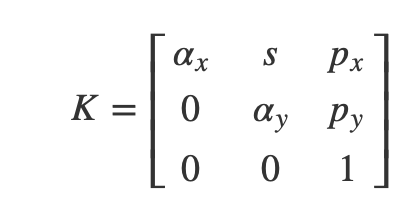
s 是相机的 skew parameter,一般都设置为 0。
接下来,我们需要考虑在上述过程中物体的坐标是如何确定的——实际上,它的坐标是以相机为原点计算的。但相机的位置是可以随时移动的,物体在相机坐标系中的位置也会随之移动,我们需要将物体的坐标转换到世界坐标系中,来获得稳定的坐标位置。
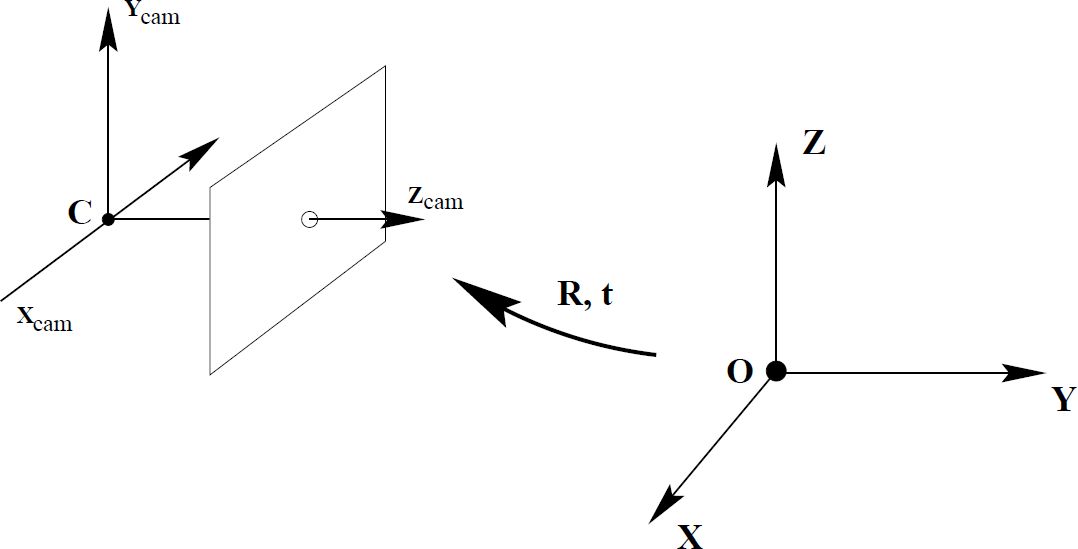
图 3:相机坐标系到世界坐标的转换。图源:Richard Hartley and Andrew Zisserman. Multiple view geometry in computer vision. Cambridge university press, 2003.
同样,相机坐标系和世界坐标系之间的转换可以通过缩放和平移来达到,写作:
X_cam = RX + t
其中 X_cam 和 X 分别是一点在相机坐标系和世界坐标系下的坐标表示,R 为 3x3 的旋转矩阵,t 为 3x1 的平移向量。为了统一运算方式,我们将上式也改写为矩阵形式:
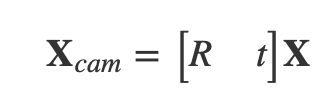
将相机内外参矩阵结合起来,我们就可以获得完整的物体从 3D 世界中被投射到 2D 图像中的坐标转换关系:
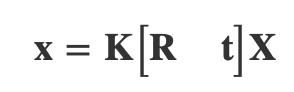
完整的相机矩阵可以总结为:
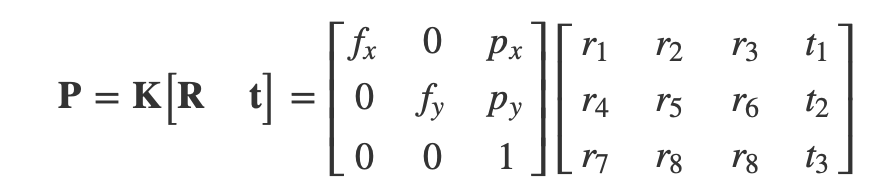
相机外参负责世界坐标系到相机坐标系的转化,内参则负责接下来从相机坐标系到 2D 图像坐标系的转换。
SfM 算法可以在给定一组图像的情况下,直接输出每张图像的相机参数,以及图像中可见的一组 3D 点,一般被编码为 tracks。
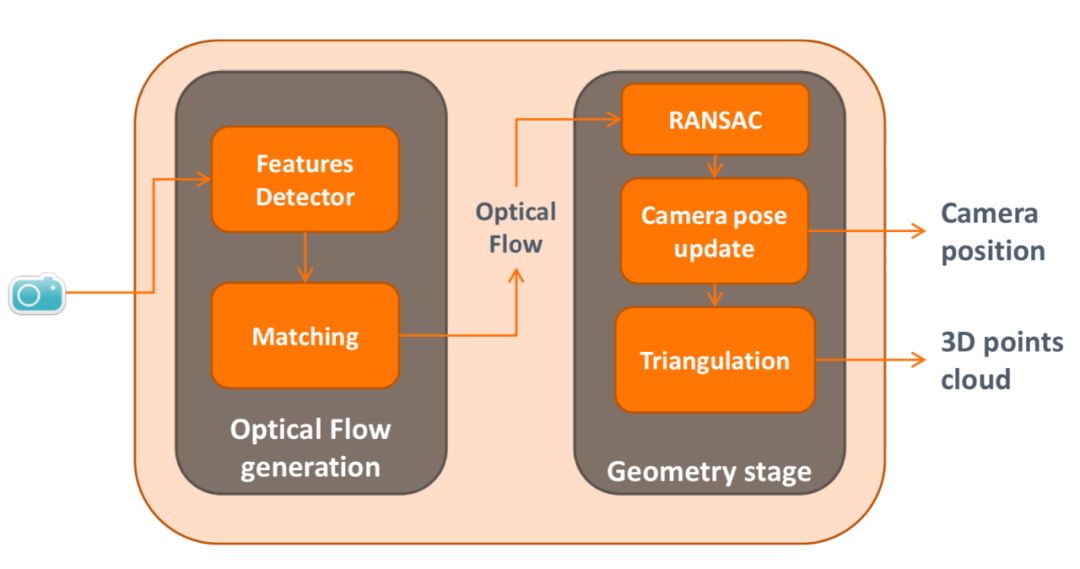
图 4:SfM 算法一般流程。图源:Chippendale, Paul & Tomaselli, Valeria & D'Alto, Viviana & Urlini, Giulio & Modena, Carla & Messelodi, Stefano & Mauro Strano, Sebastiano & Alce, Günter & Hermodsson, Klas & Razafimahazo, Mathieu & Michel, Thibaud & Farinella, Giovanni. (2014). Personal Shopping Assistance and Navigator System for Visually Impaired People. 10.1007/978-3-319-16199-0_27.
SfM 算法的第一步是从图片中抽取一系列特征(feature detector),一般使用尺度不变特征转换 (Scale-invariant feature transform 或 SIFT)。SIFT 通过对图像使用连续高斯模糊来获得不同的图像尺度并在其上寻找可能的关键点,然后舍弃掉其中不明显的关键点。SIFT 算法检测到的关键点通常对光线、视角等变化相当稳健,甚至受视线遮蔽的影响也不大。SIFT 算法的另外一个优点就是计算速度非常快,基本可以满足实时运算。

图 5:SIFT 算法示例。图源:维基百科 URL:https://en.wikipedia.org/wiki/Scale-invariant_feature_transform
确定特征后,一般需要使用 K-D Tree 算法对不同图像中的特征最近邻匹配(matching)。匹配完毕后还需要去除重复匹配和不满足几何约束的匹配,否则误匹配会造成较大的误差,一般使用采样一致性算法 RANSC 八点法来计算几何约束。

图 6: 特征匹配示例。图源:CS 6476: Computer Vision Project 2: Local Feature Matching URL:https://www.cc.gatech.edu/~hays/compvision/proj2/
通过筛选的匹配会被合并为 tracks 用于求解相机参数,估算相机参数场景的稀疏结构。
由于算法对估计的相机模型的准确性非常敏感,因此通常还需要用 bundle adjustment 优化估计结果,主要思想是将求得的 3D 点反向投影到图像中,与初始坐标进行对比并根据误差容忍度进行删减,然后重新调整相机参数。
SfM 有它的缺陷,一个最重要的问题就是由于 SfM 依赖于特征可以跨视图匹配的假设,如果这个假设不满足 SfM 就完全无法工作了。比如如果两张图片之间的视点差距太大(一张从正面一张从侧面)或者局部被遮挡,建立特征匹配是极其成问题的。此外,SfM 由于要通过捆绑调整进行优化,整个算法的运算速度极慢,且速度还会随着图像的增加而大幅下降。
深度学习
使用深度学习,研究者实际上希望能够跳过特征抽取、特征匹配、相机参数求解等手动环节,直接由图像——有时仅需一张——模拟 3D 物体的形状。同时,神经网络应该不仅学习可视部分的结构,同时也能够推理被遮挡部分的结构。
前面提到,3D 物体的表示方法一般有深度图 (depth), 点云 (point cloud), 体素 (voxel), 网格 (mesh) 四种。所以深度学习也可以依次分为学习图像到深度的表示、图像到体素的表示等,不过也有研究试图融合多种表示。由于对输出数据形式有要求,大部分研究使用了 decoder-encoder 结构的神经网络,比如 3D-R2N2 网络 [1](见图 7)。该网络由三个部分组成:2D 卷积神经网络(2D-CNN)组成的 encoder,3D 卷积 LSTM(3D-LSTM)作为中间架构,以及 3D 反卷积网络(3D-DCNN)组成的 decoder,能够将输入图像转化为 3D 物体的体素表示。
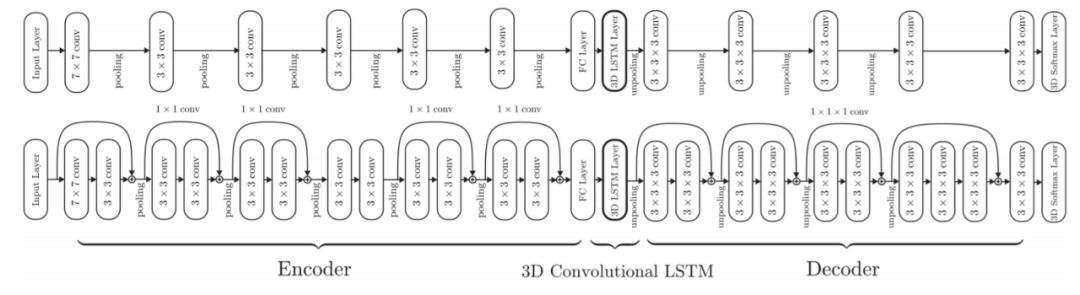
图 7:3D-R2N2 模型结构。图源:C. B. Choy, D. Xu, J. Gwak. (2016). 3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction. ECCV.
给定来自任意视点的对象的一个或多个图像,2D-CNN 首先将输入图像 x 编码为低维特征 T(x)。然后,根据给定的编码输入,3D-LSTM)单元选择性的更新它们的单元状态或维持原状态。最后,3D-DCNN 解码 LSTM 单元的隐藏状态并生成 3D 概率体素重建。[1] 指出使用基于 LSTM 的网络的主要原因是这样的网络可以有效应对物体被遮挡的情形,因为网络仅更新对应于物体可见部分的单元。如果后续视图显示先前被遮挡的部分,且这部分与网络预测不匹配,则网络将更新先前被遮挡的部分的 LSTM 状态,但保留其他部分的状态。
但使用体素表示带来的一个挑战是模型的计算量会随着分辨率增高指数级的增长,如果分辨率限制到了 32*32*3 以下以降低对内存的要求则会使得输出结果丢失很多细节。有些研究通过对输出空间进行分层划分,以实现计算和存储效率 [2, 3, 4],其中 Maxim Tatarchenko 等学者提出的 Octree 网络 [4] 取得了显著的分辨率的提高,甚至可以达到 512^3。
在计算量上,使用神经网络学习深度图会更有优势。以 D. Eigen 等学者的研究 [5] 为例,他们可以仅使用卷积层,同时试图将更高的分辨率显式的编码进神经网络的结构中。
D. Eigen 等学者提出的神经网络分为两部分:全局粗粒度网络和局部细粒度网络(见图 8)。粗粒度网络的任务是使用场景的全局视图来预测整个深度图结构。该网络的上层完全连接,因此在其视野中可以包含整个图像。粗粒度网络包含五个卷积和最大池的特征提取层,后面是两个全连接层。输入,特征映射和输出大小也在下图中给出。与输入相比,最终输出会被下采样 4 倍。细粒度网络会接收到粗粒度网络的预测和输入图片,以完成对粗略预测和局部细节的对齐。细粒度网络除了用于连接输入图像和粗略预测的串联(concatenation)层以外,只包含卷积层。
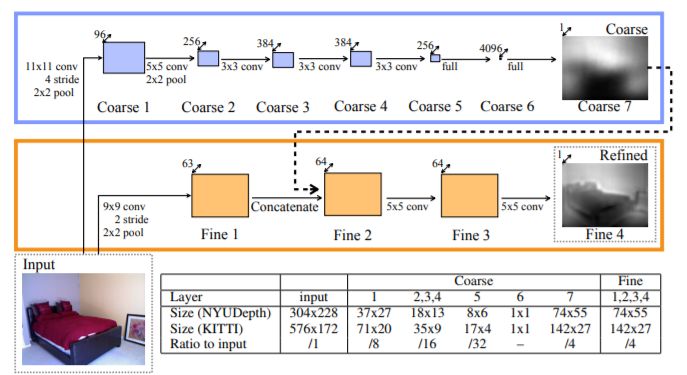
图 8:D. Eigen 等学者提出的神经网络模型结构。图源:D. Eigen, C. Puhrsch, and R. Fergus. (2014). Depth map prediction from a single image using a multi-scale deep network. NIPS.
这个模型在当时取得了 state-of-art,但实际上预测还是十分粗糙的,有时模型的预测只能看出物体的大概轮廓。为了进一步提高分辨率,D. Eigen 等学者此后也对模型进行过一些改进。包括将网络从两部分扩展到三部分,从而提高一倍分辨率,但仍然只有输入图像分辨率的一半。
将神经网络应用在剩余的两种数据形式——点云和网格——上的话,还要额外面对一个困难:点云和网格不是规则的几何数据形式,无法直接使用。稍早一点的研究,比如 D. Maturana 和 S. Scherer. Voxne 提出的 Voxnet [6] 以及 Z. Wu 等学者提出的 3D shapenets [7] 都是先将数据转化为体素形式或者图像表示,然后在体素化的数据上进行训练。但这会极大的增加计算负担,同时还可能模糊数据。此后有一些研究试图令神经网络学习网格的几何特征,比如 Jonathan Masciy 等学者提出的 Geodesic convolutional neural networks [8]。
总的来看,如果需要从四种表现形式中选择一个的话,使用体素的重构精度一般是最高的,使用深度图最容易将重建任务迁移到深度学习上。目前的 state of the art 是由 Stephan R. Richter 和 Stefan Roth 提出的 Matryoshka Networks [9],该网络使用由多个嵌套深度图组成的形状表示。
损失函数方面,由于数据的形式不一,目前没有统一使用的损失函数,常用的有 scale-invariant error 和交叉熵等。衡量精度使用的标准则以 RMSE 和 IoU 居多。
几何方法对比深度学习方法
Maxim Tatarchenko 等学者 [10] 认为,实际上目前表现最好的深度学习算法实际上学习到的是图像分类,而非图像重建。他们设计了几个简单的基线算法,一个为 K-means 算法,将训练集中的形状聚类为 500 个子类别;一个 retrieval 算法将数据集中的形状投射到低维空间中求解和其他形状的相似度;还有一个最近邻算法(Oracle NN)根据 IoU,为测试集中的 3D 形状找到与训练集最接近的形状。这个方法不能在实践中应用,但可以给出检索方法应对这一任务所能取得的表现的上限。
在 ShapeNet 数据集上的测试显示,没有任何一个神经网络算法可以超过最近邻算法(Oracle NN)的表现,也就是说,测试结果中 mean IoU 最高甚至还不超过 0.6。

图 9:模型在测试数据上的表现示例。图源:M. Tatarchenko, S. R. Richter, R. Ranftl, Z. Li, V. Koltun, T. Brox. (2019). What Do Single-view 3D Reconstruction Networks Learn? arXiv:1905.03678v1.
图 9 给出了几个模型在一些测试数据上的表现,可以看到作者设计的基线模型的表现基本与神经网络相同。每个样本右下角的数字表示 IoU,基线模型通过搜索相似的形状可以保证整体形状的正确性,但细节可能不正确。
另外一个令人惊讶的发现是,如果将各个对象类的 IoU 分数的直方图可视化的话,会发现神经网络和两个基线方法的类内分布十分相似。然而,这两个基线方法本质上是图像识别方法。
作者对 55 个类和所有测试方法的直方图进行了 Kolmogorov-Smirnov 检验。该检验的原假设是两个分布没有表现出统计学上的显着差异。图 10 中的右侧给出了三个例子,左侧的热图(heat map)中的每个单元显示了统计测试不允许拒绝原假设的类的数量,即 p 值大于 0.05。可以看到,绝对大多数类都不能拒绝深度学习方法和两个基线方法的直方图分布一样的原假设。而最近邻方法则和其他方法有比较明显的不同。
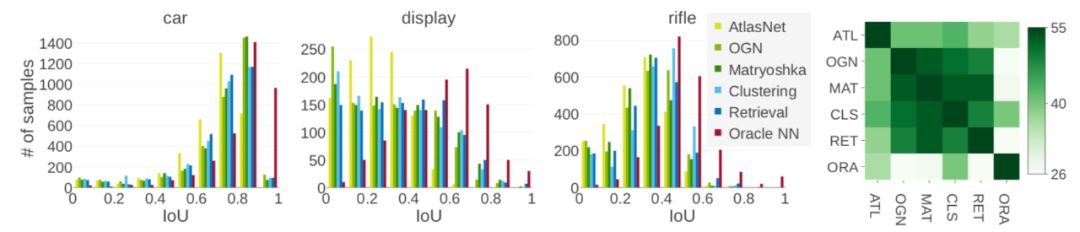
图 10:测试方法的 IoU 直方图对比及 Kolmogorov-Smirnov 检验结果。图源:M. Tatarchenko, S. R. Richter, R. Ranftl, Z. Li, V. Koltun, T. Brox. (2019). What Do Single-view 3D Reconstruction Networks Learn? arXiv:1905.03678v1.
即便我们忽略深度学习到底在训练中习得了什么这一问题,而仅关注神经网络的重建表现,D. Eigen 等学者的研究 [1] 中所展现出来的结果也是十分值得讨论的。作者使用了 4 种不同类别的高质量 CAD 模型,通过手动编辑纹理将其纹理强度增强到低,中和高,并且渲染出了不同视角。比较用的 MVS 算法是 Patch-Match,通过 global SfM 估计相机位置。重建效果由体素表示,用 IoU 衡量,由于 Patch-Match 生成的 3D 物体是由网格表示的,还需要将其体素化用于比较,最终输出大小为 32×32×32。

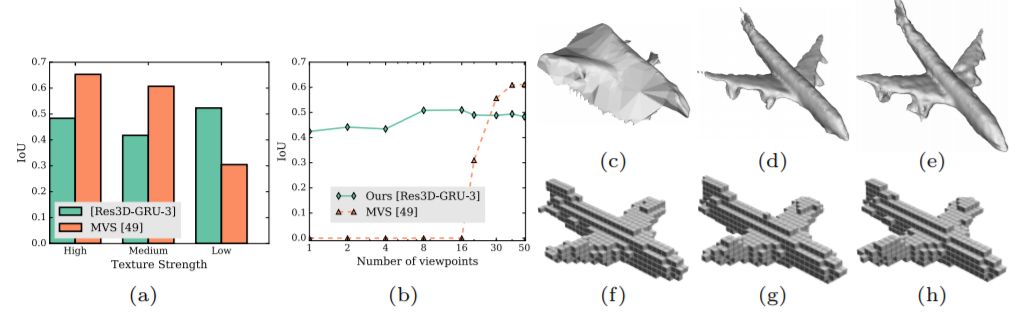
图 11:测试数据示例和比较结果。图源:C. B. Choy, D. Xu, J. Gwak. (2016). 3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction. ECCV.
上图第一行给出了使用的测试数据的例子,从左到右依此为具有各种视点的图像和纹理水平从高到低的图像。测试结果很有意思——3D-R2N2 和 Patch-Match 算法的优缺点几乎是完全相反的。从上图 a)中可以看出当 Patch-Match 方法遇上低纹理水平的物体,预测精度会大大下降。另一方面,在满足 Patch-Match 算法的假设的情况下(物体纹理水平较高),Patch-Match 算法的精度远远大于 3D-R2N2,即便输出数据的大小仅有 32x32x32。在学习深度的神经网络研究中我们也有看到,神经网络的预测还是以轮廓为主,细节上面有缺失。作者认为这主要是因为训练数据有偏置,大部分都是纹理级别较低的数据,因为实际上 3D-R2N2 在纹理级别增高以后表现下降了。上图 b)则展示了当视点不足的时候,Patch-Match 算法完全无法运行,而 3D-R2N2 则不受这个影响。但 Patch-Match 算法的精度可以随着视点的增多而得到提升,3D-R2N2 无法重建一样多的细节。
上图(c)到(h)则给出了分别给定 20,30 和 40 个视点的高纹理飞机模型时,3D-R2N2 和 Patch-Match 的表现。其中(c-e)是 Patch-Match 的重建结果,(f-h)是 3D-R2N2 的重建结果。可以看到 3D-R2N2 的预测的确差别不大,而 Patch-Match 则从完全无法辨认的预测提升到了流畅、精细的重建结果。
笔者看到这一结果的时候,感觉这几乎完全是 no free lunch theory 重现。由于深度学习算法仅用一张图像作为输入,可以使用的信息减少了,在适用性增大的同时带来的一定是最优表现的下降。Yasutaka Furukawa 在他的书中 [11] 也有强调,「An MVS algorithm is only as good as the quality of the input images and camera parameters」。
另外,目前深度学习的研究还存在两个问题——如何衡量模型表现以及使用什么训练数据。
前文提到,平均 IoU 通常用作基准单视图重建方法的主要量化指标。但将其用唯一指标可能是有问题的,因为只有 IoU 足够高时,才能表示预测形状的质量。低到中等分数表明两种形状之间存在显着差异。例子见下图。

图 11:不同生成结果的 IoU。图源:M. Tatarchenko, S. R. Richter, R. Ranftl, Z. Li, V. Koltun, T. Brox. (2019). What Do Single-view 3D Reconstruction Networks Learn? arXiv:1905.03678v1.
针对第二个问题,目前深度学习使用的训练集主要是 ShapeNet 数据集。然而,该数据集的测试集中的形状与训练集中的形状非常相似。以 ShapeNet 为数据集训练出的重建模型可以很轻易的找到捷径——它只需要从训练集中检索类似的形状。在 Maxim Tatarchenko 等学者的研究中我们也看到了这一现象。
至此,我们已经讨论了目前常用的一些算法,笔者在表一中对这些算法的各方面表现进行了总结。

未来方向
可以看到,几何算法和深度学习方法的优缺点完全不一样。在条件不允许的时候,用一张图片恢复 3D 结构是有价值的;但当更多数据可获取的时候,尽可能的利用信息一定是更好地选择。并且专注于从单张图像恢复 3D 结构的深度学习研究实际上是假设单张单目图像可以检测到三维信息的,而这从理论上来讲应该是不可能的,这也是为什么大部分生物都有两只眼睛。
此外,在产品化上,如何与具体应用结合——比如如何将三维视觉应用于 AGV、无人驾驶上——是十分值得探索的。这个过程也一定会带来更多的挑战,包括但不限于:
算法的部署、嵌入,嵌入式 SLAM 已经得到了很多的研究,但在 SfM 领域这方面的关注还不足
计算速度的提高,嵌入式系统对算法运算速度的要求是极高的,如何优化目前 SfM、深度学习等计算量巨大的算法,使其满足实时运行的要求
传感器的融合,就像目前无人驾驶汽车的视觉系统往往会部署相机、雷达等多种传感器一样,三维重建走向工业界后一定也需要收集多类数据来应对复杂的视觉环境,这必然要求三维重建系统可以应对不同类型的数据并对其进行综合分析
面对实际运用算法时的将所处复杂环境,几何算法和深度学习方法实际上可以是互补的,并不一定要做二选一的决定。以几何方法做主导,用深度学习强大的特征表达能力来补充几何方法不适用的情况是一种发展趋势。
资源
软件库:
PCL(Point Cloud Library,点云库)(http://pointclouds.org (http://pointclouds.org/))
Meshlab: the open source system for processing and editing 3D triangular meshes.(http://www.meshlab.net/)
Colmap: a general-purpose Structure-from-Motion (SfM) and Multi-View Stereo (MVS) pipeline with a graphical and command-line interface.(https://colmap.github.io/)
教材:
Multi-View Stereo: A Tutorial Yasutaka Furukawa(https://www.nowpublishers.com/article/Details/CGV-052)
Richard Hartley and Andrew Zisserman. Multiple view geometry in computer vision. Cambridge university press, 2003.(https://www.robots.ox.ac.uk/~vgg/hzbook/)
D. Scharstein, R. Szeliski. (2001). A Taxonomy and Evaluation of Dense Two-Frame Stereo Correspondence Algorithms. Proceedings IEEE Workshop on Stereo and Multi-Baseline Vision (SMBV 2001). (http://vision.middlebury.edu/stereo/taxonomy-IJCV.pdf)
NYU course slide Lecture 6: Multi-view Stereo & Structure from Motion (https://cs.nyu.edu/~fergus/teaching/vision_2012/6_Multiview_SfM.pdf)
数据集:
Shapenet dataset(https://www.shapenet.org/about)
文本作者为机器之心分析师 Yuanyuan Li。她几次转行,本科国际贸易,研究生转向统计,毕业后留在欧洲,选择从事机械研发工作,主要负责图像处理,实现计算机视觉算法的落地。欣赏一切简单、优雅但有效的算法,试图在深度学习的簇拥者和怀疑者之间找到一个平衡。希望在这里通过分享自己的拙见、思想的碰撞可以拓宽自己的思路。
机器之心个人主页:https://www.jiqizhixin.com/users/a761197d-cdb9-4c9a-aa48-7a13fcb71f83
参考文献:
[1] C. B. Choy, D. Xu, J. Gwak. (2016). 3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction. ECCV.
[2] C. Hane, S. Tulsiani, and J. Malik. (2017). Hierarchical surface prediction for 3D object reconstruction. 3DV.
[3] G. Riegler, A. O. Ulusoy, H. Bischof, and A. Geiger.(2017). OctNetFusion: Learning depth fusion from data. 3DV.
[4] M. Tatarchenko, A. Dosovitskiy, and T. Brox. (2017). Octree generating networks: Efficient convolutional architectures for high-resolution 3D outputs. ICCV.
[5] D. Eigen, C. Puhrsch, and R. Fergus. (2014). Depth map prediction from a single image using a multi-scale deep network. NIPS.
[6] D. Maturana; S. Voxne. (2015). VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition. IROS.
[7] Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang and J. Xia. (2015). 3D ShapeNets: A Deep Representation for Volumetric Shape Modeling. CVPR.
[8] J. Masci, D. Boscaini, M. M. Bronstein, P. Vandergheynst. (2015). Geodesic convolutional neural networks on Riemannian manifolds. arXiv:1501.06297.
[9] S. R. Richter and S. Roth. (2018). Matryoshka networks: Predicting 3D geometry via nested shape layers. CVPR.
[10] M. Tatarchenko, S. R. Richter, R. Ranftl, Z. Li, V. Koltun, T. Brox. (2019). What Do Single-view 3D Reconstruction Networks Learn? arXiv:1905.03678v1.
[11] Y. Furukawa and C. Hernández. (2015). Multi-View Stereo: A Tutorial. Foundations and Trends® in Computer Graphics and Vision. 9(1-2):1-148.
深度Pro
理论详解 | 工程实践 | 产业分析 | 行研报告
机器之心最新上线深度内容栏目,汇总AI深度好文,详解理论、工程、产业与应用。这里的每一篇文章,都需要深度阅读15分钟。
今日深度推荐

点击图片,进入小程序深度Pro栏目
PC点击阅读原文,访问官网
更适合深度阅读
www.jiqizhixin.com/insight
每日重要论文、教程、资讯、报告也不想错过?



