ACL‘22杰出论文:Prompt范式有bug!

文 | python
GPT-3等超大模型的兴起,也带来了 in-context learning (语境学习)的新范式。在语境学习中,模型并不使用梯度下降,根据监督样本调整参数;而是将监督样本的输入输出接起来作为prompt(提示词),引导模型根据测试集的输入生成预测结果。该方法的表现可以大幅超越零监督学习,并为少样本监督学习提供了新的思路。
之前监督学习中的研究经验告诉我们,训练集随机打乱通常对模型表现不会有明显影响。然而,这个结论在 in-context learning 下并不适用。作者发现,prompt中示例的顺序,对 in-context learning 的表现有很大影响,可以让模型表现在state-of-the-art到随机之间波动。这一规律,并不随着模型大小与样本量的多寡而变化。并且,较好的prompt样本的顺序,并没有规律可循。
那我们就无法选出最好的prompt顺序了么?作者表示,一方面,我们可以利用验证集来对prompt的顺序做挑选。然而,这违背了 in-context learning 的少样本学习的初衷。另一方面,作者发现大多数使模型失效的prompt顺序,会让模型预测的标签分布与真实分布有较大偏差。因此,作者根据少量样本,基于预训练语言模型,生成无标签数据。以自动生成的无标注数据作为验证集,以标签分布的熵值作为验证指标,挑选最优prompt顺序。作者提出的方法在11个文本分类上,取得了13%的相对提升。
本文为ACL 2022 outstanding paper, 作者主要来自UCL。
论文题目:
Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
论文链接:
https://aclanthology.org/2022.acl-long.556
背景
大规模预训练语言模型的无监督预测:给定训练好的模型,输入测试数据的输入(x),直接通过语言模型预测输出(P(y|x))。如下图所示,其中mannual部分引入少量人工设计。蓝色是需要预测的标签部分。

in-context learning,类似于上述的无监督预测,但在输入测试样例前输入少量标注数据。同样不需要参数调整,直接预测。相当于在无监督预测的基础上,引入前缀,如下图所示。
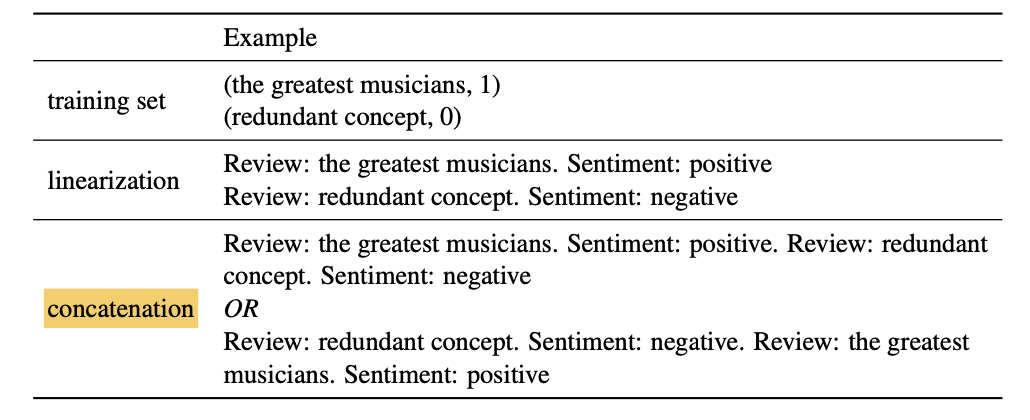
而本文主要探究的,就是in-context learning中,引入的前缀里,标注数据的顺序(即上图的concatenation部分)对模型表现的影响。
prompt顺序很重要
下图展示了在SST-2(左)和subj(右)任务上,不同规模的GPT-2、GPT-3模型(横坐标,0.1B~175B)在不同的的prompt顺序下的表现。作者随机选取了4个监督样本,全排列的话,一共有4!=24种配列方式。每列绘制出了该模型在该任务下,24种prompt顺序的表现均值和error bar。可以看到,在SST-2中,2.7B的模型表现准确率可以在50%~85%的区间内波动。50%只是随机瞎蒙的准确率,85%已经接近监督学习下的最好成绩了。因此,prompt顺序十分重要。
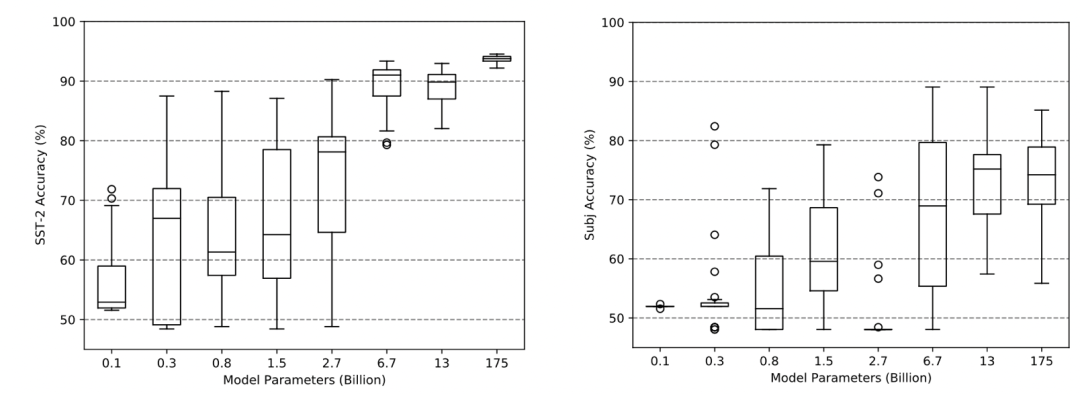
更大模型难以完全避免模型表现随prompt顺序变化的波动。 SST-2任务(上图左)中,貌似随着模型增大,波动变小了很多。但在subj任务中(上图右),即使是175B的GPT-3模型,表现依然会随着prompt的顺序有很大的波动。
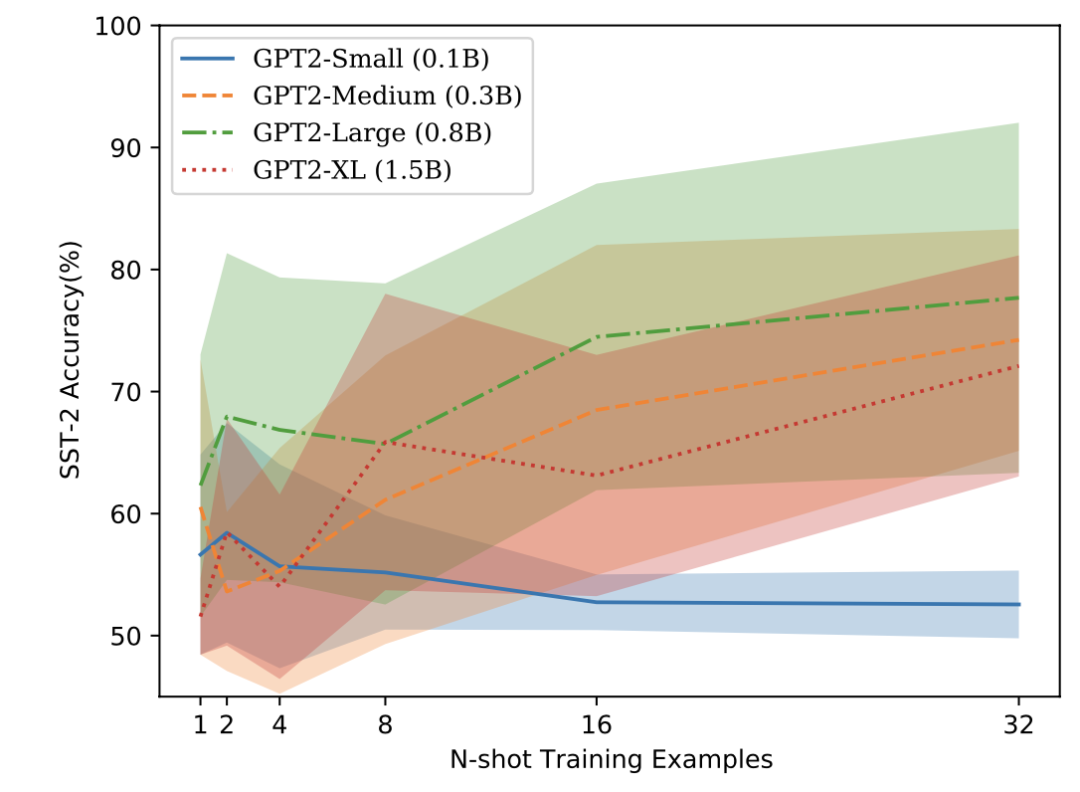
更多的展示样本也无法缓解模型表现随prompt顺序变化的波动。 下图展示了4种规模的GPT-2模型,在1~32个展示样本时的波动范围。可以看到,随着展示样本量的增加,模型表现普遍有所提升,但波动范围并没有明显缩小。
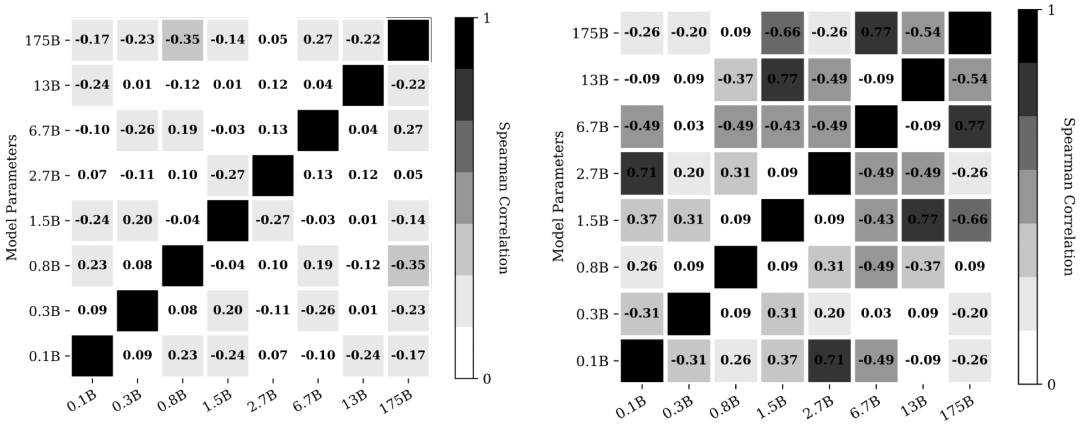
优质的展示样本的顺序,也没有什么明显的规律。 如果优质展示样本的顺序存在一定规律,那应该具有一定的可迁移性,即在不同模型下,性能都比较好。然而,这一规律并不存在。不同模型下优质的展示样本之间具有很大差异。下图显示的是不同展示样本顺序在不同模型的表现之间的斯皮尔曼秩相关系数。左图针对展示样本顺序(4!=24个),右图针对展示样本标签顺序(由于2正2负,一共有6种)。可以看出,不管是样本顺序,还是标签顺序,都不具备跨模型迁移能力。因此,优质的展示样本的顺序,也没有什么明显的规律。
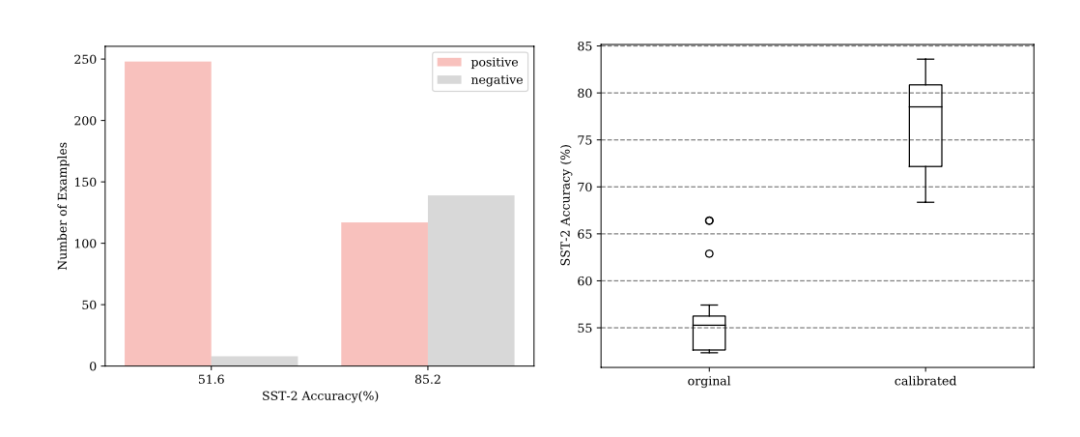
但展示样本顺序和模型表现之间的关联就是纯随机的了么?并不是。作者发现,那些使模型表现很差的展示样本顺序,往往会让模型的预测出现很大偏差 ,比如二分类中,把所有样本都预测成其中某一个类别。如下图左所示,准确率51.6%和准确率85.2%的展示顺序,预测结果分布具有明显差异。
不过,简单地对预测结果的判定阈值做校准,虽然可以部分提升模型表现,但依然无法彻底解决模型表现随展示样本顺序之间的随机性问题 。如下图右所示,通过对表现较差的展示顺序的预测结果分布调整,平均准确率有所提升,但标准差反而更大了。
优化筛选Prompt顺序
那我们就拿prompt的顺序没有办法了么?作者表示,一方面,我们可以利用验证集对prompt顺序做挑选。然而,这违背了 in-context learning 的少样本学习的初衷。另一方面,我们可以基于“大多数使模型失效的prompt的顺序,会让模型预测的标签分布与真实分布有较大偏差”这一观察,根据少量样本,生成无标签数据。以自动生成的无标注数据作为验证集,以标签分布的熵值作为验证指标,挑选最优prompt顺序。
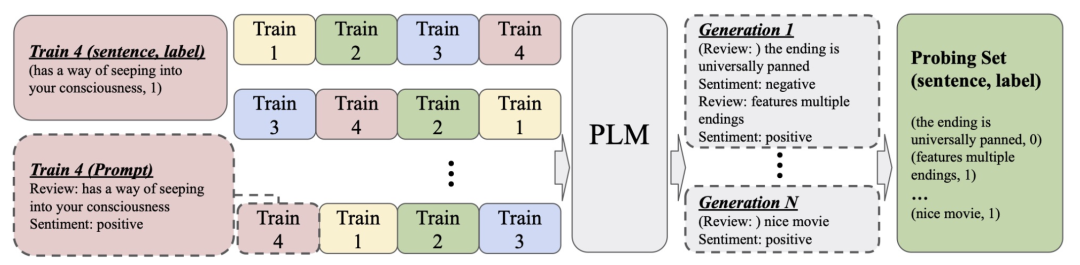
第一步是生成用来验证的无标注数据集 。作者简单地以每个prompt的顺序作为前缀,输入到预训练语言模型中,让模型解码出一系列的同分布数据。如下图所示。之所以使用预训练模型生成伪数据集,而非使用真实数据作为验证集,主要是出于少样本学习的考虑。
生成验证用数据集后,下一步就是确定评价指标来评估prompt的展示顺序的优劣 。作者考虑到生成的数据的标签并不准确,所以不使用通常有监督训练的验证集应用方式,而是设计了一种基于熵的无监督评价指标。主要基于大多数使模型失效的prompt的顺序,会让模型预测的标签分布相对较为极端,从而熵值较低的直觉。
作者设计了两种筛选指标,一种指标为全局熵指标(GlobalE)。即给定某种展示样本的顺序后,在生成数据上做预测,统计频率,作为每个类别的预测概率 。而预测概率的熵值越大,认为该展示样本质量越高。
另一种指标为局部熵指标(LocalE)。该方法,利用对数据条目 的预测概率 ,计算平均熵值。这一熵值越高,认为该展示样本质量越高。
实验结果
实验结果如下图所示。具体的实验细节在此不再赘述。下表中的Oracle是最优的展示样本顺序下的模型表现。
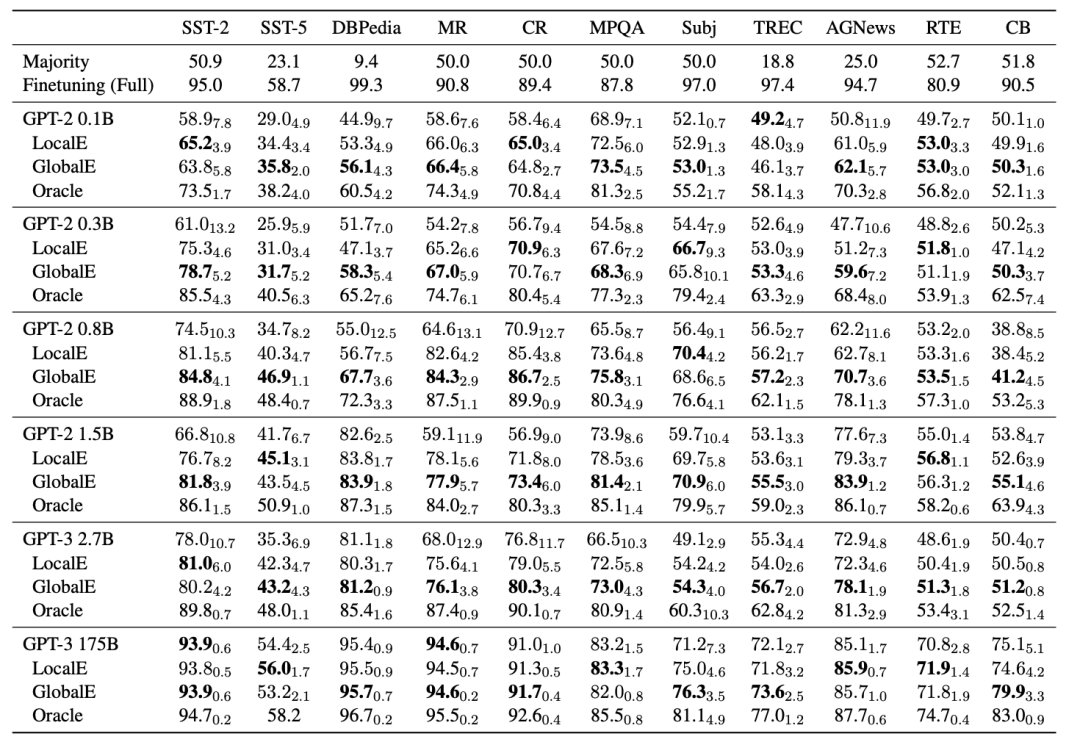
相对于不挑选prompt展示顺序的方法而言,使用GlobalE和LocalE的方法平均取得了13%与9.6%的提升。这表明,基于熵和无标注数据生成的选取方法是有效的。
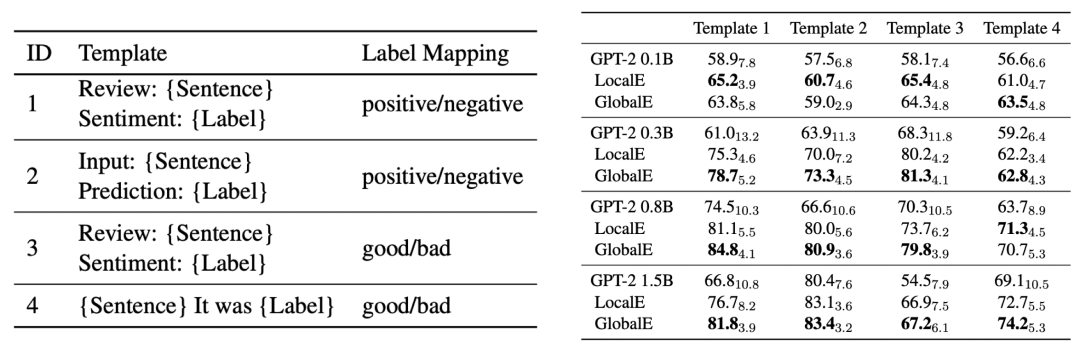
在不同的prompt模板下,本文方法是鲁棒的。 换用4种不同的线性化输入样本的模板(下图左),模型表现的提升是稳定且一致的(下图右)。
结语
说实话,最开始看到小轶大人给我这个素材时我是不太愿意写的。主要是看到素材说明里“发现不同的顺序会导致结果不同”,“提出了一种生成更有效prompt的方法,在11个任务上相对提升13%”,感觉只是一篇※上雕花的工作。毕竟输入样本的顺序理论上并没有价值,这篇论文的提升可能只是发现了目前还不完善的一个方法(in context learning)的一个巧合点(展示顺序),并且产生了没有意义的提升。
不过读完后,感觉这篇论文还是有很多可取之处的,不愧是一篇outstanding paper。一方面,作者通过非常完善的实验,揭露出这种随顺序变化的不稳定性普遍存在于多种任务,不随模型规模与标注样本规模而变动。并且,波动范围极大,且不存在规律性。当然,如果只是做到这,这一只算是一份negative report,只是一篇还可以的短文。作者又从变化中寻找不变,发现了不同prompt顺序导致的预测结果标签分布上的规律,据此提出了基于熵的prompt筛选方法,并验证了效果。这就使得这篇工作变得有意思了起来。
这篇文章虽然发现现象并给出解决方案,但却缺乏这一现象背后的语言学理论/直觉上的分析。感觉作为一篇ACL(而非ICLR/IJCAI)的论文而言,是略有些不足的。究竟这些好的顺序,在语言学上有没有共性?这些好的顺序是如何产生的?是否会和预训练语料中的一些语言分布产生关联?为什么有些验证集数据对prompt样本顺序敏感?哪些数据敏感,哪些数据不敏感?敏感与不敏感的数据是否具有某种语言学特点?
除此之外,这篇文章还有一些问题可以继续深究。比如,这种不稳定性只在GPT系列的自回归语言模型中出现么?对于T5、BART一类的语言模型,是否依然存在这种问题?主实验测试集只采用256个样本是否会过少,从而增加不稳定性?如果使用大规模的测试集会观察到什么变化么?前面在SST-2上做的实验,放到所有11个任务上,结果是一致的么?作者提到,基于熵的方法对句对匹配任务的提升相对较低。那对于GPT-3试过的那些非分类任务,比如完形填空之类的,本文发现的规律是否还存在?不探究这些问题,也不会影响到这篇论文的完整性。但这些问题的答案,的确很令人好奇。
最后,还想吐槽一下这篇论文的写作格式。比如camera ready限制的是9页,这篇文章只放了8页,但表1字号很小,令人看着困难。以及像图6里配的字也太小了,看着费劲。后面附录的排版也逼死强迫症。当然,这些有点吹毛求疵了,但对一篇outstanding paper吹毛求疵一点大概也无可厚非吧~同学们如果对于一些写作格式上的建议感兴趣,可以参见本人之前的文章:吐血整理:论文写作中注意这些细节,能显著提升成稿质量,或其后续在github上整理的版本:
https://github.com/MLNLP-World/Paper-Writing-Tips
萌屋作者:python
北大毕业的NLP博士。日常写点论文,码点知乎,刷点leetcode。主要关注问答、对话、信息抽取、预训练、智能法律等方向。力扣国服第一python选手(经常掉下来)。知乎 ID 是 Erutan Lai, leetcode/力扣 ID 是 pku_erutan,欢迎没事常来逛逛。
作品推荐
 萌屋作者:python
萌屋作者:python
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
 后台回复关键词【入群】
后台回复关键词【入群】