一文入门Python数据分析库Pandas丨数据工匠简报
点击上方
Datartisan数据工匠
可以订阅哦!
1
一文入门Python数据分析库Pandas

首先要给那些不熟悉 Pandas 的人简单介绍一下,Pandas 是 Python 生态系统中最流行的数据分析库。它能够完成许多任务,包括:
读/写不同格式的数据
选择数据的子集
跨行/列计算
寻找并填写缺失的数据
在数据的独立组中应用操作
重塑数据成不同格式
合并多个数据集
先进的时序功能
通过 matplotlib 和 seaborn 进行可视化操作
尽管 Pandas 功能强大,但它并不为整个数据科学流程提供完整功能。Pandas 通常是被用在数据采集和存储以及数据建模和预测中间的工具,作用是数据挖掘和清理。
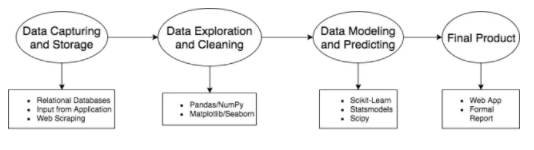
对于典型的数据科学家而言,Pandas 在数据管道传输过程中扮演着非常重要的角色。其中一个量化指标是通过社区讨论频率趋势(Stack Overflow trends app (https://insights.stackoverflow.com/trends))。
扫码阅读原文

page
2
2017年10月阿曼AppStore市场应用飙升榜盘点
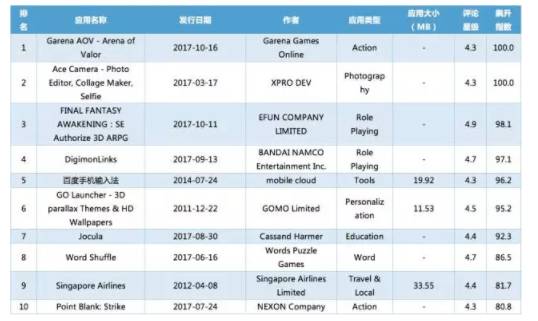
2017年10月,阿曼GooglePlay市场出现了哪些引人注目的飙升应用?数鸥移动出海为您盘点。
一、Apple Store

一款购买Apple产品的移动端软件,可以在手机上进行iPhone,iPad等Apple产品和配件的购买,找出哪些配件与自己的设备兼容,并查询物流。
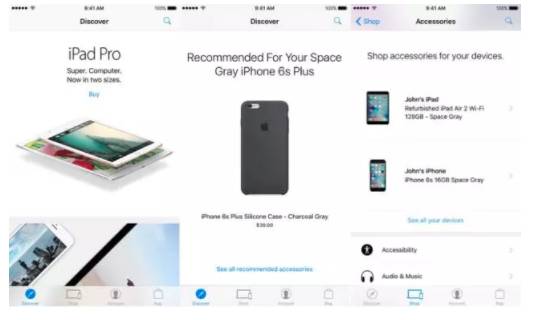
飙升战绩:
2017年10月01日-2017年10月28日:由榜单100名开外上升至第5名
扫码阅读原文

page
3
代码优化指南:人生苦短,我用Python
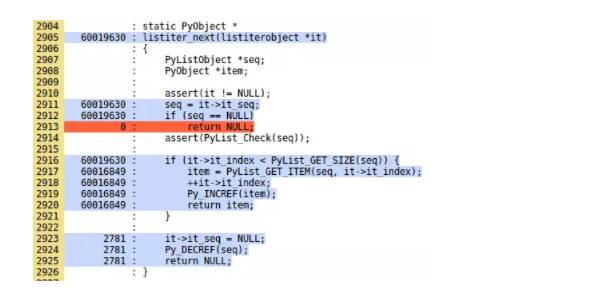
前段时间,Python Files 博客发布了几篇主题为「Hunting Performance in Python Code」的系列文章,对提升 Python 代码的性能的方法进行了介绍。在其中的每一篇文章中,作者都会介绍几种可用于 Python 代码的工具和分析器,以及它们可以如何帮助你更好地在前端(Python 脚本)和/或后端(Python 解释器)中找到瓶颈。机器之心对这个系列文章进行了整理编辑,将其融合成了这一篇深度长文。本文的相关代码都已经发布在 GitHub 上。
代码地址:https://github.com/apatrascu/hunting-python-performance
第一部分请查看从环境设置到内存分析。以下是 Python 代码优化的第二部分,主要从 Python 脚本与 Python 解释器两个方面阐述。在这一部分中我们首先会关注如何追踪 Python 脚本的 CPU 使用情况,并重点讨论 cProfile、line_profiler、pprofile 和 vprof。而后一部分重点介绍了一些可用于在运行 Python 脚本时对解释器进行性能分析的工具和方法,主要讨论了 CPython 和 PyPy 等。
扫码阅读原文


更多课程和文章尽在微信号
「datartisan数据工匠」




