语义分割领域开山之作:Google提出用神经网络搜索实现语义分割

来源: AI科技评论
1. Introduction
在 arxiv 浏览论文的时候,单独看文章名不知道属于 CV 哪个领域,怀着对一作 Liang-Chieh 敬畏的心,在摘要中扫描到 PASCAL VOC 2012 (semantic image segmentation),浏览全文才明白,Google 又发大招。
Google 在 Cloud AutoML 不断发力,相比较而言之前的工作只是在图像分类领域精耕细作,如今在图像分割开疆扩土,在 arxiv 提交第一篇基于 NAS(Neural network architecture)的语义分割模型[1](DPC,dense prediction cell)已经被 NIPS2018 接收,并且在 Cityscapes,PASCAL-Person-Part,PASCAL VOC 2012 取得 state-of-art 的性能(mIOU 超过 DeepLabv3+)和更高的计算效率(模型参数少,计算量减少)。
Google 俨然已是图像语义分割领域的高产霸主,Liang-Chieh 从 Deeplabv1- Deeplabv3+ 持续发力,还是 MobileNetV2 共同作者,如今在 NAS 领域开发处女地:基于 NAS 的语义分割模型,性能超过之前的基于 MobileNetV2 的 Network Backbone。
2. Motivation
深度学习技术已经成为当前人工智能领域的一个研究热点,其在图像识别、语音识别、自然语言处理等领域展现出了巨大的优势,并且仍在继续发展变化。自 Google 提出 Cloud AutoML,NAS(Neural Architecture Search,神经网络架构搜索)也取得重大进展,但更多的是在图像分类和自然语言处理方面的应用。在过去的一年中,元学习(meta-learning)在大规模图像分类问题上,性能已经实现超越人类手工设计的神经网架构。
基于 NAS 的图像分类迁移到高分辨率的图像处理(语义分割、目标识别、实例分割)有很大的挑战:(1)神经网络的搜索空间和基本运算单元有本质不同。(2)架构搜索必须固有地在高分辨率图像上运行,因此不能实现从低分辨率图像训练模型迁移到高分辨率图像。
论文首次尝试将元学习应用于密集图像预测(本人理解就是像素级图像分割)。语义分割领域一般使用 encoder-decoder 模型,空间金字塔结构,空洞卷积等,目标是实现构建高分辨率图像的多尺度特征,密集预测像素级标签。论文利用这些技术构建搜索空间,同时构建计算量少、处理简单的代理任务,该任务可为高分辨率图像提供多尺度架构的预测信息。
论文提出的模型在 Cityscapes dataset 验证测试,取得 82.7% mIOU,超过人类手工设计模型 0.7%。在 person-part segmentation 和 VOC 2012 也取得 state-of-art 性能。
3. Architecture
深度学习在感知任务中取得的成功主要归功于其特征工程过程自动化:分层特征提取器是以端到端的形式从数据中学习,而不是手工设计。然而,伴随这一成功而来的是对架构工程日益增长的需求,越来越多的复杂神经架构是由手工设计的。算法工程师一般自我调侃“炼丹师”,就是因为超参数的设计选取存在太多偶然性,是一门玄学,没有明显的规律性。
Neural Architecture Search (NAS) 是一种给定模型结构搜索空间的搜索算法,代表机器学习的未来方向。NAS 是 AutoML 的子领域,在超参数优化和元学习等领域高度重叠。NAS 根据维度可分为三类:搜索空间、搜索策略和性能评估策略。
3.1 搜索空间
搜索空间原则上定义了网络架构。在图像分类任务中分为三类:链式架构空间、多分支架构空间、Cell/block 构建的搜索空间。
论文提出了基于 Dense Prediction Cell (DPC)构建的递归搜索空间,对多尺度上下文信息编码,实现语义分割任务。
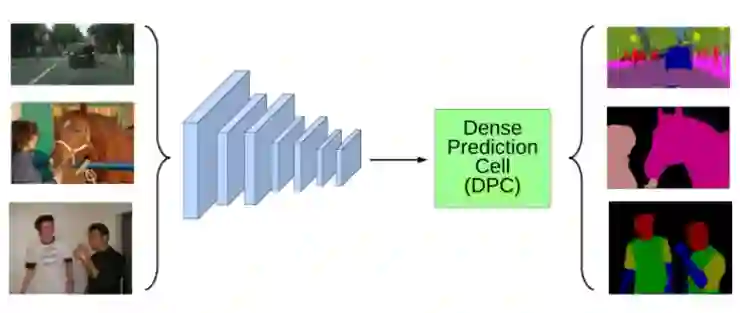
图 1 DPC 模型架构
DPC 由有向无环图(directed acyclic graph ,DAG)表示,每个 Cell 包含 B 个分支,每个分支映射输入到输出的张量。每个 Cell 的操作类型包括 1x1 卷积,不同比率的 3x3 空洞卷积,不同尺寸的均值空间金字塔池化。
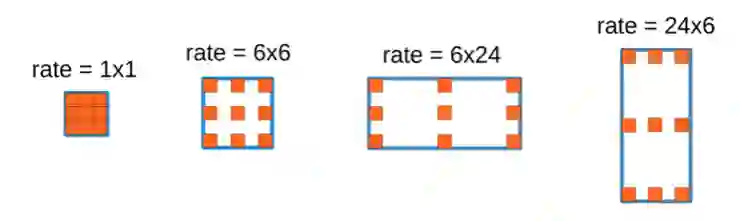
图 2 3x3 空洞卷积比率类型
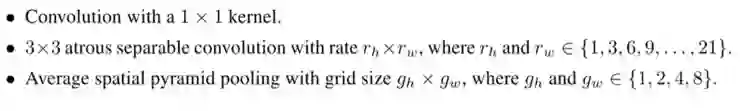
根据论文提供的操作方式,3x3 空洞卷积有 8x8,均值空间金字塔池化有 4x4 操作,即操作函数共有 1+8*8+4*4=81 种类型,对于 B 分支的 Cell,搜索空间为 B!*81B,当 B=5,搜索空间为 5!*815≈4.2*1011。
3.2 搜索策略
搜索策略定义了使用怎样的算法可以快速、准确找到最优的网络结构参数配置。
机器学习模型超参数调优一般认为是一个黑盒优化问题,所谓黑盒问题就是我们在调优的过程中只看到模型的输入和输出,不能获取模型训练过程的梯度信息,也不能假设模型超参数和最终指标符合凸优化条件。
自动调参算法一般有 Grid search(网格搜索)、Random search(随机搜索),还有 Genetic algorithm(遗传算法)、Paticle Swarm Optimization(粒子群优化)、Bayesian Optimization(贝叶斯优化)、TPE、SMAC 等方式。
论文采用随机搜索的方式,基于 Google Vizier 实现[3]。Github 上有开源实现的 advisor[4](非Google 开源,第三方),包括随机搜索,网格搜索,贝叶斯优化等调参算法实现,感兴趣可以关注一下。
3.3 性能评估策略
因为深度学习模型的效果非常依赖于训练数据的规模,通常意义上的训练集、测试集和验证集规模实现验证模型的性能会非常耗时,例如 DPC 在 Cityscapes dataset 上训练,使用 1 个 P100 GPU 训练候选架构(90 迭代次数)需要一周以上时间,所以需要一些策略去做近似的评估,同时满足快速训练和可以预测大规模训练集的性能。
图像分类任务中通常在低分辨率图像中训练模型,再迁移到高分辨率图像模型中。但是图像分割需要多尺度上下文信息。论文提出设计代理数据集:(1)采用较小的骨干网络(network backbone),(2)缓存主干网络在训练集生成的特征图,并在其基础上构建单个 DPC。(个人理解应该是权值共享的方式)。(3)训练候选架构时提前终止(实验中占用 30K 迭代训练每个候选架构)。
论文采用以上策略,在 GPU 上训练只运行 90 分钟,相比一周的训练时间大幅度缩短。
在架构搜索后,论文对候选架构进行 reranking experiment,精准测量每个架构在大规模数据集的性能。reranking experiment 中,主干网络经过微调和训练完全收敛,生成的最优模型作为最佳 DPC 架构。
4. Experiment&Result
论文在场景理解(Cityscapes),人体分割(PASCAL- Person-Part),语义分割(PASCAL VOC 2012)对比展示 DPC 模型的性能。主干网络在 COCO 数据集预训练,训练学习率采用多项式学习率,初始化为 0.01,裁剪图像,fine-tuned BN 参数(batch size=8,16)。评测和架构搜索中,图像尺寸采用单一类型。对比其他 state-of-the-art 系统时,通过对给定图像的多个缩放进行平均来执行评估。
论文使用提出的 DPC 架构搜索空间,在 Cityscapes 部署生成的代理任务,370 个 GPU 在一周时间中评估 28K 个 DPC 架构。论文采用 MobileNet-v2 主干网络对整个模型进行微调,选择前 50 个架构进行重新排序。
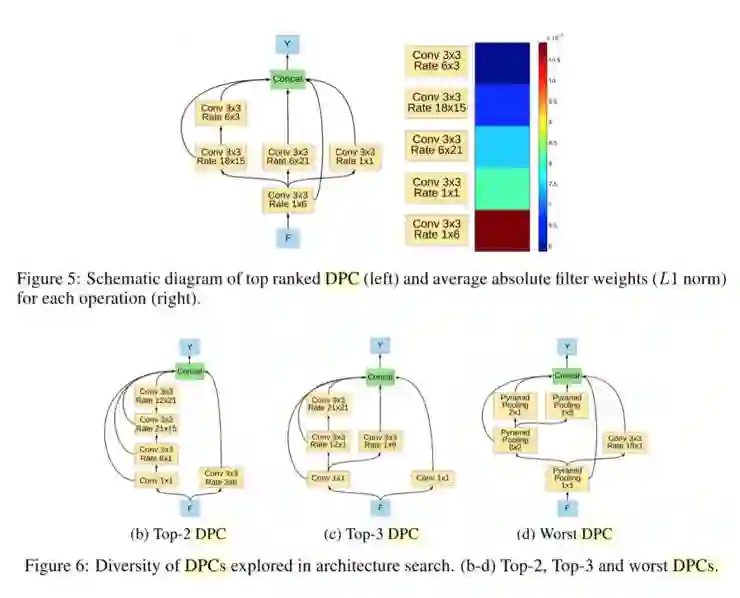
论文中图 5 、图 6 展示了顶级 DPC 架构的示意图。在图 5b 每个分支(通过 1*1 卷积)的 L1 正则化权重,我们观察到具有 3×3 卷积(速率= 1×6)的分支贡献最大,而具有大速率(即较长背景)的分支贡献较少。换句话说,来自更接近(即最终空间尺度)的图像特征的信息对网络的最终输出贡献更多。相反,性能最差的 DPC(图 6c)不保留精细空间信息,因为它在全局图像池操作之后级联四个分支。
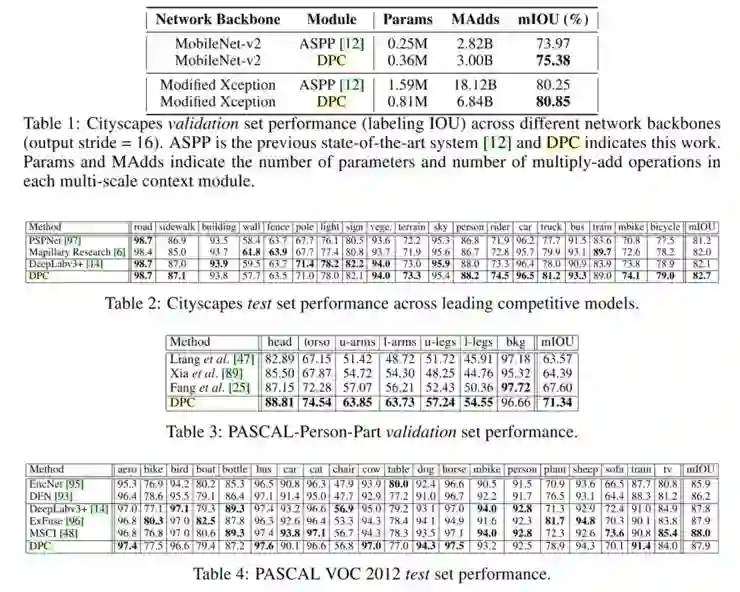
论文实验中,表 1,表 2,表 3分别对应在场景理解(Cityscapes),人体分割(PASCAL- Person-Part),语义分割(PASCAL VOC 2012)的模型性能,DPC 在各个数据集取得 state-of-art 性能。
5. Discussion
1、论文提出的 DPC 架构基于 Cell 构建的搜索空间,每个 Cell 有语义分割采用经典的空洞卷积,空间金字塔池化,1x1 卷积,在 mIOU 实现 state-of-art 水准。
2、论文的搜索策略采用随机搜索,评价指标也只有 mIOU,相比 Google 另一篇论文 MnasNet,在准确率和推断时间上均有显著提高。
3、论文摘要选择只需要一半的参数和一半的计算效率,但是只在论文的表 1 即 Cityscapes 数据集对比了 MobileNet-v2 和 modified Xception 的实现方式,其他数据集没有体现计算效率的优越性。论文架构搜索和训练时的目标函数没有计算效率的体现。
Additionally, the resulting architecture is more computationally efficient, requiring half the parameters and half the computational cost as previous state of the art systems
4、作为 Google 在语义分割领域的开山之作,目测会有一大批基于 NAS 实现的目标检测、实例分割的优秀论文,NAS 应用到工业界产品指日可待。
5、语义分割是一种广义上的图像分类(对图像的每个像素进行分类),和图像分类在搜索空间有很多相似之处,但是目标检测需要 Region Proposal,Bounding-Box Regression 等,增加搜索空间的难度,NAS 在目标检测领域可能还需要很长一段路要走。

未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”





