ICLR 2020 | 快速神经网络自适应技术

本文介绍的是ICLR 2020的论文《Fast Neural Network Adaptation via Parameter Remapping and Architecture Search》,文章作者是华中科技大学方杰民。
文 | 方杰民

论文链接:https://openreview.net/pdf?id=rklTmyBKPH
简介
神经网络在计算机视觉的各个领域都取得了巨大的成功。通常神经网络模型的设计都需要依托于图像分类的任务,比如在ImageNet分类数据集上设计神经网络,再直接把分类任务上设计的网络模型应用到其他任务(比如分割、检测等)的backbone上。然而由于任务的特性不同,所需要的backbone网络设计也不尽相同。人工神经网络结构的设计往往需要经验丰富的工程师花费比较多的精力来进行调整,效率不高。
最近NAS(neural architecture search)方法的兴起极大的促进了神经网络的自动化设计,不少工作尝试在分割、检测的任务上展开网络结构搜索,但是backbone的预训练(pre-training)是一个消耗很大、又不可避免的操作。虽然最近的一些工作证实预训练对于最终精度而言不一定是必须的,但是从头训练需要花费大量的迭代次数来达到同等的精度。
对于NAS算法而言,预训练的问题将更难解决,比如针对backbone的搜索,搜索空间中包含的所有可能的网络可能都面临预训练问题。One-shot/Differentiable的NAS方法虽然能将所有可能的网络集成为一个超网络(super network),但是超网络和最终搜出来的网络依然面临预训练的问题,其对应的计算代价都还是很大的。
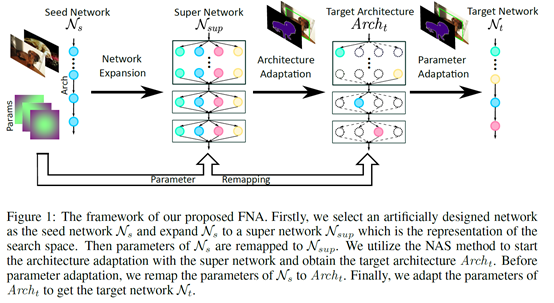
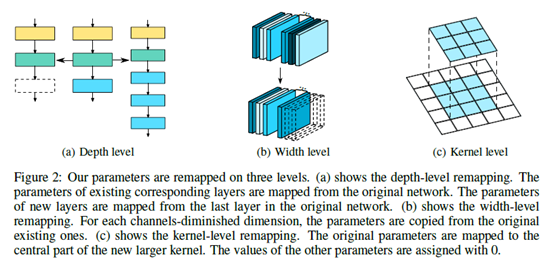
方法
实验
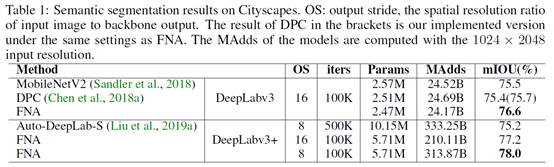
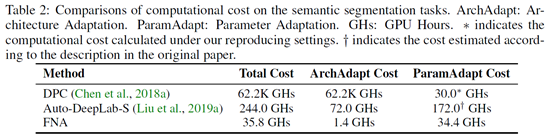
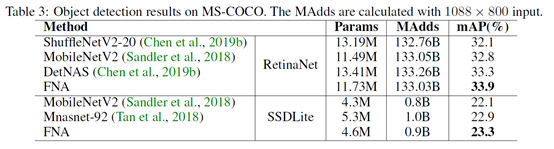

本文选取MobileNetV2(MBV2)作为种子网络,MBV2是一个性能卓越的轻量网络模型,其被广泛用于设计NAS方法的搜索空间。本文在语义分割Cityscapes和目标检测COCO任务上都进行了实验,相比于种子网络MBV2,FNA能以相同或者更小的MAdds取得更高的性能;相比于分割和检测的其他NAS算法,FNA总的计算代价要小很多,最终模型在目标任务上的性能也更强。


火爆的图机器学习,ICLR 2020上有哪些研究趋势?
1、直播
回放 | 华为诺亚方舟ICLR满分论文:基于强化学习的因果发现
03. Spotlight | 组合泛化能力太差?用深度学习融合组合求解器试试
04. Spotlight | 加速NAS,仅用0.1秒完成搜索
05. Spotlight | 华盛顿大学:图像分类中对可实现攻击的防御(视频解读)
4、Poster
01. Poster | 华为诺亚:巧妙思想,NAS与「对抗」结合,速率提高11倍




