解决大模型超参调优的难题!微软和OpenAI提出Efficient Hyperparameter Tuning

极市导读
在大家面对大模型束手无策的尴尬境况,最近微软和OpenAI合作的新工作μTransfer为大模型的超参数调优提供了解决方案,本文简要介绍了该篇工作。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
超参数调优对深度学习的重要性不言而喻,很多深度学习算法工程师都自嘲是“调参侠”,但“调参侠”面对大模型也束手无策,因为大模型训练成本高昂,GPT-3训练一次的费用是460万美元,甚至在明知有bug的情况下都无法重新训练一遍,在这种情况下,能完成模型训练已经实属不易,更不仅要说进行超参数调优了。因此,以往大模型的训练可以说都是不完整的,缺少了“超参数调优”这一重要环节,然而,最近微软和OpenAI合作的新工作μTransfer为大模型的超参数调优提供了解决方案,如图1所示,即先在小模型上进行超参数调优,再迁移到大模型,下面将对该工作进行简单介绍,详细内容可参考论文《Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer》。

论文链接:https://arxiv.org/pdf/2203.03466v1.pdf
代码链接:https://github.com/microsoft/mup

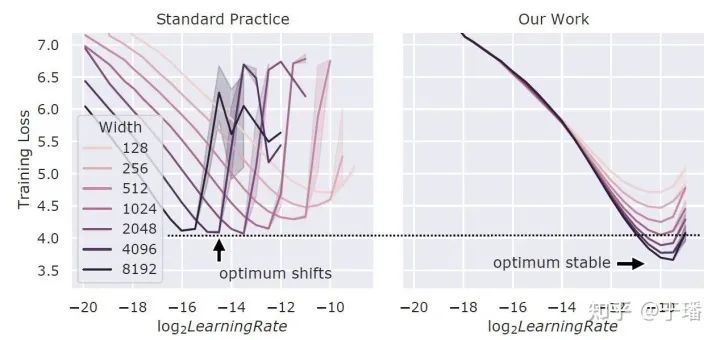
可能有人会有疑问,先在小模型调优超参数,再迁移到大模型,这个思路好像也不难,之前没有人试过吗?从论文中的分析来看,这个方法并不是总是奏效的,得先使用μP(Maximal Update Parametrization)方法初始化模型参数,该方法可参考作者的另一篇工作《Feature Learning in Infinite-Width Neural Networks》。如图2所示,当在Transformer模型中增加模型宽度时,如果不使用μP,不同宽度的模型的最优超参并不一致,更宽的模型并不总是比窄模型效果更好,而使用μP,不同宽度模型的最优学习率基本一致,宽模型总是比窄模型效果好。
那使用 μTransfer 时可以使用那些扩大模型规模的方法呢?μTransfer 又对哪些超参数有效?作者也在论文中进行了总结,如图3所示。其中带*号的只在Transformers上进行了实验验证,而其他的都有理论证明。

作者将 μTransfer 的技术收益总结为以下5点:
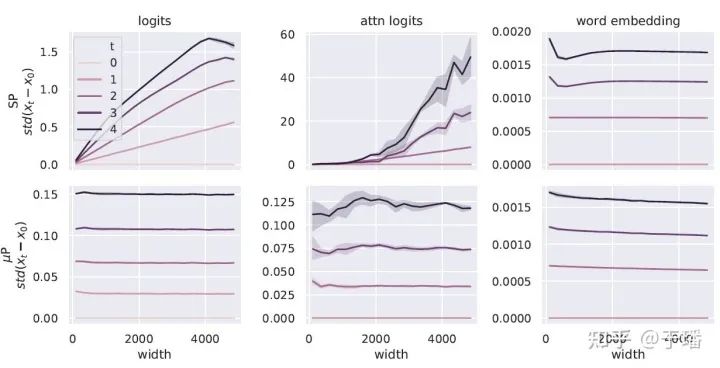
1. 更好的效果。作者强调 μTransfer不仅提高了超参数调优的效率,而且如图1所示,即使都使用了最优的超参数,预训练的效果也更好,作者使用 μTransfer 训练的BERT-large 和 GPT-3 都超过了发布版本的模型,作者将原因归结为 μP 可以避免标准参数化的 Transformer 随着宽度增加 logits 和 attention logits 会blow up 而 word embedding 却不会 blow up 的问题, 如图4所示,因此最优的超参数可以使得word embedding得到更好的训练;
2. 加速大模型的超参数调优。在 BERT-large 上进行 μTransfer 的开销相当于预训练一次 BERT-large,在 6.7B GPT-3 上进行 μTransfer 的开销相当于预训练一次 6.7B GPT-3开销的 7%;
3. 对整个模型家族只需要进行一次调参;
4. 更好地利用计算资源。因为超参数调优是在小模型上进行的,所以通常不需要用到集群,这样更有利于计算资源的调度和并行;与之相比,AutoML等技术也能加速超参数调参的过程,但因为调参过程中的模型规模不变,仍然需要用到计算集群;
5. 从模型研究到 scaling up 的无痛迁移。很多模型创新都是在小模型上进行的,但在迁移到大模型时发现收效甚微,这也有可能是没有进行很好的超参数调优导致的,使用 μTransfer 可以实现小模型到大模型超参的无痛迁移。
作者开源了一个可以通过 pip 安装的包,叫 mup,安装和使用都较简单,有兴趣的朋友可以进行试用,github链接为 https://github.com/microsoft/mup
这篇工作是近来在大模型领域不多的创新型工作,从理论推导到实验都比较扎实,让人眼前一亮,但该方法的理论证明仅支持通过宽度增加模型规模,深度等维度都是通过实验验证的,希望在后续其他研究人员对 mup 的使用中,可以进一步证明该方法的泛化性和在不同模型上的适用性。
公众号后台回复“数据集”获取100+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




