能跟你聊DOTA的神经对话模型:Meena&DialoGPT
提到对话机器人或者聊天机器人,国内的朋友可能先想到的是微软小冰或者苹果Siri。这两个机器人由于需要完成一些功能性的任务,都采用了模块化设计,虽然神经网络在其中起到了重要作用,但输出结果并不是从输入语句“端到端”产生的。而且用过的朋友都知道,他们的聊天能力并不是很令人满意。
今天介绍的神经对话模型则是一步到位,将对话历史作为输入,让模型直接生成下一轮的回复。学术一点说,神经对话模型本质上是在解决文本生成的问题。相比于很多聊天机器人(包括我们的晴天一号)目前使用的语料库+检索算法的架构,生成式(包括改写等等)算法能给对话带来更多的可能性和趣味性。最近,得益于大规模预训练语言模型,文本生成任务得到了长足的发展。本文的主角就代表了目前神经对话模型的最高水平,分别是19年十一月由微软发布的DialoGPT和20年一月谷歌发布的Meena。
在开始正文之前,先展示一段机器人生成的对话,让大家对技术现状有个直观感受。

模型
两篇论文都没有在模型方面有什么重大的创新,他们使用的都是如下图所示基于Transformer的seq2seq模型。这里大致介绍一下所谓seq2seq模型的工作原理。每生成一个单词的过程如下:将对话的历史信息输入进编码器(左下角inputs),模型已经生成的当前轮结果输入解码器(右下角outputs,没错,outputs是也用来input的~),然后模型将会综合两者信息输出它预测的下一个词(上方output)。而生成一句完整的回复只需要将刚才新生成的词拼接到当前轮已有结果的后面(图中shifted right的含义),重复上述过程直到模型输出句子结束符。
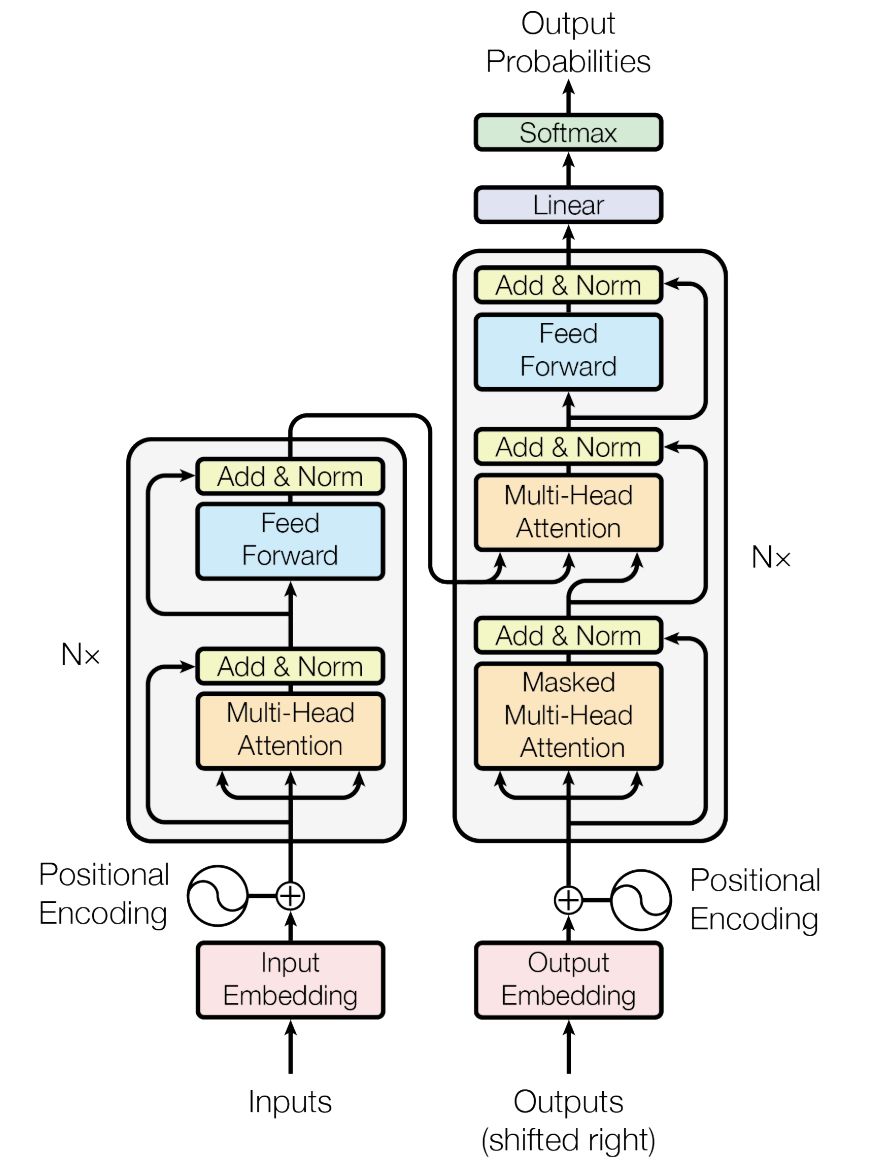
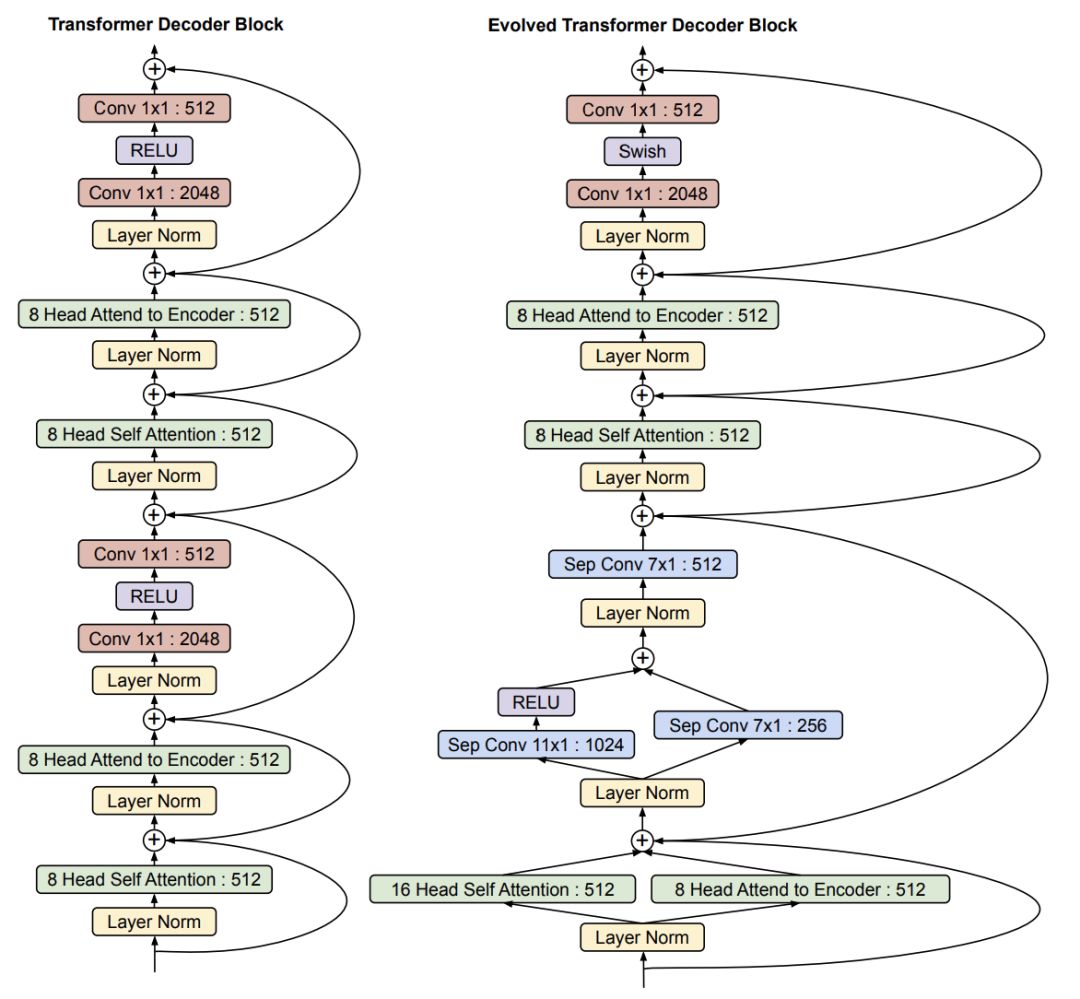
DialoGPT采用的是标准的GPT-2模型,也就是上图模型的加大号版本;而Meena采用的是去年Google通过神经网络结构搜索(NAS)方法得到的进化版transformer模型(Evolved Transformer)。Meena由1个ET编码器和13个ET解码器构成,ET解码器和标准Transformer解码器的对比如下图所示,两者似乎差别不大,论文注脚说一个ET Decoder Block大概是标准Transformer Decoder Block的两倍深。
虽然Meena和DialoGPT都是Transformer模块搭建的模型,但两者规模的差别非常巨大。Meena使用了极其巨大的隐层规模(2560 hidden size,32 attention heads),总参数量达到了惊人的2.6B。相比之下微软的模型就克制很多,最大规模的DialoGPT参数量为762M,表现最好的模型参数量是345M。作为参照,目前地表最强——google的T5模型参数量是11B,BERT large则只有340M。
数据
数据则是两篇论文提升performance的重中之重,特别是对于模型大小比较正常的DialoGPT来说。
DialoGPT论文里明确说数据是从Reddit上搞下来的。通过解析Reddit上的讨论帖,可以获得“树状”的对话数据,然后把每一条从根节点到叶节点的路径拎出来都能获得一个完整的对话。假设一个对话共说了K轮,每次取出当前轮作为标签,之前轮的对话作为输入,总共可以获得K-1条训练数据。Meena的数据来自于public domain social media conversations,他也是从树状对话中获得的数据,我猜测这些对话的形式应该和reddit这种论坛比较相似。
他们的数据量都是非常之巨大的,DialoGPT的总session数是147116725(147M),总词数是1.8B。再来看Meena,他们的总训练数据量是867M,总词数是40B,存成文本文件是341GB。这里可以对比一下之前的模型,BERT的训练数据是16GB,GPT-2的训练数据是40GB,曾经的数据狂魔Roberta是160GB。谷歌再次定义了什么叫大力出奇迹。我在维基百科看到人的平均阅读速度是每分钟200词,按这样的速度1 Billion单词需要一个人不眠不休阅读大概347天。从这个角度看,目前的训练数据量似乎又显得比较合理了。
两篇论文都提到要对数据做非常大刀阔斧的清洗,例如删掉太长或太短的、重复词语多的、含有URL的、不含有常见词的等等。总之,要保证数据质量足够高。
顺便提一下,DialoGPT尝试了从预训练模型迁移和从对话数据集从头训练两种方式。结果是迁移的表现明显好于从头训练。我认为这个现象非常的合理,使用预训练模型就好比教一个学过好几年语文的小朋友在网上聊天,这应该好过一个从小就只通过网络聊天学语文的小朋友。但Meena好像采用的是从头训练的模式,也许他们预训练一把能得到更好的结果。
由于使用了极大的模型和数据集,两个模型都是使用了豪华的硬件来进行训练。DialoGPT使用16个V100,而Meena则使用了2048个TPU v3核训练了30天。512个v2 TPU组成的POD三年协议价是12万美元一个月,v3应该更贵,所以你如果想复现这个模型,至少要花费48万美元。有钱真好:)
解码方式
解码是生成式任务里很重要的一个部分。因为正如前面介绍的,生成模型在推理时每一个时间步只会生成下一个词,而且后面的结果会依赖前面的结果,所以就需要一个好的解码策略来保证这一个个token最后能组成高质量的句子。去年有不少关于解码的工作,希望让机器人产生更有意义、有个性的回复。
DialoGPT没有采用什么独特的解码方式,而是使用了常见的Beam Search(集束搜索),只在最后用了一个较为新颖的重排序算法来从集束搜索得到的TOP K个结果中选出最佳的那个。在排序时,他们用一个训练好的“反向模型”来由生成的回复倒推输入。选用使输入语句概率最大的那个输出作为最终的输出。由于采用了Beam Search,它的解码过程应该是比较耗时的。
Meena比较有意思,作者们表示由于模型的Perplexity(困惑度)够低,完全不需要使用集束搜索。而是采用非常简洁的采样+重排就可以得到好的句子。
困惑度p可以理解为,如果每个时间步都根据语言模型计算的概率分布随机挑词,那么平均情况下,挑多少个词才能挑到正确的那个。
--知乎用户TimsonShi
所谓采样,就是在每一步都根据输出层得到的概率分布,随机选一个输出token,直到得出一个完整的句子。重复采用过程N次,得能到N个句子,最后将这N句话根据归一化后的句子概率排序,选出最优的。需要注意的是他们的输出层并不是对Vocabulary的简单Softmax,而是像知识蒸馏里一样增加了采样温度,即
作者们发现T的大小会影响生成结果。T小的时候,倾向于使用常规词汇,而T大的时候倾向于使用与上下文相关的词汇。论文使用的T为0.88,N为20。他们的结果显示这种采样的效果相比于集束搜索确实有很大的改进。下面一个是集束搜索的结果,另一个是采样,采样很好地避免了集束搜索生成结果丰富性差的弊端。

Beam search 结果

能得到这么好的结果有一个重要前提,就是模型的困惑度也就是perplexity够低。Meena的困惑度有多低呢,它是10.2,相比较之下DialoGPT的困惑度大约是15。
评价指标与结果
对评价指标的选择,两篇论文有很多共同点。他们都已经从BLEU这种考量词级别重合度的离散客观指标进化到了直接跟对话质量相关的抽象指标。从这一点也可以感觉出这个领域已经进入了相对成熟的阶段。DialoGPT使用人工评价的方式,评价模型的relevance,informativeness和how human-like。而Meena则用综合sensibleness和specificity的称为SSA的指标对机器人进行评价。所谓SSA就是对sensibleness和specificity的简单平均,A对应就是average。
Sensibleness我认为基本对应relevance,是指机器人能否得出符合上下文的有意义回答。但有意义是不够的,正如文章所说,一个只会回答“I don't know”这类万金油句子的机器人说的话也是符合上下文的,但其实并不好。
Specificity对应infomativeness,是另一个维度,它评估机器人是否能给出有具体信息的答案。例如当人问”你喜欢电影吗”的时候你可以回答“我不知道/这很难说”,但一个更令人满意的回答可能是”当然,我特别喜欢科幻电影”。
我们来看一下Meena论文里的结果,因为他们为了比较,在相同的评测体系下把DialoGPT也测了。在Meena论文的评价指标下Meena的水平相当高,人类的SSA大概是0.82,Meena是0.78,已经相当接近。其他的对手在Meena面前基本抬不起头来,DialoGPT 0.51,Cleverbot 0.44。他们还评估了小冰和Mitsuku这两个著名的模块化机器人(非端到端的神经对话模型),SSA分别是0.36和0.56。文中还特别提到小冰的Specificity很差,只有0.19,这和我的使用感受是一致的。小冰感觉总是在扯淡,很难说出有意义的东西来。
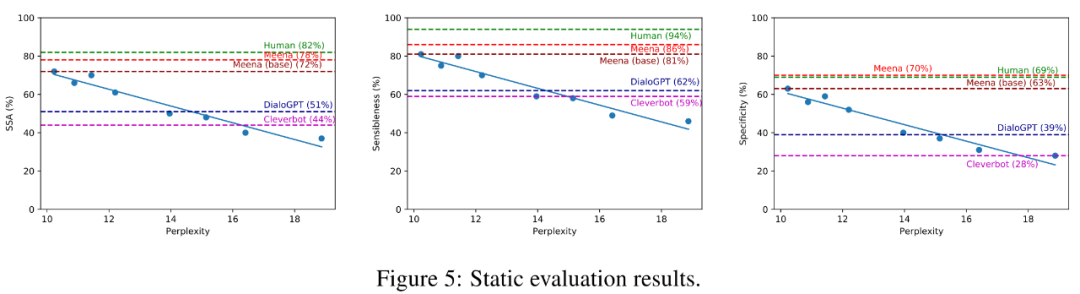
SSA体系虽好,但完全依赖人工评价。Meena论文还评估了perplexity和SSA的相关度。结果如上图所示,横坐标是困惑度,纵坐标是SSA,Perplexity和SSA呈现非常明显的负相关关系,相关度大概是0.94。这就是说在训练模型的时候只需要评估混乱度基本就能知道最终的效果。这个结论我觉得非常重要,它无疑给广大神经对话模型研究人员带来了一个福音,毕竟人工评价实在太麻烦也太贵了。这下好了,以后大家奔着降低perplexity去就好了。
对话样例
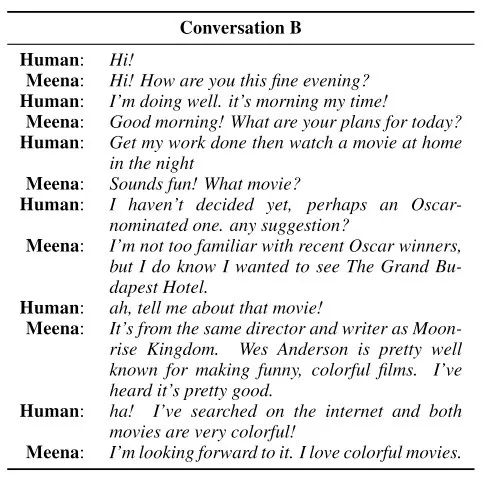
在这一小节再放几张对话小样,从图中可以看出,这些模型的表现都很好,回答不仅流畅还符合一些常识。当然,我们在前面的文章里也讲过,这种隐含知识不太好控制。但只要语料够优秀,效果看起来是非常棒的。

后记
DialoGPT去年年底就发布了,而且微软大方地提供了预训练好的模型,他们也成为了这个领域当时的SOTA,但没想到这么快就被谷歌超越了。今年初看到谷歌连续放出Meena和REALM的时候还是蛮激动的,一个在类人闲聊上获得突破,另一个大幅提高了外挂知识库的利用水平。Twitter上针对这两篇论文也充满了乐观的论调,甚至有人预测2021年我们就能看到AGI了。这两年的技术发展确实让我们对文本数据的利用水平有了质的飞越,虽然不知道AGI如何,中文房间我感觉很快就会造好了。
另外也感慨Quoc V. Le带领的团队最近势头真猛。谷歌海量算力给了他们无限的空间,已经有在CV(例如去年的EfficientNet已经红遍Kaggle社区了)、NLP等领域遍地开花之势。如果中文房间真的盖好了,门牌上应该写的是1600 Amphitheatre Parkway, Mountain View, CA, U.S.吧。
参考阅读
DialoGPT:
http://arxiv.org/abs/1911.00536, https://github.com/microsoft/DialoGPT
Meena:
http://arxiv.org/abs/2001.09977
The Evolved Transformer:
http://arxiv.org/abs/1901.11117
求通俗解释NLP里的perplexity是什么?
https://www.zhihu.com/question/58482430
推荐阅读
抛开模型,探究文本自动摘要的本质——ACL2019 论文佳作研读系列
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。




