CSIG云上微表情第十二期研讨会成功举办--有限多源数据下的微表情识别方法
微表情是一种短暂的、微弱的、无意识的面部微表情,持续时间往往在0.5s内,能够揭示人类试图隐藏的真实情绪。微表情识别的研究旨在让机器有足够的智能,能够从人脸视频序列中识别人类的真实情绪。然而由于微表情持续时间短、面部肌肉运动强度低,对其进行准确的表征与识别是一项极具挑战性的任务。为了促进心理学领域和计算机视觉领域针对微表情的进一步研究,由中国图象图形学学会(CSIG)主办、CSIG机器视觉专业委员会承办,中国科学院心理研究所的王甦菁博士组织了一系列云上微表情的学术活动。

第十二期云上微表情于2021年1月29日晚上7点进行,由中国科学院心理研究所王甦菁老师团队的李婧婷博士主持。此次讲座邀请到来自西北工业大学的夏召强副教授做主题为有限多源数据下的微表情识别方法的相关报告,报告得到了微表情研究领域的广泛关注,期间有五十多位听众参加了此次讲座。
此次讲座主要分为四个部分,夏博士首先简要概述了描述微表情微弱变化的手工设计特征和基于深度模型的自主特征学习两种方式,然后详细介绍了有限多源数据下的深度学习模型构建方法,基于卷积神经网络设计了面向微表情识别的循环网络结构和网络搜索方法,最后对本领域的难点问题与研究趋势进行了总结。

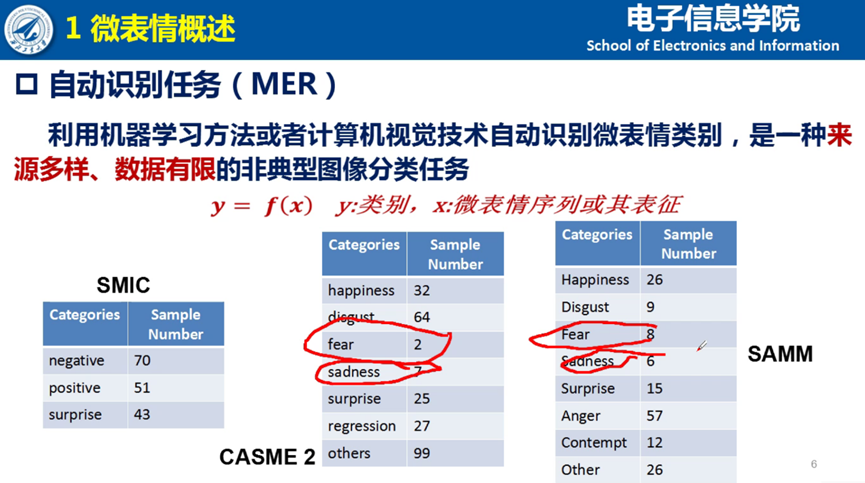
其次,夏博士提出微表情的自动识别任务是一种非典型性识别任务。通过分析目前常用的三个数据库样本情况,可以看出微表情的样本来源多样、数据有限。因此,和传统的心理学或者计算机视觉研究方法相比,微表情代表了一批小样本的非典型性图像识别任务。
2. 微表情识别的发展现状
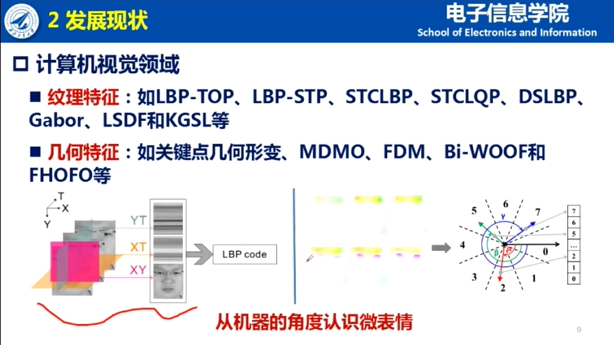
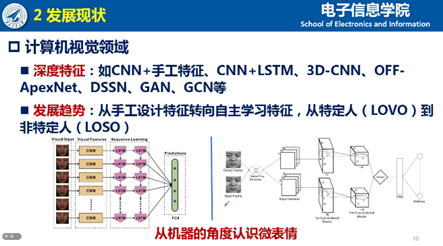
在简要展示心理学领域微表情研究概况以后,夏博士介绍了结合计算机视觉的微表情分析的发展,包括目前主流的实验室条件下的自发微表情数据库,常见的手工提取微表情特征(纹理特征、几何特征),深度特征(CNN、LSTM、GAN和GCN等)以及之后的发展趋势。
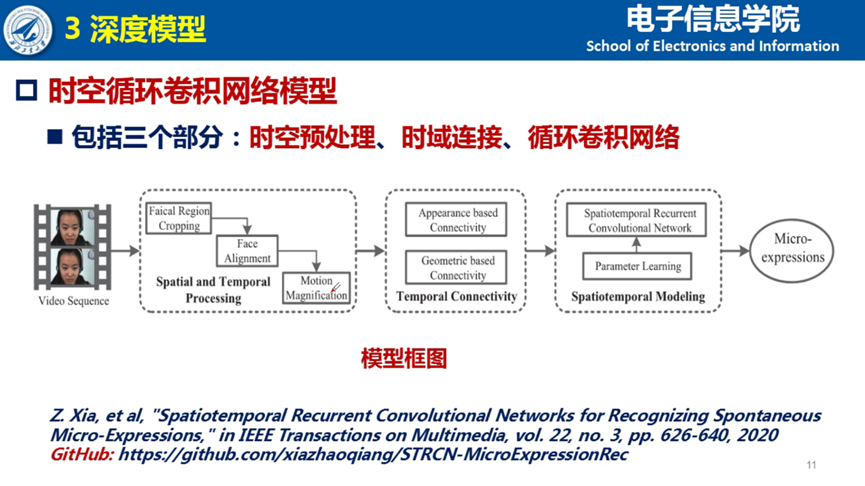
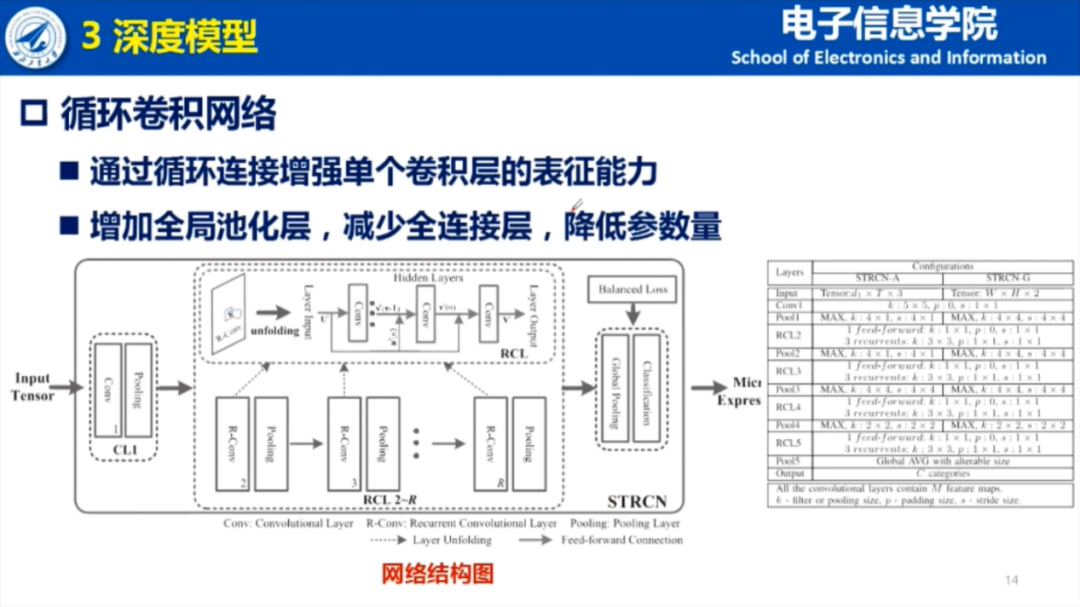
其次,面对单数据集的样本失衡问题,受启发于图像检索中应用的技术,夏博士通过加权的方式来平衡损失。同时为了弥补样本量少对模型训练的限制,采用了数据增强的方法,包括多尺度放大因子和多比例帧数选取。

最后,夏博士通过大量实验数据,分析了数据增强、样本平衡处理、特征图数目以及循环层数对网络性能提升的影响。
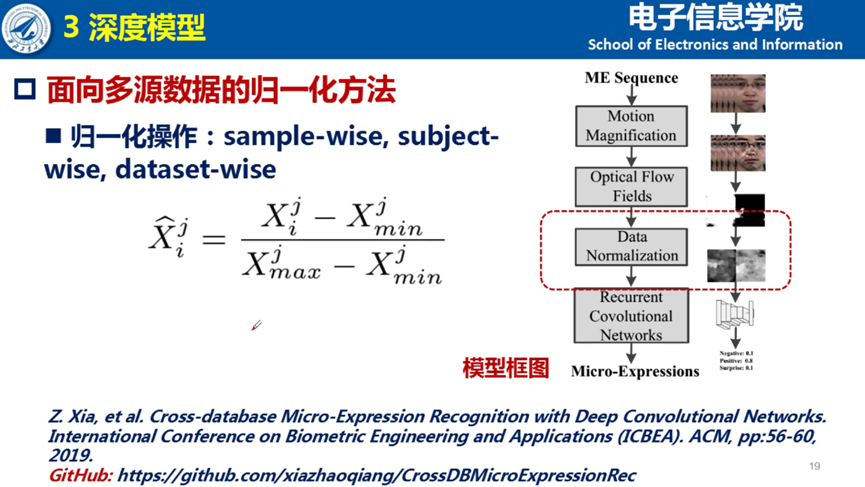
4. 面向多源数据的归一化方法
夏博士介绍,通过实验数据分析,可以看出数据库之间的归一化对微表情识别的性能提升帮助并不显著。微表情同一样本以及数据集的归一化,反而造成了隐形的数据泄露。
5. 低复杂度循环卷积网络模型
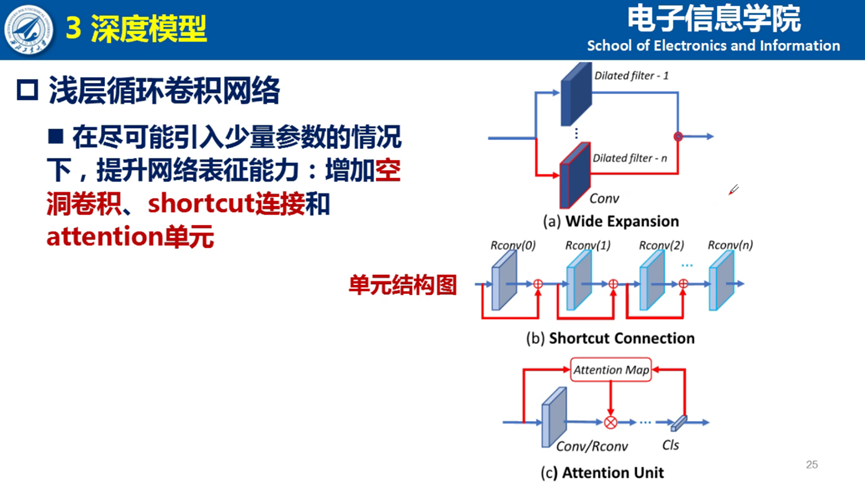
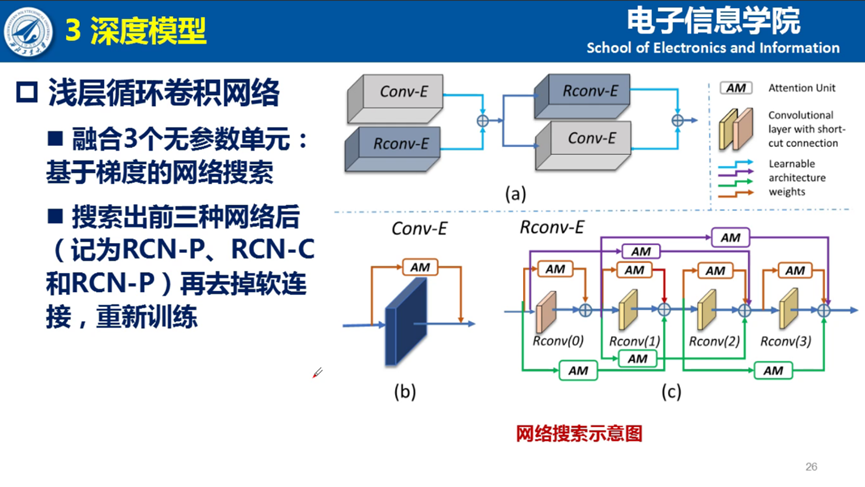
基于上述的经验总结,夏博士提出了低复杂度循环卷积网络。对合成数据集来说,当模型比较复杂或者特征图比较大的时候,模型的关注集中在全脸,反而损失了一定局部区域的特征提取能力。因此,夏博士选择了低复杂度的网络,包括更低的结构和更低的输入。
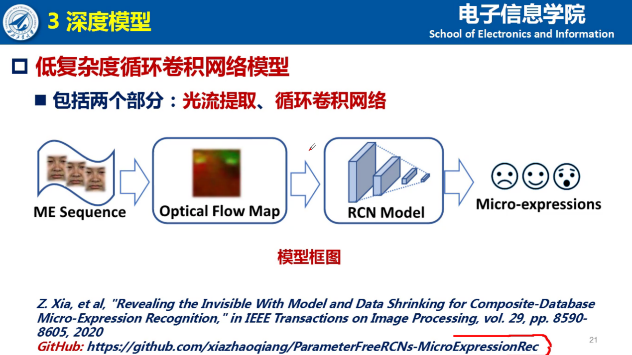
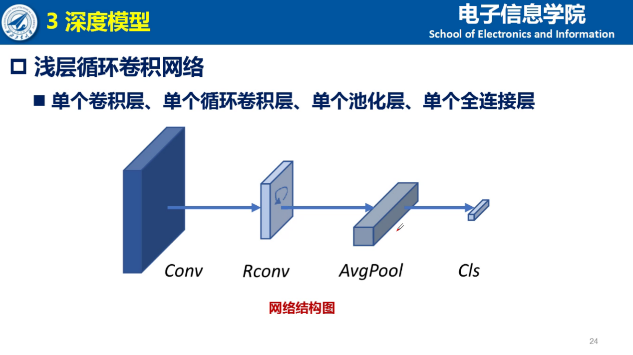
同时为了避免表征能力下降,夏博士通过选择不同的stride size,借鉴dense connection的shortcut连接,借鉴CAM的思想增加attention map等方法,在不引入更多的学习参数的同时,提升模型复杂度。
6. 基于元学习的快速学习算法
最后夏老师介绍了他们目前最新的工作,由于微表情识别任务中leave one subject out cross validation的训练样本和测试样本可能存在较大的差异分布问题,夏博士引入了元学习的方法进行研究。相关结合元学习的方法提升了训练学习的速率,但还没有提升学习性能。

7. 目前的问题和挑战
在报告的最后,夏博士指出目前结合深度学习的微表情识别已成为主流,微表情小样本和网络复杂度的平衡、单一数据集和合成数据集的网络区别、消除采集环境的差异性以及微表情的实际应用等问题都值得关注。

在讨论环节,听众们踊跃发言,提出了很多非常有讨论意义的问题,其中包括微表情识别样本预处理的相关细节、微表情小样本导致模型训练过拟合问题、单个数据库与合成数据库处理过程中的技术差异、以及结合元学习的微表情识别的进一步讨论。
在活动的最后,讲座的主持人李婧婷博士对活动进行了总结并对第十三期CSIG云上微表情活动进行了大致预告。敬请继续关注!
此次讲座的回放已经发布在B站:https://www.bilibili.com/video/BV1nA411u7mp,欢迎观看!
祝大家新春快乐,牛年大吉!

