BAT机器学习面试题1000题(366~370题)

点击上方蓝字关注


BAT机器学习面试题1000题(366~370题)
366题
简单介绍下logistics回归?
点击下方空白区域查看答案
▼
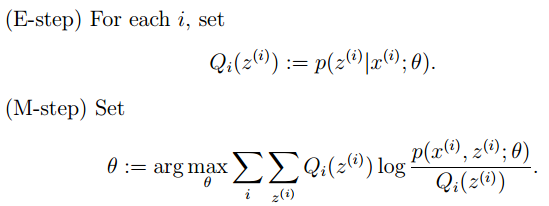
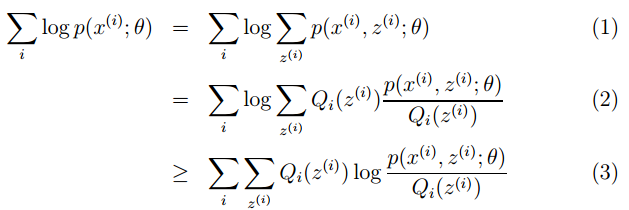
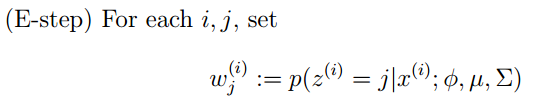
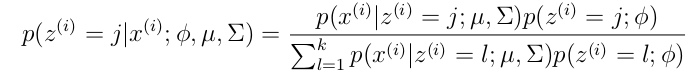

367题
KNN中的K如何选取的?
点击下方空白区域查看答案
▼
368题
防止过拟合的方法
点击下方空白区域查看答案
▼
369题
什么最小二乘法?
点击下方空白区域查看答案
▼
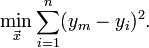
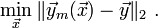
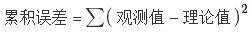
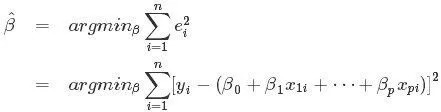
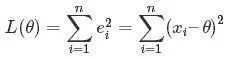
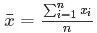
370题
简单说说贝叶斯定理
点击下方空白区域查看答案
▼
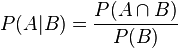
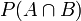
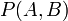
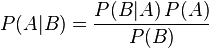
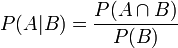
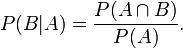
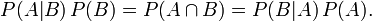
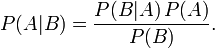
题目来源:七月在线官网(https://www.julyedu.com/)——面试题库——面试大题——机器学习
分享一哈
亲耐滴小伙伴们,8月中下旬喽,每年的三四月份、和八九月份,都是各大企业狂招人的季节,也是跳槽涨薪的最佳时节喔,想跳槽转行的亲们抓好机遇啦。
之前第一期,不到一个月,30人的名额很快招满,毕业之后有的不到半个月,便拿到30万offer,甚至更多。
现在为了更好的冲刺秋季转行转岗转型的黄金季节,拿下dream offer,我们推出了【AI就业班 二期】,此期特在一期基础上,进一步改进,推出BAT大咖一对一定向辅导+包就业,更好的课程体系和服务。
报名即学,报名截止到8月底,还有一周时间喽,想转行跳槽的小伙伴们抓紧时间呢~~
(ps:点击下方“阅读原文”可在线报名,详细可添加客服咨询:julyedukefu_02)


更多资讯
请戳一戳


往期推荐
想做Python开发,这14种常用Python模块,你必须知道!

点击“阅读原文”,可在线报名
登录查看更多
相关内容

Arxiv
11+阅读 · 2019年6月13日


相关VIP内容
相关资讯
相关论文
Arxiv
11+阅读 · 2019年6月13日