神经正切核,深度学习理论研究的最新热点?
选自Rajat's Blog
作者:Rajat Vadiraj Dwaraknath
机器之心编译
想理解神经网络的训练动态过程,不妨从「神经正切核」入手。那么什么是神经正切核,核机制如何运行?就读于印度理工学院马德拉斯分校电气工程系的 Rajat Vadiraj Dwaraknath 撰文介绍了这一概念。
博客地址:https://rajatvd.github.io/NTK/
文章动图地址:https://github.com/rajatvd/NTK
神经正切核相关论文地址:https://arxiv.org/abs/1806.07572
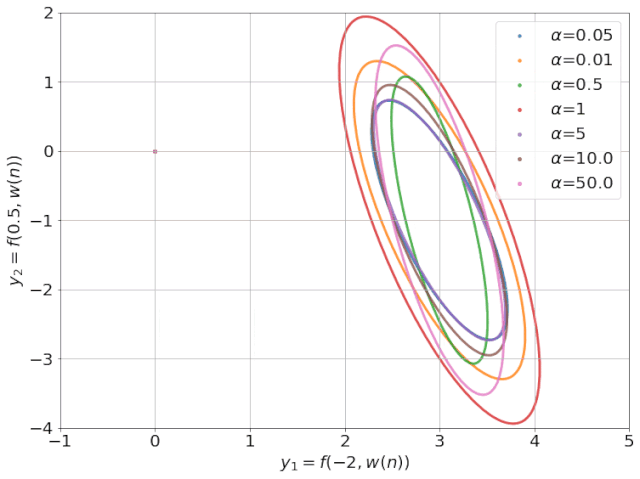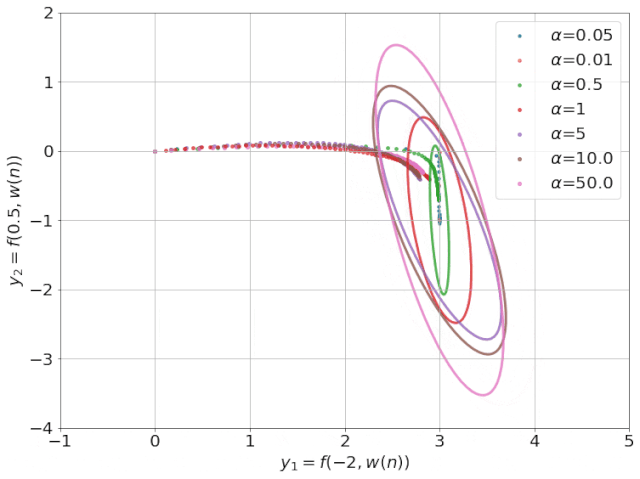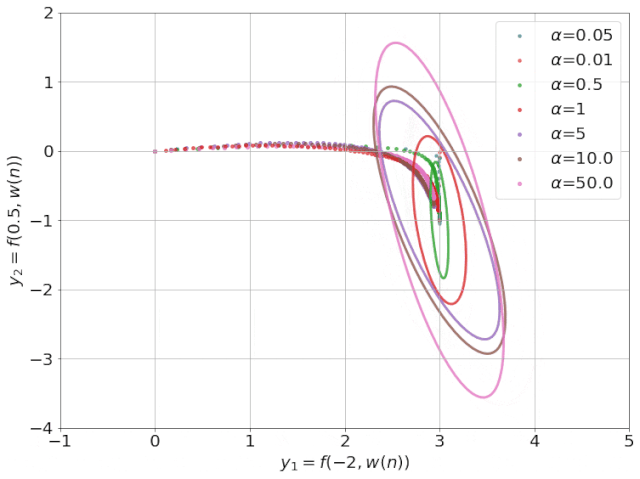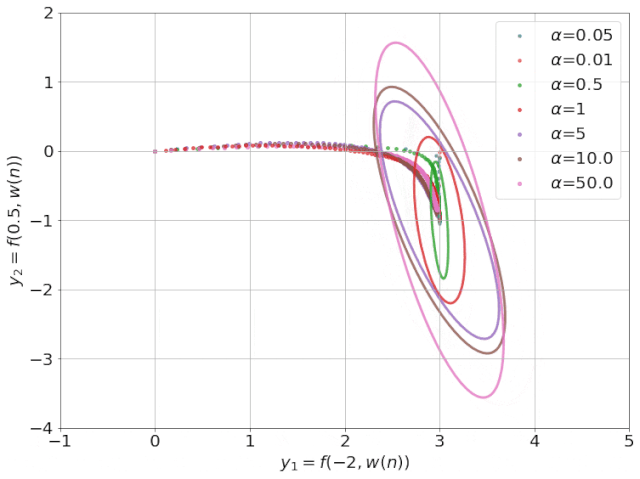
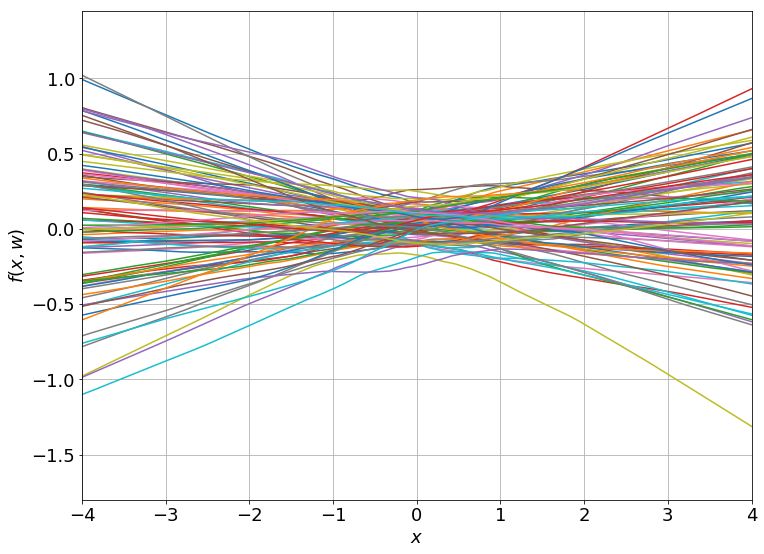
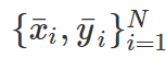
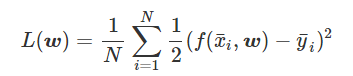
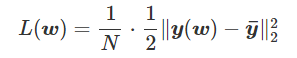
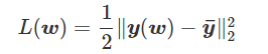
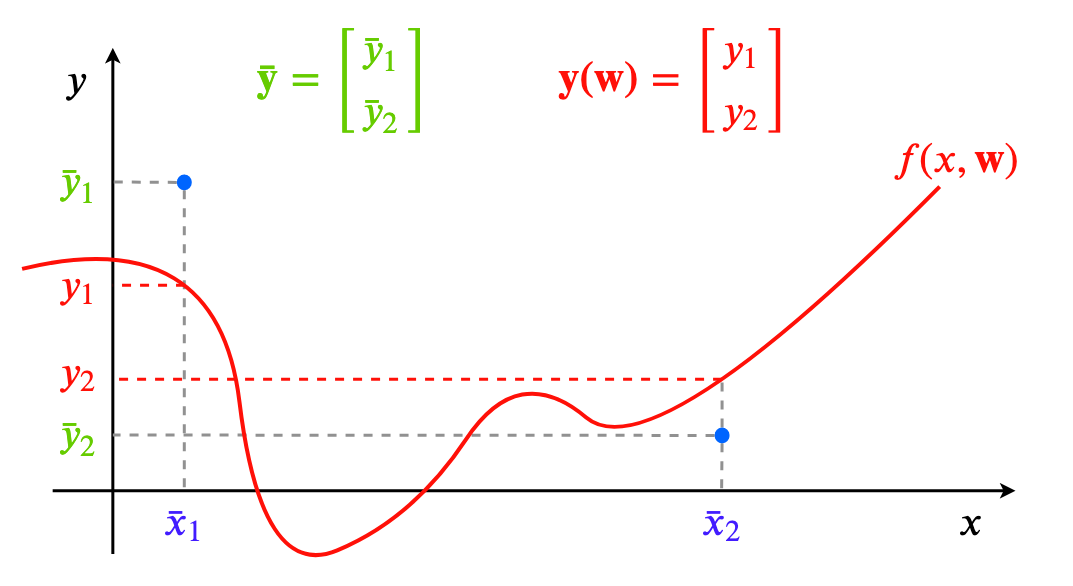
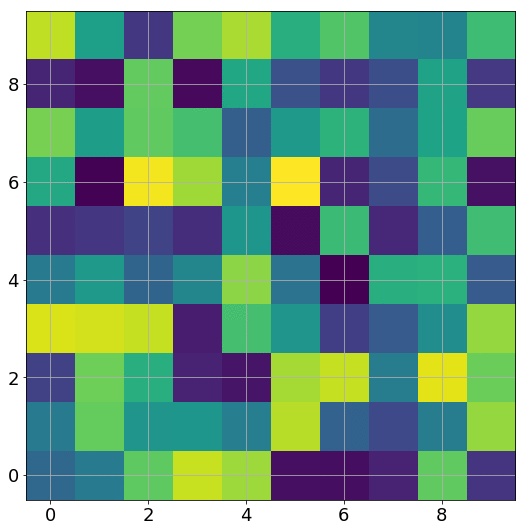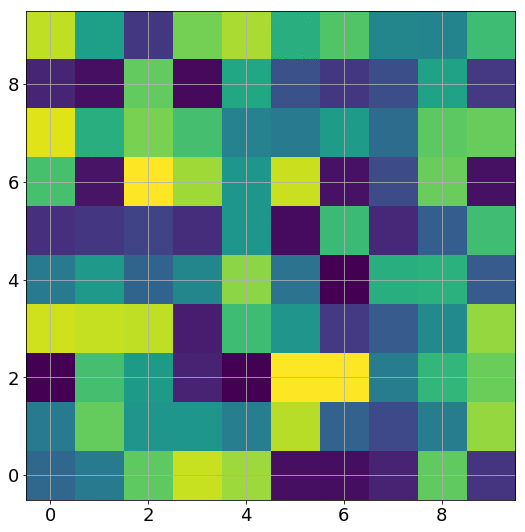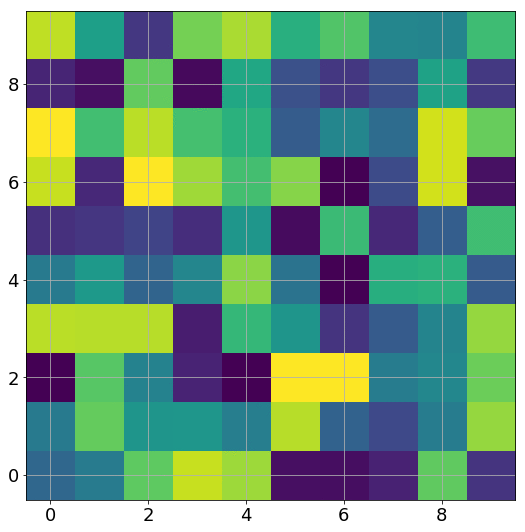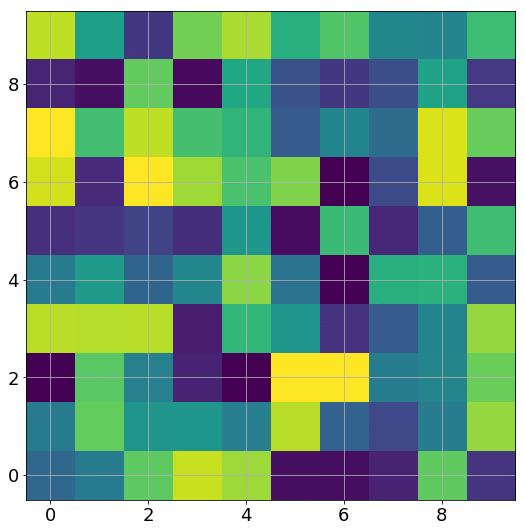
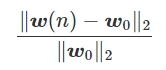
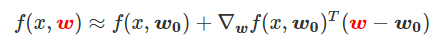
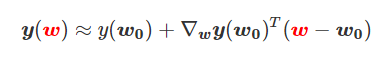
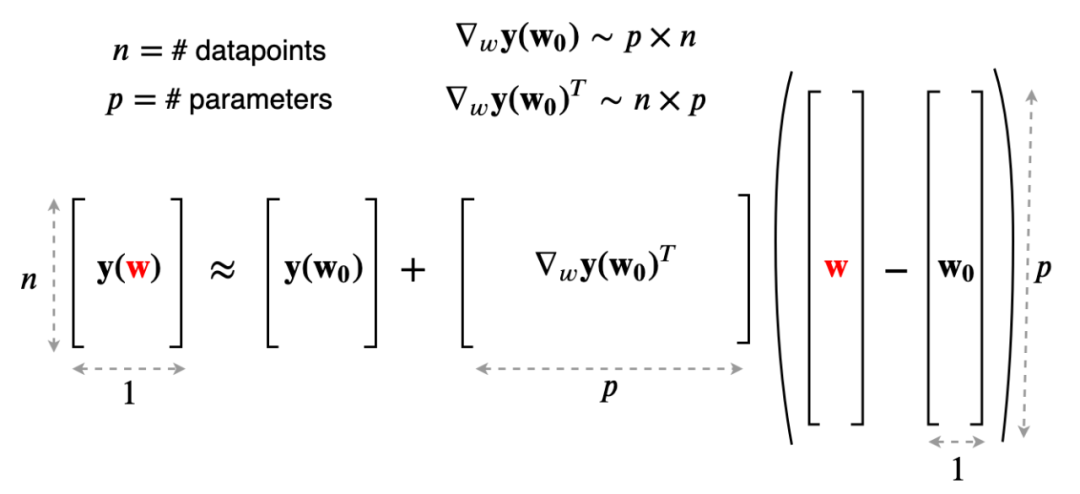
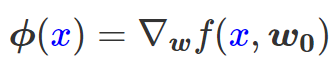
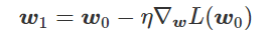
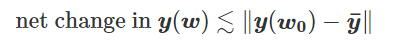
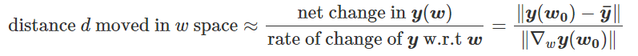
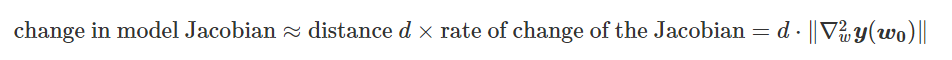
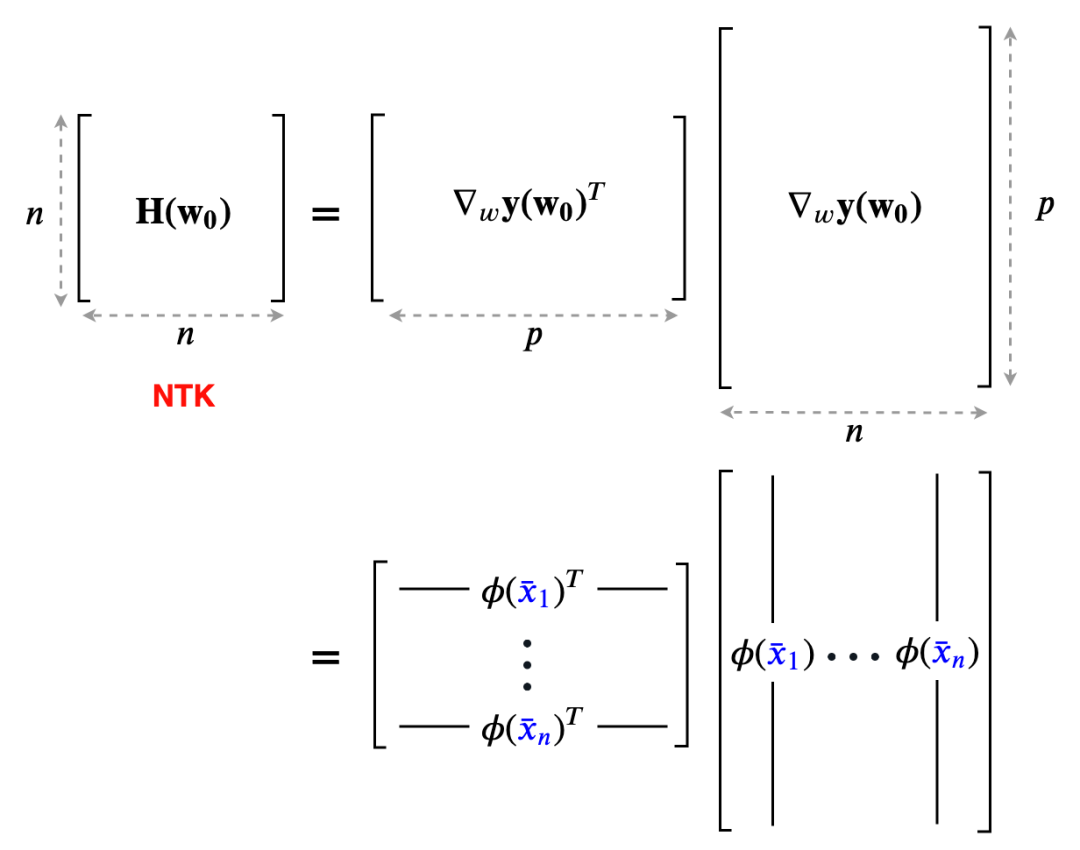
为得到 y 的变化 ‖(y(w_0)−y¯)‖,w 需要变化的量将导致雅可比矩阵∇_w y(w) 的细微变化。

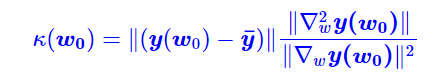
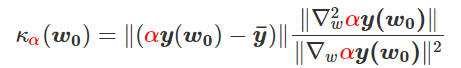
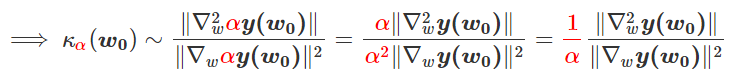
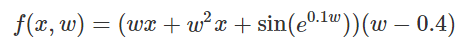
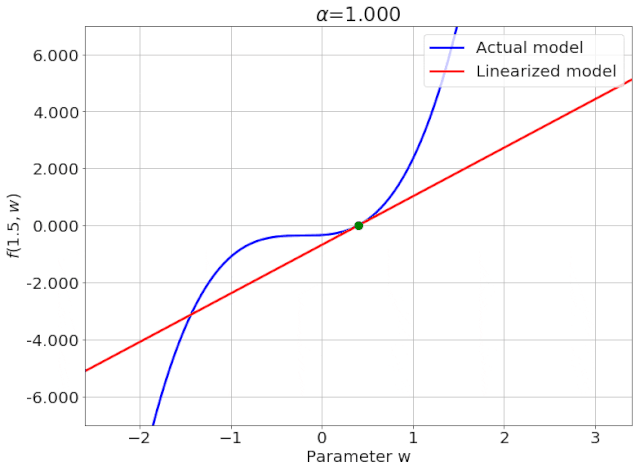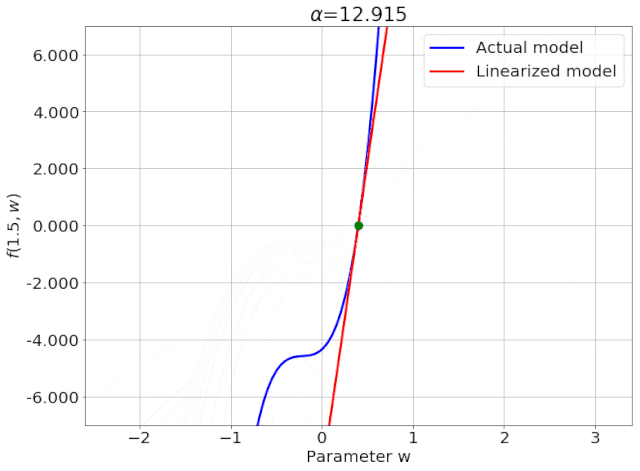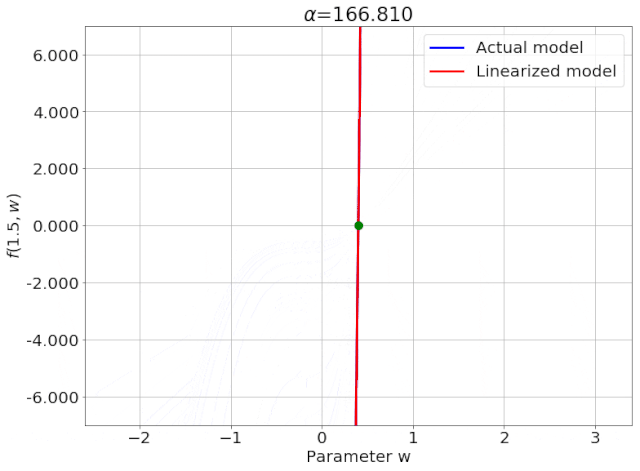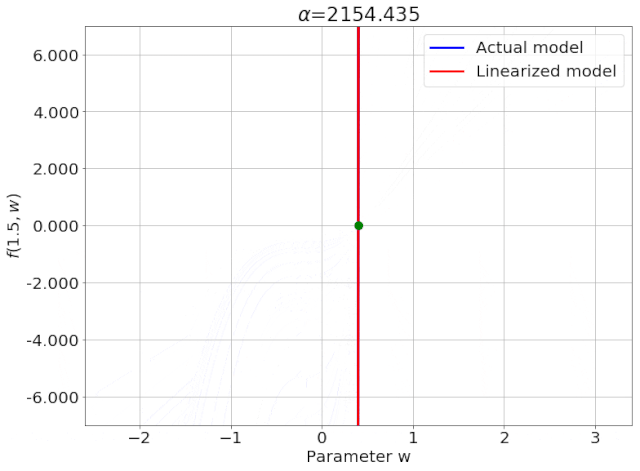
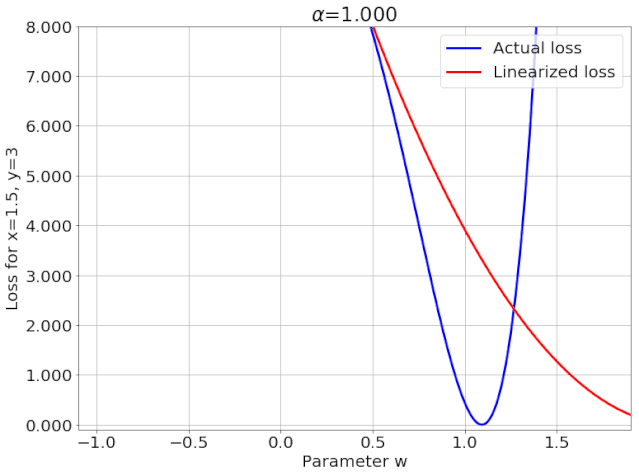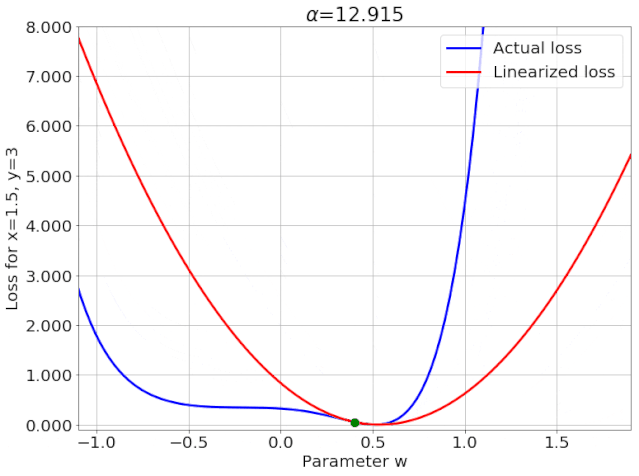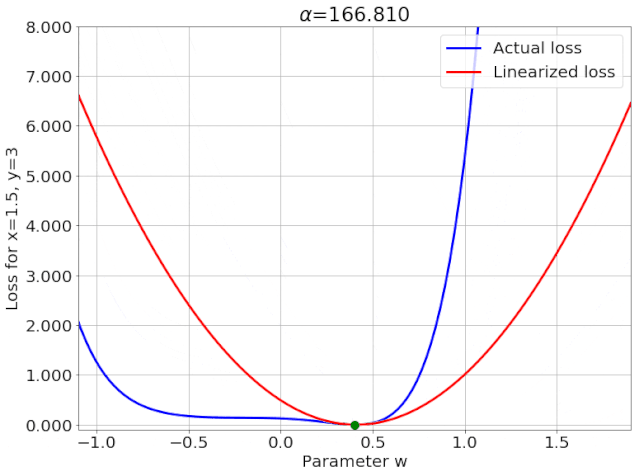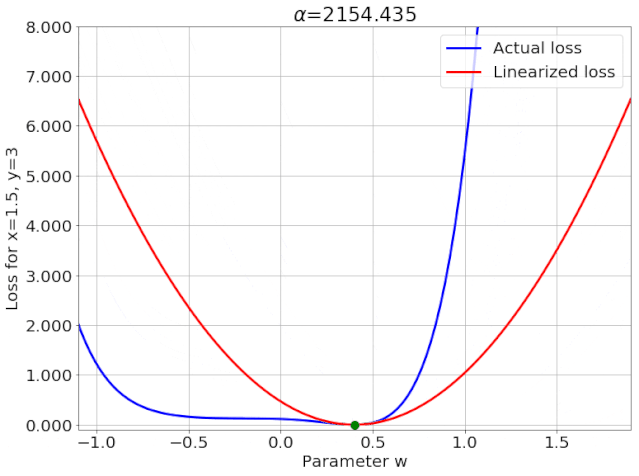
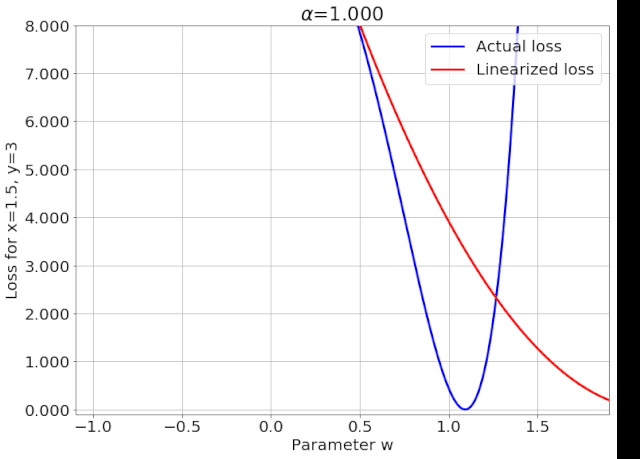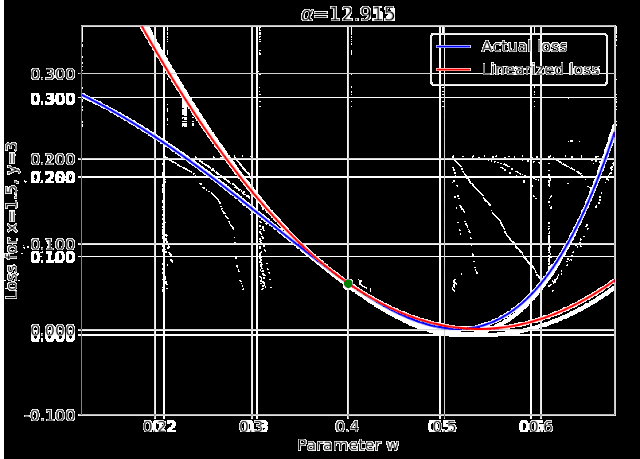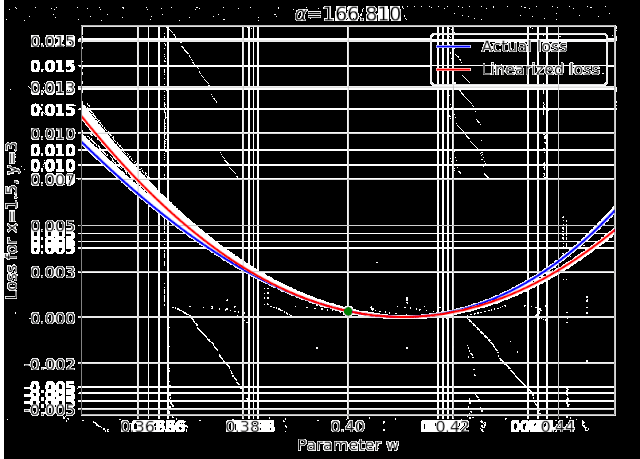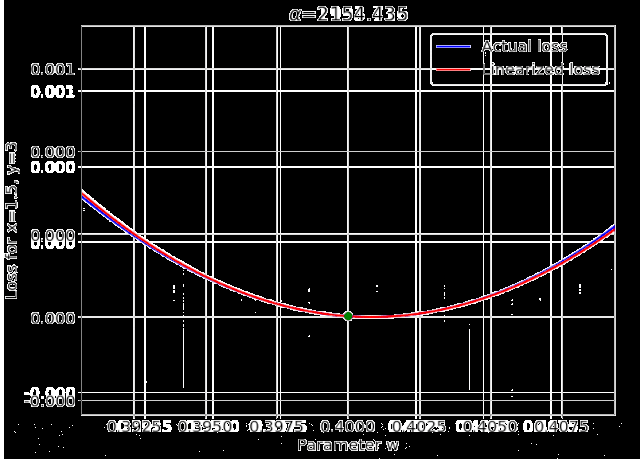
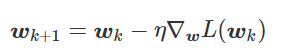
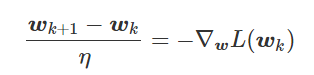
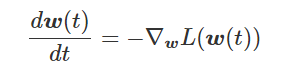
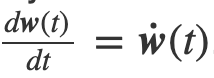
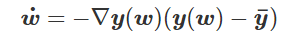
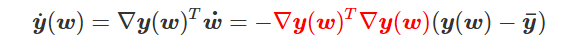
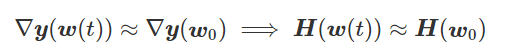
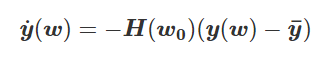
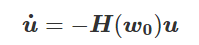
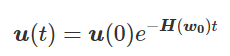
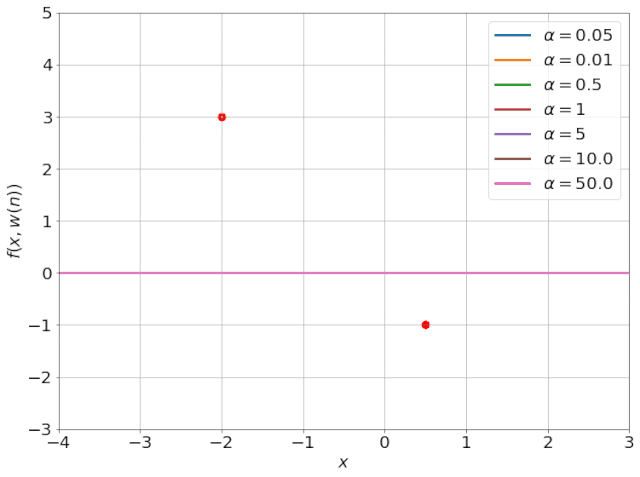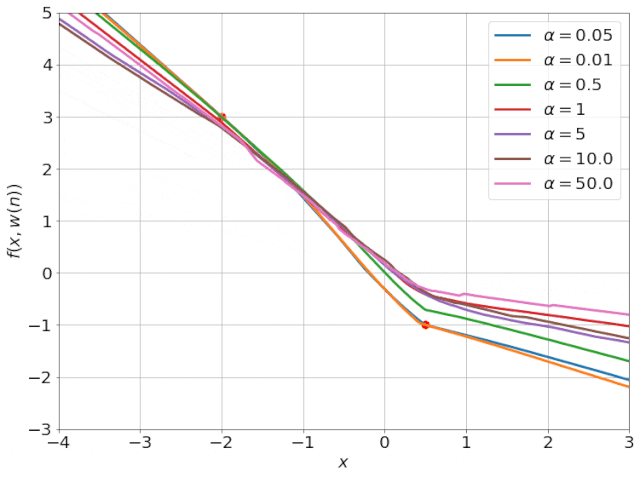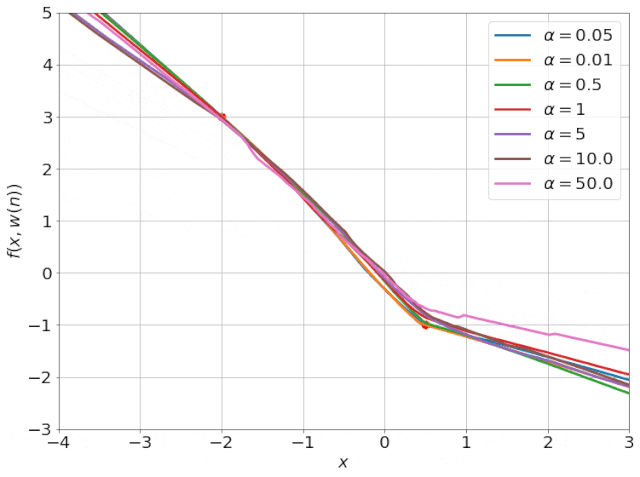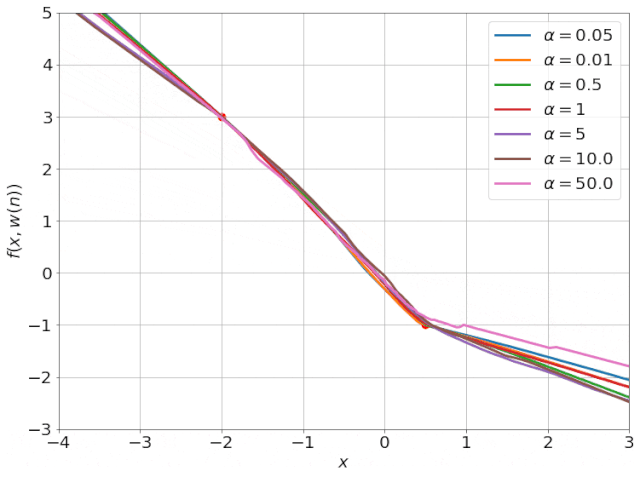
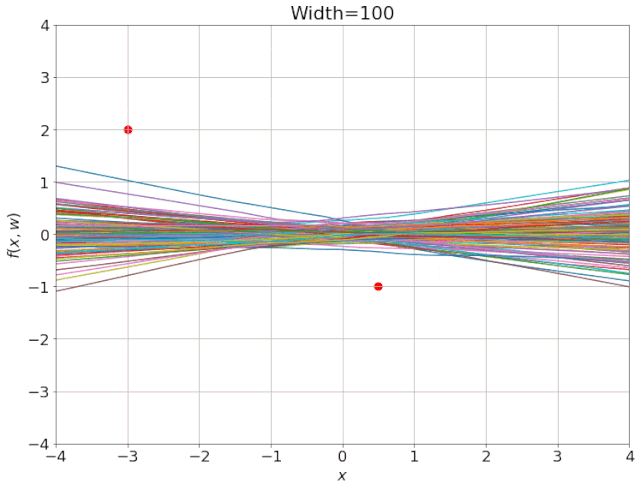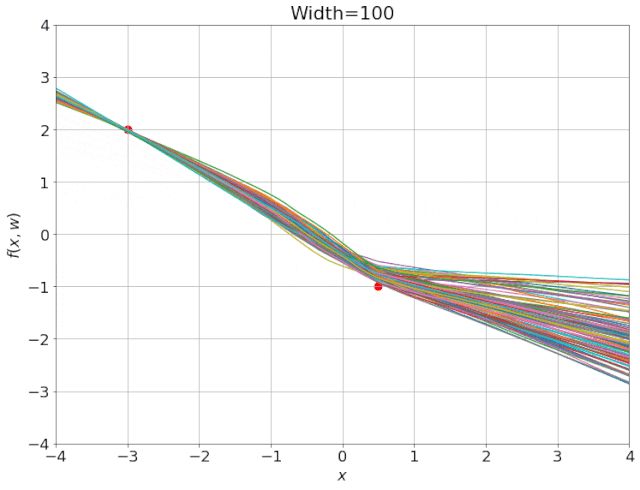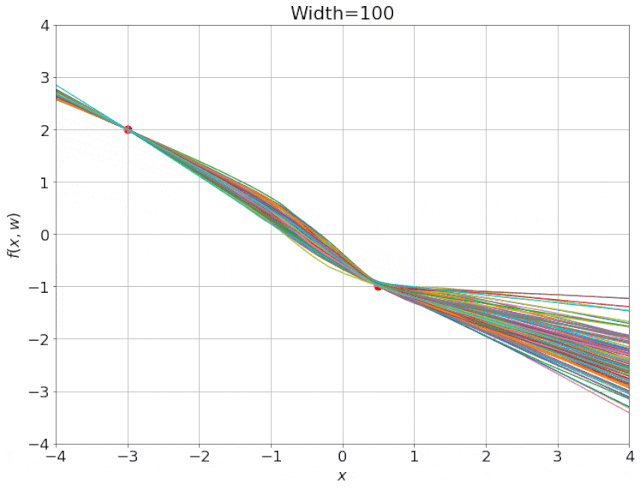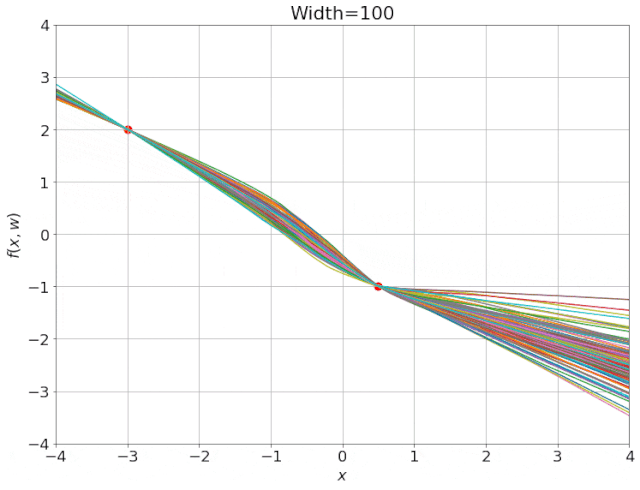
我特意将椭圆的中心设置为目标数据 y¯,以使其轨迹接近中心。这样,你可以看到椭圆短轴(较大特征值)对应的组件比长轴(较小特征值)收敛得更快;
α 的较小值也会收敛至 0 训练损失,不过我们对此没有任何理论依据。我们的证明仅对 α 足够大能使椭圆在训练过程中保持不变时有效(核机制);
最小的 α 值收敛得很快,快到动图中几乎看不出来;
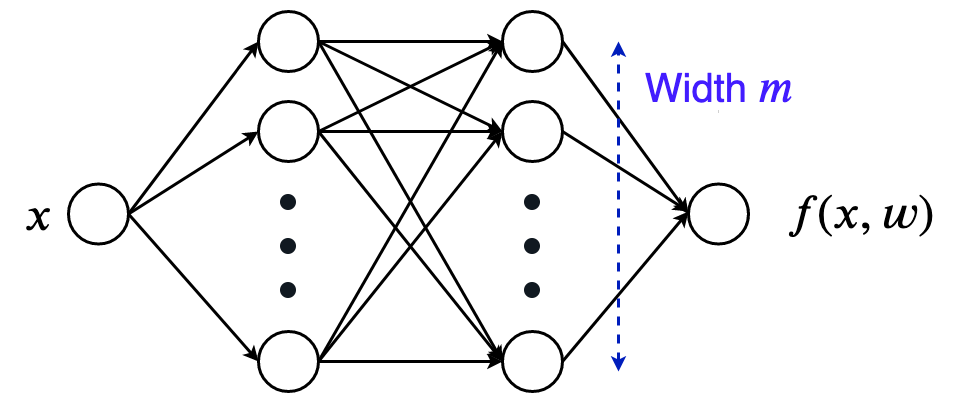
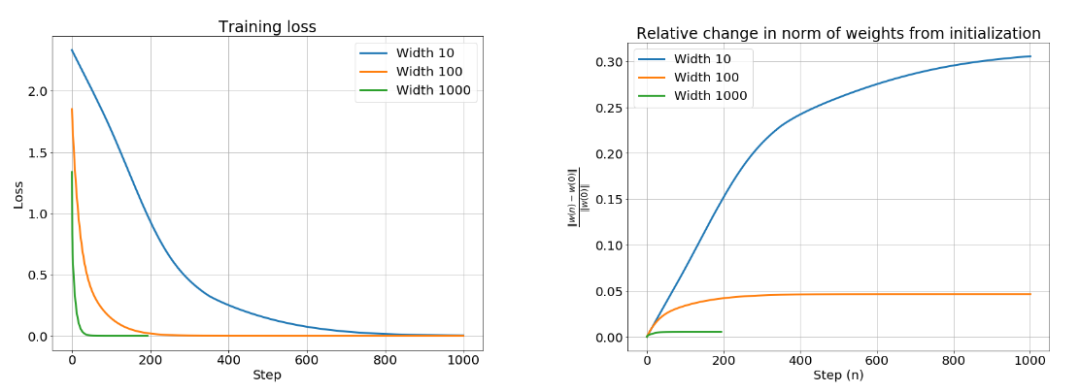
我在模型运行中使用的是两层网络,其宽度为 100。我还在初始化处减去了其副本,使网络输出为 0(正因如此,所有轨迹均从原点开始)。尽管我们无法看到该网络有 10000 个权重时,权重在训练过程中的变化,但是我们可以看到网络输出,如上图所示。
登录查看更多
相关内容
专知会员服务
14+阅读 · 2020年1月1日
Arxiv
5+阅读 · 2018年5月23日
Arxiv
5+阅读 · 2018年4月3日



相关VIP内容
专知会员服务
14+阅读 · 2020年1月1日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年5月23日
Arxiv
5+阅读 · 2018年4月3日