斯坦福齐鹏、陈丹琦解读两大新QA数据集:超越模式匹配的机器阅读理解
选自 ai.stanford.edu
机器之心编译
参与:Geek AI、路
近日,斯坦福大学博士齐鹏和陈丹琦发表博客,介绍了二人分别参与创建的两个 QA 数据集:HotpotQA 和 CoQA 数据集。这两个数据集尝试囊括超越常见模式匹配方法所能回答的问题,增加机器阅读理解和问答的难度,从而促进相关研究的发展。
你是否曾经在谷歌上随意搜索过一些问题?比如「世界上有多少个国家」,当你看到谷歌向你展示的是准确的答案,而不只是链接列表时,你是否感到十分惊讶?这个功能显然很酷炫也很有用,但是它仍然有局限。如果你搜索一个稍微复杂的问题,比如「我需要骑多长时间的自行车才能消耗掉一个巨无霸汉堡的卡路里」,你不会直接从谷歌搜索那里得到一个好的答案(即使任何人都可以通过谷歌搜索给出的第一个或第二个链接的内容得到答案)。
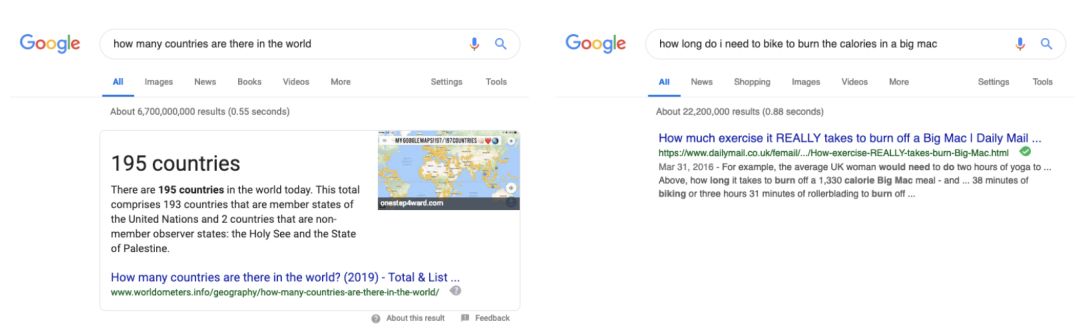
截至本文写作时,使用谷歌进行搜索的结果示例。
在当下这个信息爆炸的时代,每天有太多新知识以文本的形式生成(也有其它模态),任何人都无法独自消化这些知识。对人们来说,让机器阅读大量文本并回答问题是自然语言理解领域最重要、最实际的任务之一。解决机器阅读或问答任务将为建立强大而渊博的人工智能系统奠定重要基石,就像电影《时光机器》中的图书管理员那样。
近期,像 SQuAD 和 TriviaQA 这样的大规模问答数据集推动了这一方向的诸多进展。通过让研究人员训练需要大量数据的强大深度学习模型,这些数据集已经催生了许多令人印象深刻的结果(例如一种算法可以在维基百科页面上寻找合适的答案,来回答许多随机提出的问题),这在某种程度上让人类不必再自己完成这些艰难的工作。
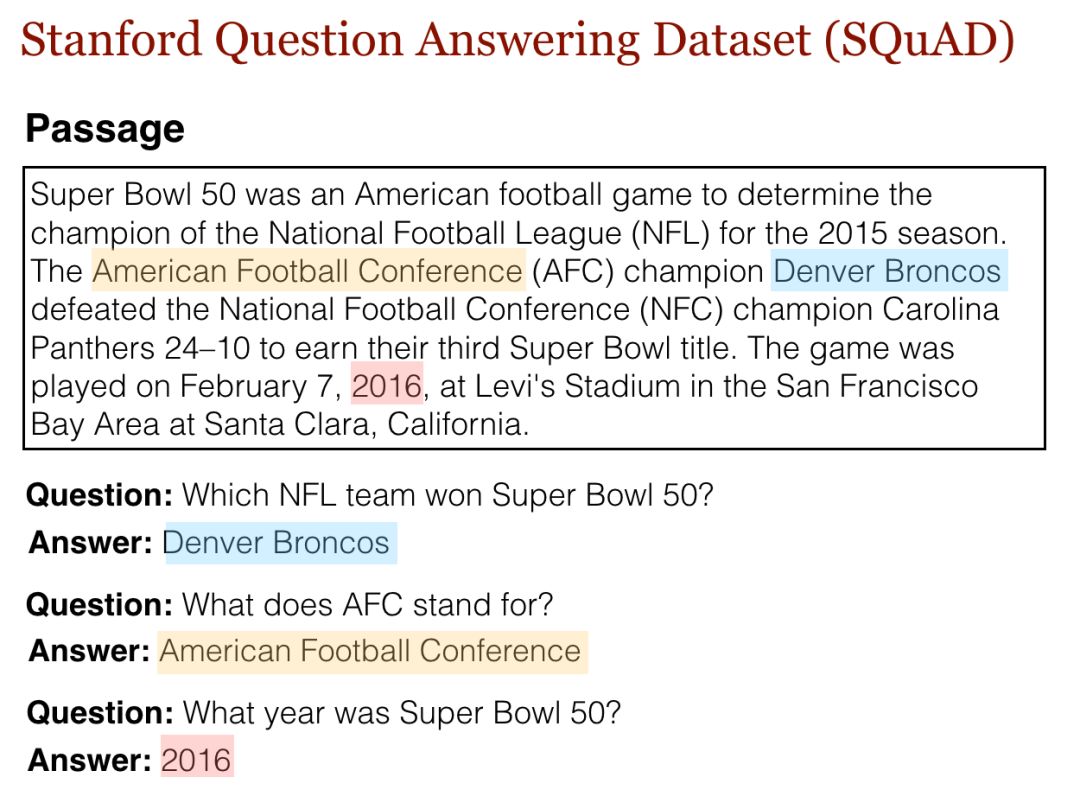
SQuAD 数据集包含从超过 500 多篇维基百科文章中收集到的逾 10 万份问答样本。文章中的每一段都有一个独立的问题列表,这些问题必须可由段落中一段连续文字来回答(参见上图中基于维基百科文章「Super Bowl 50」的例子),也称为「抽取式问答」。
然而,尽管这些结果看起来不错,但这些数据集有明显的缺陷,从而限制了该领域的进一步发展。事实上,研究人员已经表明,使用这些数据集训练出来的模型实际上并没有学习到非常复杂的语言理解能力,它们只是很大程度上利用了简单的模式匹配启发式方法。

上图来自 Jia 和 Liang 的工作。在右图中,段落末尾添加的简短句子表明,模型实际上是将城市名称进行模式匹配,而不是真正理解了问题和答案。
在这篇博文中,我们介绍了斯坦福 NLP 组最近收集的两个数据集,旨在进一步推进机器阅读理解领域的发展。具体而言,这些数据集旨在将更多的「阅读」和「推理」过程引入问答任务中,不再只是仅通过简单的模式匹配可以回答的问题。第一个数据集是 CoQA,该数据集为关于一段文本的自然对话引入包含丰富上下文信息的接口,试图从对话的角度来解决这个问题。第二个数据集是 HotpotQA,其范围不再局限于一段文本,而是提出了对多个文档进行推理从而得出答案的挑战。本文接下来将详细介绍这两个数据集。
CoQA:对话式问答系统
何为 CoQA?
目前大多数问答系统局限于单独回答问题(如上面 SQuAD 的例子所示)。虽然这种问答交流有时确实会发生在人与人之间,但通过涉及一系列相互关联的问题和答案的对话来搜寻信息的做法更为常见。CoQA 是我们为解决这一限制而开发的对话式问答数据集,旨在推动对话式人工智能系统的发展。
该数据集囊括来自 7 个不同领域的文本段落里 8000 个对话中的 127,000 轮问答。

如上图所示,一个 CoQA 示例由一个文本段落(示例中的文本来自于某篇 CNN 新闻文章)和一段与文本内容相关的对话组成。在这段对话中,每一轮问答包含一个问题和一个答案,第一轮之后的每个问题都依赖于目前为止进行过的对话。与 SQuAD 以及许多现有数据集不同,对话的历史对于回答许多问题是必不可少的。例如,对于第二个问题 Q2(where?),在不知道对话历史的情况下是不可能回答出来的。同样值得注意的是,对话中的焦点实体(entity of focus)是会改变的。例如,Q4 中的「his」、Q5 中的「he」以及 Q6 中的「them」指的是不同的实体,这使得理解这些问题变得更具挑战性。
除了「CoQA 的问题需要在对话的上下文语境中才能被理解」这一关键因素以外,CoQA 还有许多其他吸引人的特性:
一个重要的特性是,我们并没有像 SQuAD 那样把答案限制在一段连续的文字中。我们认为,许多问题不能仅仅根据段落中的某段文字来回答,这会使对话不那么自然。例如,对于「How many」这样的问题,即使段落中的文本并没有直接说明,但我们也可以简单地回答「3 个」。同时,我们希望该数据集支持可靠的自动评估,并且能够与人的理解高度一致。为了解决这个问题,我们要求标注者首先将与答案依据相关的文本内容重点摘取出来(参见本例中的 R1、R2),然后将这些文字编辑成一个自然的答案。这些依据可用于训练(但是不能用于测试)。
现有的 QA 数据集大多重点关注某个单一领域,这使我们很难测试现有模型的泛化能力。CoQA 的另外一个重要特性是,它的数据来源于 7 个不同的领域——儿童故事、文学、初中和高中英语测试、新闻、维基百科、Reddit 以及科学。我们将后两个领域的数据用作域外评估。
我们对 CoQA 数据集进行了深入分析。如下表所示,我们发现该数据集展示出了一系列语言学现象。近 27.2% 的问题需要结合语用推理(如常识、预设)。例如,对于问题「Was he loud and boisterous?」并不能将「he dropped his feet with the lithe softness of a cat」作为直接回答依据,但将该依据与世界知识结合起来就可以回答这个问题。只有 29.8% 的问题可以通过简单的词汇匹配(即直接将问题中的单词与文本内容相对应)来回答。
我们还发现,只有 30.5% 的问题可以单独回答,不需要使用共指关系回溯到对话历史。49.7% 的问题包含显式的共指关系标志词(如 he、she 或 it),其余 19.8% 的问题(例如「where?」)会隐式地提到一个实体或事件。

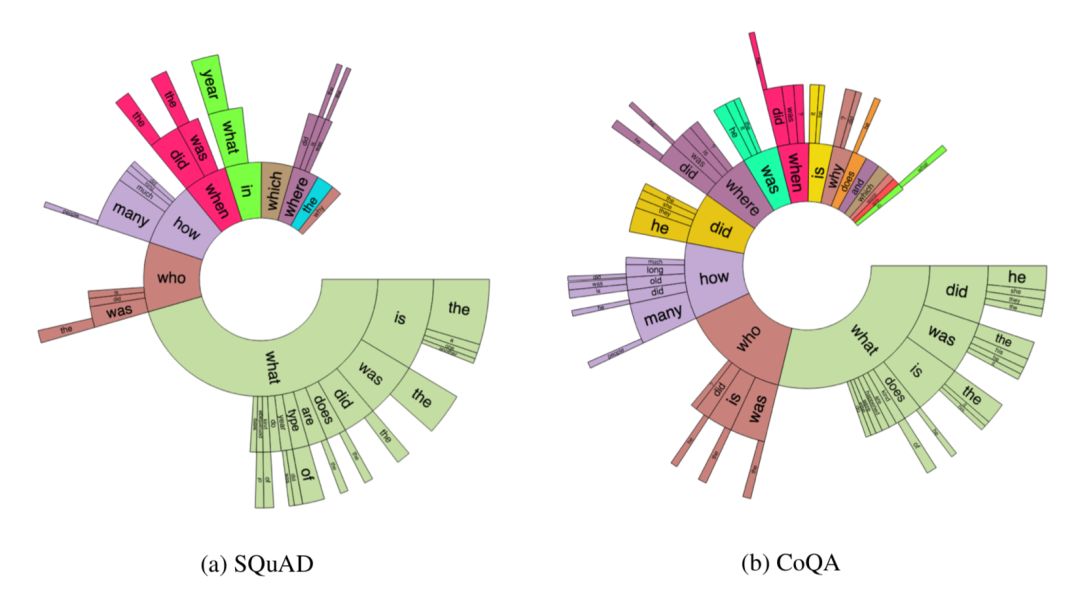
与 SQuAD 2.0 的问题分布相比,CoQA 数据集中的问题比 SQuAD 短得多(问题平均包含单词量比例是:5.5 vs 10.1),这反映出 CoQA 数据集的对话属性。CoQA 数据集的问题种类也更多样:SQuAD 中近一半的问题是由「what」类型的问题主导,而 CoQA 的问题分布则分散在多种类型。用「did」、「was」、「is」、「does」引导的问题在 CoQA 数据集中很常见,但在 SQuAD 中则完全不存在。
最新进展
自从我们在 2018 年 8 月发起 CoQA 挑战赛之后,它受到了极大关注,成为研究社区中最炙手可热的基准数据集之一。我们惊奇地发现,在那之后有那么多研究进展,尤其是在谷歌发布 BERT 模型之后(它极大地提高了当前所有系统的性能)。
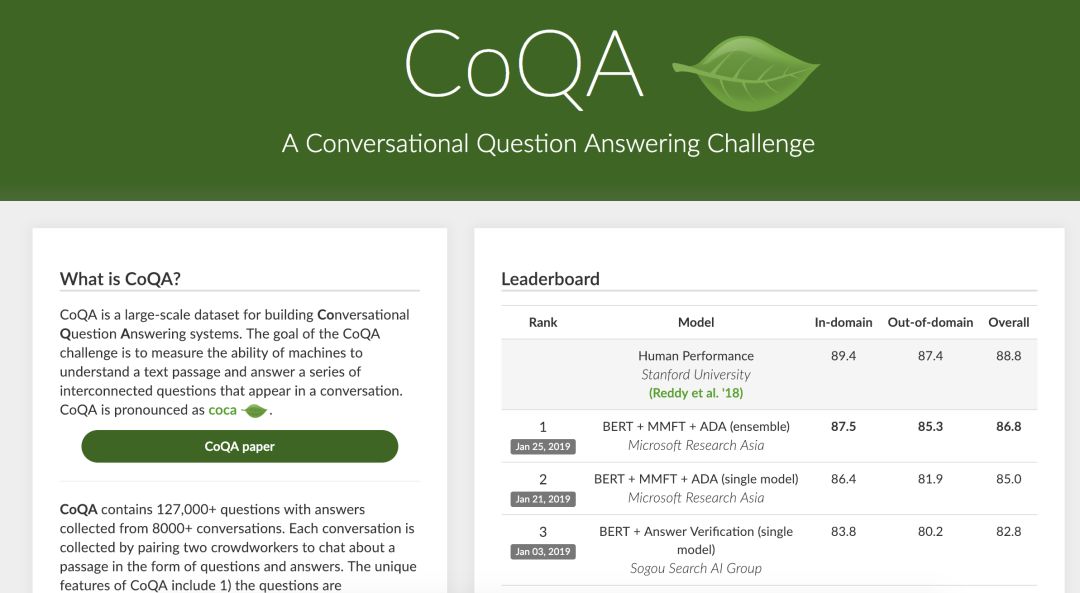
微软亚洲研究院提出的 SOTA 集成系统「BERT+MMFT+ADA」达到了 87.5% 的域内 F1 准确率,85.3% 的域外 F1 准确率。这些数字不仅接近人类的表现,也比我们六个月前开发的基线模型高出了 20 多个百分点(可以看出我们的研究社区进步非常快!)。我们期待在不久的将来看到这些论文以及开源的系统。
HotpotQA:用于多个文档的机器阅读理解数据集
除了通过长时间对话深入掌握给定段落的语境之外,我们还经常发现自己需要通读多个文档来找出关于这个世界的客观事实。
例如,有人可能会问「雅虎是在哪个州成立的?」或者「斯坦福大学和卡内基梅隆大学谁拥有更多的计算机科学研究者?」,或者更简单地问「我需要跑多久才能够消耗一个巨无霸汉堡的卡路里?」
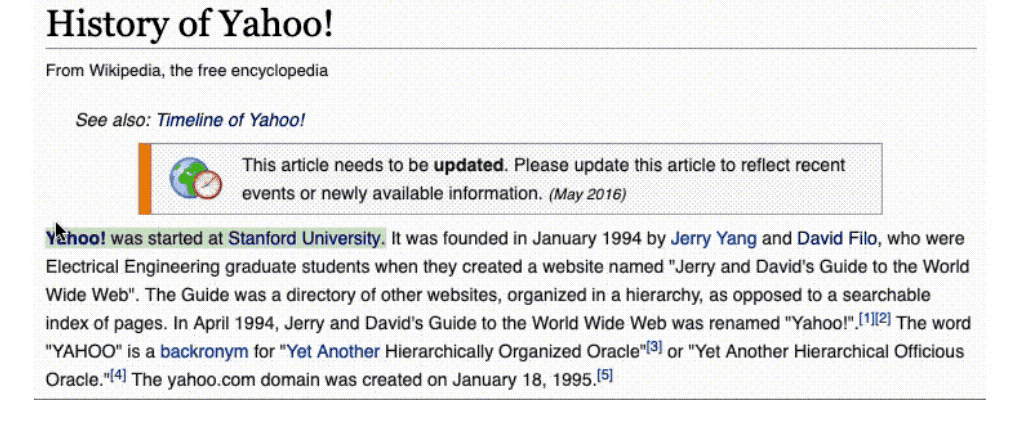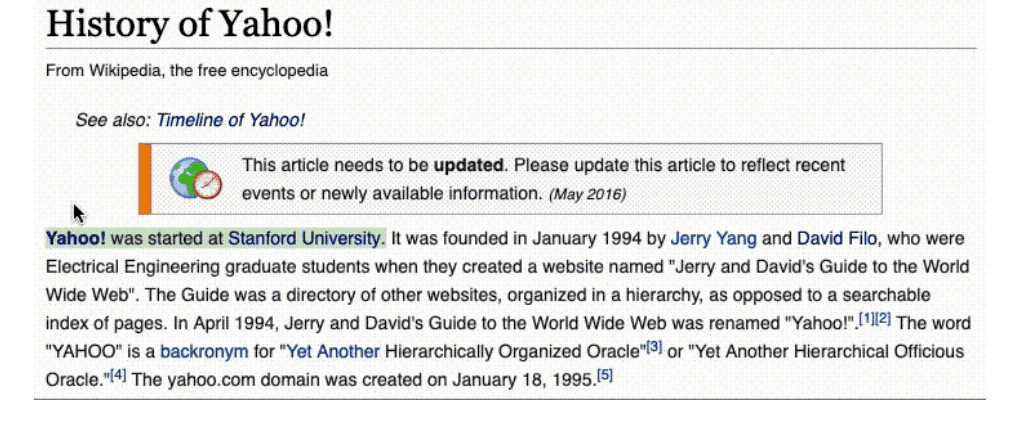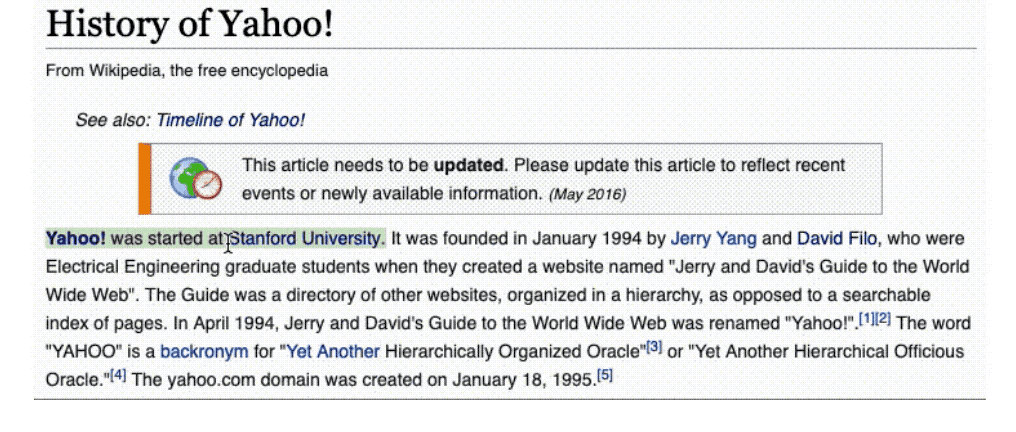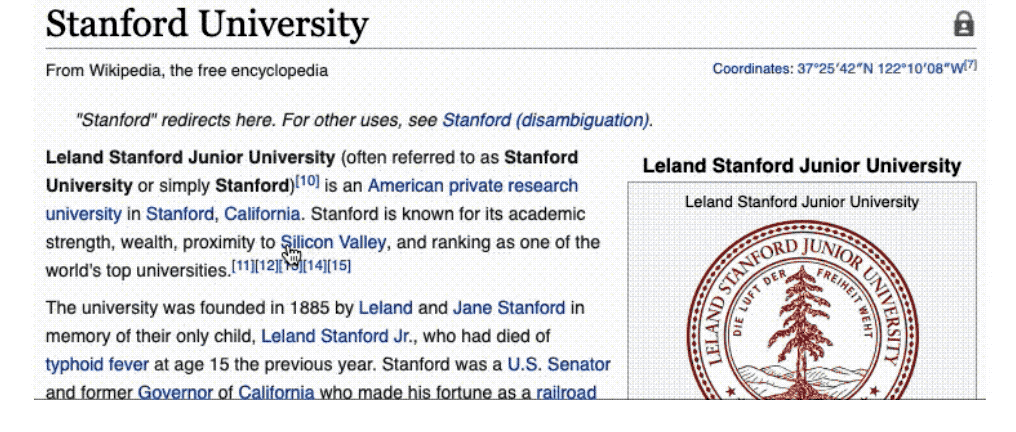
网上有许多关于这些问题的答案,但是这些答案并不是现成的可以回答相应问题的形式,甚至这些答案都不集中在同一个地方。例如,如果我们以维基百科作为知识源来回答第一个问题(雅虎在哪里成立的),我们最初感到困惑的是,关于雅虎或者其联合创始人杨致远和 David Filo 的网页上并没有提到这条信息。为了回答这个问题,你需要费尽心思地浏览维基百科上的多篇文章,直到最终看到这篇名为「History of Yahoo!」的文章。
正如你所看到的,我们可以通过以下的推理步骤来回答这个问题:
我们注意到这篇文章的第一句话指出雅虎成立于斯坦福大学。
然后,我们在维基百科上查找斯坦福大学(在本例中,我们只是点击了链接),找出它的位置。
斯坦福大学的网页告诉我们它位于加州。
最后,我们可以把这两个事实结合起来,可以得出原来问题的答案:雅虎是在加州成立的。
请注意,要想回答这个问题,有两个技能是必不可少的:(1)做一些类似于侦探的工作,找出哪些文档或支撑性事实可用于得出答案。(2)对多个支撑性事实进行推理,从而得出最终的答案。
这些都是机器阅读理解系统必须具备的重要能力,可使它们高效地帮助人类消化不断增长的海量文本形式信息和知识。然而,由于现有数据集专注于在单个文档中寻找答案,在解决数据爆炸的挑战方面还做得不够,因此我们创建了 HotpotQA 数据集来实现这一点。
什么是 HotpotQA
HotpotQA 是一个大型问答数据集,它包含约 11.3 万个具备上述特征的问答对。也就是说,这些问题要求问答系统能够筛选大量的文本文档,以找到与生成答案相关的信息,并对找到的多个支撑性事实进行推理,从而得出最终答案(参见下面的示例)。

HotpotQA 数据集中的一个问题示例。
该数据集中的问题和答案来自于英文维基百科,涵盖了从科学、天文学和地理到娱乐、体育和法律案件等多种主题。
这些问题需要通过一些有难度的推理来回答。例如,在前面提到的雅虎的例子中,我们需要首先推断出「雅虎」与回答问题的关键「缺失环节」斯坦福大学之间的关系,然后利用「斯坦福大学位于加州」这一事实得出最终答案。大致上,推理链如下所示:

这里,我们把「斯坦福大学」称为上下文中的桥梁实体(bridge entity),因为它是已知实体「雅虎」和预期的答案「加州」之间的桥梁。我们注意到,实际上人们感兴趣的许多问题都在某种程度上涉及到这类桥梁实体。
比如这个例子:「赢得 2015 年 Diamond Head Classic MVP 的运动员为哪支队伍效力?」
在这个问题中,我们可以先问问谁是 2015 年 Diamond Head Classic 的 MVP,然后再去查这个运动员目前效力的队伍。在这个问题中,MVP 球员(Buddy Hield)是帮助我们得出最终答案的桥梁实体。这与我们在雅虎问题中的推理存在微妙差别:「Buddy Hield」是原始问题一部分的答案,而「斯坦福大学」并非如此。

人们可以很容易地想出一些桥梁实体就是答案的有趣问题,比如:Ed Harris 主演的哪部电影是根据法国小说改编的?(答案是 Snowpiercer。)
显然,这些包含桥梁实体的问题无法涵盖人们通过对多个从维基百科上收集到的客观事实进行推理来回答的所有有趣问题。在 HotpotQA 中,我们收集了一种新型问题——比较问题,以表示更多样化的推理技能和语言理解能力。
我们已经在前面看到了一个比较问题的示例:「斯坦福大学和卡内基梅隆大学谁拥有更多的计算机研究者?」
要想成功地回答这些问题,问答系统不仅需要找到相关的支撑性事实(在本例中,需要找到斯坦福大学和卡内基梅隆大学分别有多少计算机科学研究人员),还需要以一种有意义的方式对它们进行比较,从而得到最终的答案。正如我们对该数据集的分析所显示的那样,后者对于当前的问答系统是很有挑战性的,因为它可能涉及数值比较、时间比较、计数,甚至简单的算术。
前者(寻找相关的支撑性事实)也不容易,甚至可能更具挑战性。虽然定位相关事实通常相对容易,但这对于包含桥梁实体的问题来说十分重要。
我们使用传统信息检索(IR)方法进行了一些实验,该方法将给定的问题作为查询,对维基百科上的所有文章从相关性最高到相关性最低排序。因此,我们看到,在正确回答问题所必需的两段(我们称之为「黄金段落」)中,只有大约 1.1 段出现在前 10 个结果中。在下面的黄金段落 IR 排序图中,排序较高的段落和排名较低的段落都呈现出重尾分布。
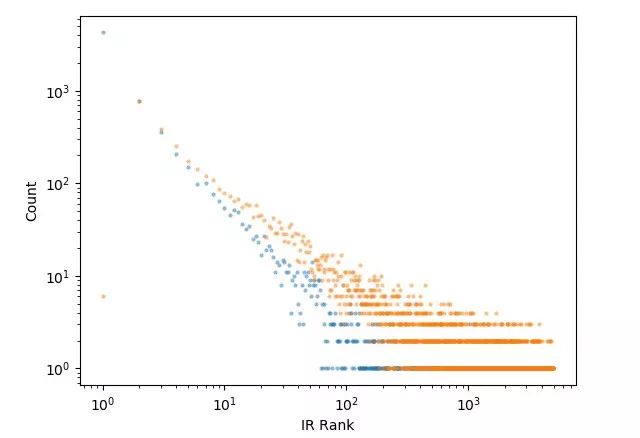
更具体而言,尽管 80% 以上的排序较高段落可以在前 10 个 IR 结果中找到,但是只有不到 30% 的排名较低段落可以在相同的范围内找到。我们通过计算发现,如果系统老老实实地读取所有的排名较高文档直到找到两个黄金段落,这相当于平均阅读 600 个文档才能回答一个问题,甚至在这之后算法仍然不能可靠地判断我们是否找到了两个黄金段落。
这就需要有新的方法,来解决需要进行多步推理情况下的机器阅读理解问题,这方面的进展将大大促进更有效的信息获取系统的开发。
建立可解释的问答系统
优秀问答系统的另一个重要的、被期望实现的特征就是可解释性。实际上,一个仅能够给出答案而没有任何解释或演示来验证答案正确性的问答系统几乎是没有用的,因为用户不敢相信它给出的答案(即使它们在大多数情况下是正确的)。然而不幸的是,许多最先进的问答系统都存在这个问题。
为此,HotpotQA 在收集数据时,我们要求标注者指出他们用来得出最终答案的支撑性语句,并将这些句子作为数据集的一部分一起发布。
下图示例来自 HotpotQA 数据集,绿色的句子表示对答案起支撑作用的事实(尽管在本例中需要经过多步推理才能得出答案)。读者如想获取更多此类支撑性事实,可以通过「HotpotQA 数据浏览器」(https://hotpotqa.github.io/explorer.html)查看更多示例。
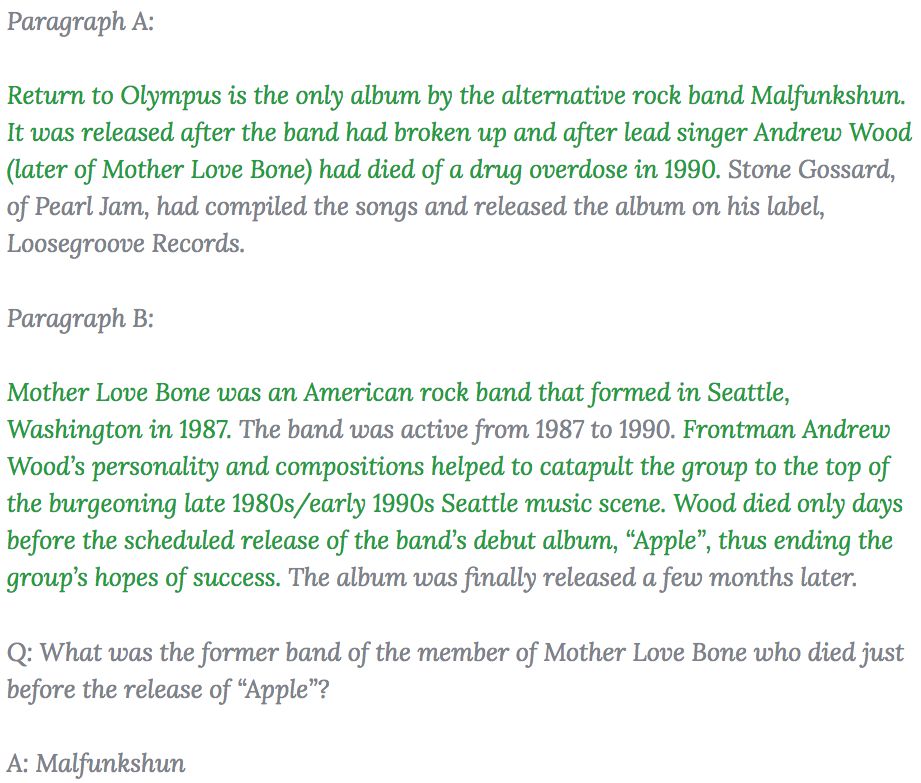
通过实验我们可以看到,这些支撑性事实不仅可以让人们更容易地审核问答系统给出的答案,也可以为模型提供比之前问答数据集更强的监督,从而提升模型更准确地找到期望答案的性能,而这是之前该方向的问答数据集所欠缺的。
总结
随着大量人类知识以书面形式被记录下来,并且每秒钟都有越来越多的知识被数字化表示,我们相信,将这些知识与能够自动阅读、推理和回答问题且具备可解释性的系统集成在一起具有巨大的价值。现在,我们不应局限于开发那些只能在单轮问答中查看少数几个段落和句子、不具备可解释性、主要依靠模式匹配的问答系统。
因此,CoQA 考虑了在给定上下文的自然对话中可能出现的一系列问题,其中具有挑战性的问题在于它需要进行多轮对话的推理;另一方面,HotpotQA 重点关注多文档推理,这要求研究社区开发新的方法,以从大型语料库中获取支撑性信息。
我们相信这两个数据集将推动问答系统的重大发展,也期待这些系统为研究社区带来新的思路。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




