稀缺资源语言神经网络机器翻译研究综述
摘要: 作为目前主流翻译方法的神经网络机器翻译已经取得了很大突破, 在很多具有丰富数据资源的语言上的翻译质量也不断得到改善, 但对于稀缺资源语言的翻译效果却仍然并不理想. 稀缺资源语言机器翻译是目前机器翻译领域的重要研究热点之一, 近几年来吸引了国内外的广泛关注. 本文对稀缺资源语言机器翻译的研究进行比较全面的回顾, 首先简要介绍了与稀缺资源语言翻译相关的学术活动和数据集, 然后重点梳理了目前主要的研究方法和一些研究结论, 总结了每类方法的特点, 在此基础上总结了不同方法之间的关系并分析了目前的研究现状. 最后, 对稀缺资源语言机器翻译未来可能的研究趋势和发展方向进行了展望,并给出了相关建议.
神经网络机器翻译(Neural Machine Translation, NMT)于2013年正式出现[1]. 在短短几年的时间里, 从最初的RNN encoder-decoder结构[2], 到基于注意力机制的RNN search模型[3]及其各种变体, 再到目前最流行的Transformer架构[4]以及随后多样的预训练模型, NMT以其独特的优势迅速成为主流的翻译方法, 翻译技术取得了巨大突破, 翻译质量也不断得到改善和提高.
NMT的成功与算力资源、算法模型和数据资源密不可分, 尤其依赖于海量的双语数据资源. 而获取高质量的双语资源往往需要很多高昂的代价, 另一方面, 世界上目前现存的很多语言在双语数据资源方面却十分匮乏甚至缺失. 在机器翻译领域的研究中, 这些语言一般称为“稀缺资源语言”, 也称为“低资源语言”(low-resource languages). 本文接下来会交替使用这两种术语.
在数据因素的制约下, NMT在低资源语言中的翻译效果仍然并不理想. 而低资源语言机器翻译一直具有很多实际的需求和应用场景, 因此引起了国内外学术界和业界的广泛关注, 已经成为当前机器翻译领域的重要研究热点之一, 也出现了很多值得关注的研究成果.
Google、Facebook、CMU和爱丁堡大学等在低资源语言机器翻译上做了很多研究. 国内机器翻译领域也非常重视这方面的研究. 中科院自动化所、清华大学、苏州大学、东北大学、昆明理工大学、北京理工大学等多个科研团队在承担低资源语言机器翻译国家级科研项目、自主研发实用翻译系统等方面都积极推动深入的技术交流与合作, 同时在全国机器翻译大会等多种学术活动都有广泛、密切的研讨,推动了这个方向的研究进展[5-8].
随着国内外研究的发展和深入, 我们认为很有必要对目前稀缺资源语言机器翻译的研究进展进行比较全面的回顾. 本文期望能够为机器翻译和相关领域的研究者提供有益的参考, 帮助他们更好地深入了解低资源语言机器翻译的研究动态和选择未来的研究方向.
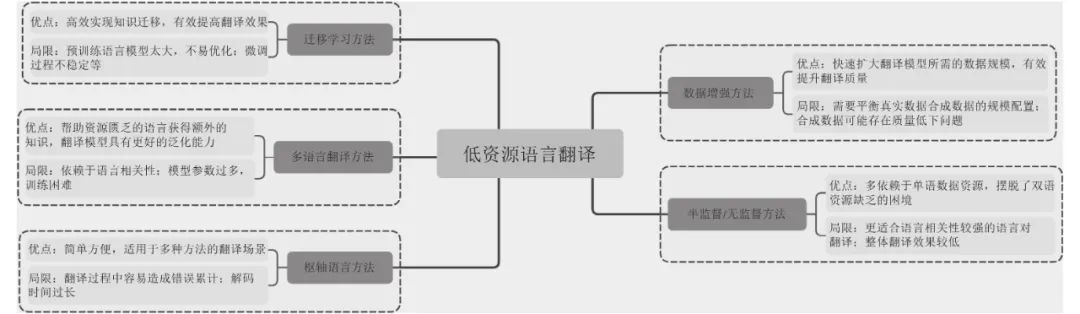
本综述的剩余部分组织如下: 第1节介绍了与低资源语言机器翻译相关的学术活动和公开的数据资源; 第2节详细梳理归纳了目前比较重要和常用的低资源翻译方法和技术, 并总结了它们各自的特点; 第3节总结了这些方法之间的关系, 第4节分析了当前研究现状的主要特点; 最后对未来的研究趋势和发展方向提出了展望和建议.
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c200103
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“LRNMT” 就可以获取《稀缺资源语言神经网络机器翻译研究综述》专知下载链接





