NLP领域预训练模型的现状及分析
作者 | 王泽洋
单位 | 小牛翻译
编辑 | 唐里
本文为东北大学自然语言处理实验室研究生王泽洋投稿,王泽洋研究方向为机器翻译。
小牛翻译,核心成员来自东北大学自然语言处理实验室,由姚天顺教授创建于1980年,现由朱靖波教授、肖桐博士领导,长期从事计算语言学的相关研究工作,主要包括机器翻译、语言分析、文本挖掘等。团队研发的支持140种语言互译的小牛翻译系统已经得到广泛应用,并研发了小牛翻译云(https://niutrans.vip)让机器翻译技术赋能全球企业。
一、预训练方法发展
基于词嵌入的预训练方法
基于语言模型的预训练方法
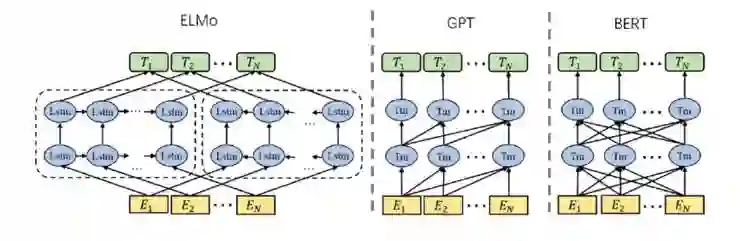
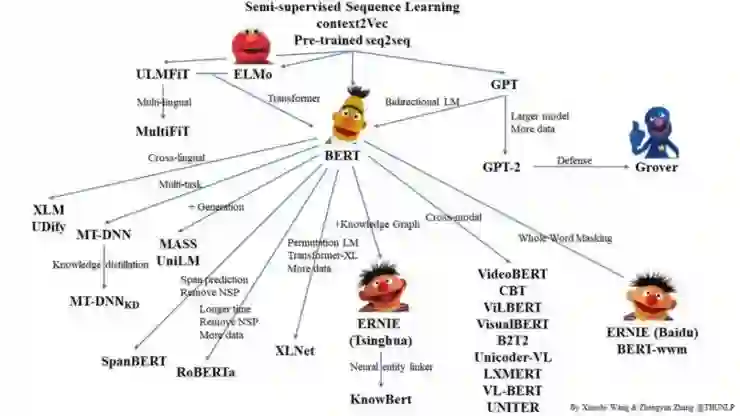
二、Cross-lingual Language Model Pretraining(XLM)[7]
1、多语言分类任务
在BERT中,每个样本是用一种语言构建的。XLM对它的改进是每个训练样本都包含两种语言的相同文本。与BERT一样,该模型的目标是预测被屏蔽的词,但采用新的体系结构,该模型可以使用一种语言的上下文来预测另一种语言的词。因为不同语种的被屏蔽词是不同的(随机)。改造后的BERT表示为翻TLM(Translation Language Model),而带有BPE输入的“原始” BERT表示为MLM(Masked Language Model)。通过训练MLM和TLM并在它们之间交替进行训练来训练完整的模型。
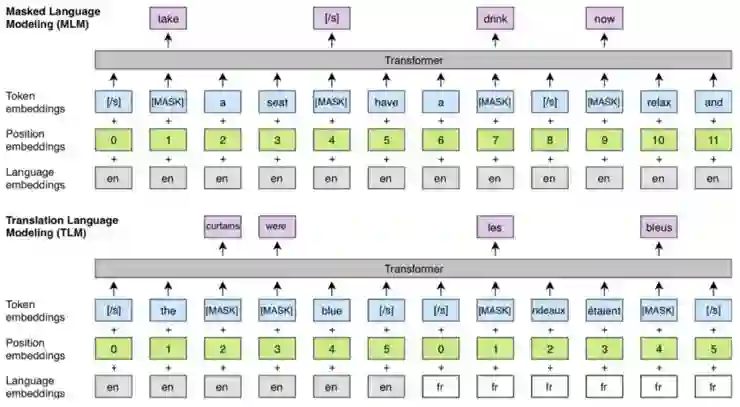
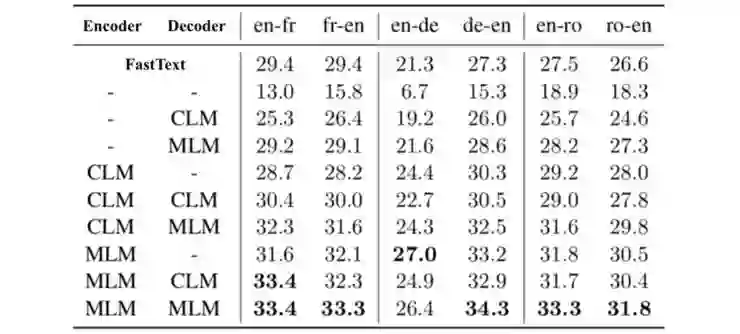
2、无监督机器翻译
三、Masked Sequence to Sequence pre-training(MASS) [8]
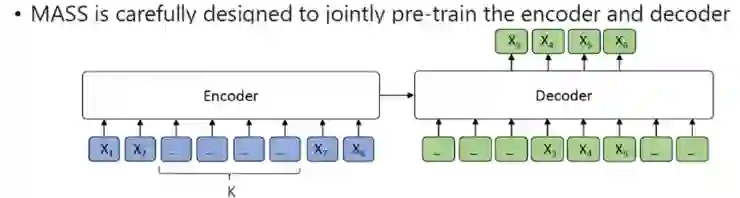
-
Encoder被强制去抽取未被屏蔽掉词的语义,以提升Encoder理解源序列文本的能力。 -
Encoder端其它词(在Encoder端未被屏蔽掉的词)都被屏蔽掉,可以让Decoder从Encoder端提取信息来帮助连续片段的预测。 -
Encoder预测连续的序列片段可以提升Encoder的语言建模能力。
四、XLNet: Generalized Autoregressive Pretraining for Language Understanding
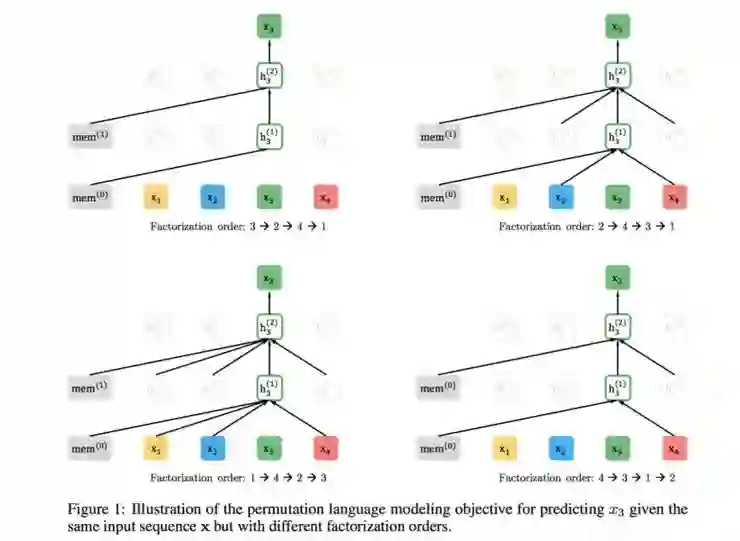
五、结论



登录查看更多
相关内容

专知会员服务
79+阅读 · 2019年12月29日



相关VIP内容
专知会员服务
79+阅读 · 2019年12月29日
相关资讯
相关论文