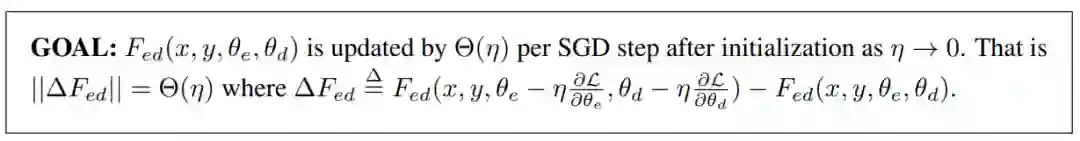1000 层的 Transformer,深得吓人。
昨日出炉的论文《DeepNet: Scaling Transformers to 1,000 Layers》在研究社区引起了热议,作者来自微软亚洲研究院。
该研究直接把 Transformer 深度提升到 1000 层!
近年来,大规模 Transformer 模型出现了这样一种趋势:随着模型参数从数百万增加至数十亿甚至数万亿,性能相应地实现了显著提升。大规模模型在一系列任务上都取得了 SOTA 性能,并在小样本和零样本学习设置下展现出了令人瞩目的能力。如下图 1 所示,尽管参数量已经很大了,但 Transformer 模型的深度(depth)却受到了训练不稳定的限制。
Nguyen 和 Salazar (2019) 发现,基于 post-norm 连接(Post-LN),pre-norm 残差连接(Pre-LN)能够提升 Transformer 的稳定性。但是,Pre-LN 在底层的梯度往往大于顶层,因而导致与 Post-LN 相比性能下降。为了缓解这一问题,研究人员一直努力通过更好的初始化或更好的架构来改进深度 Transformer 的优化。这些方法可以使多达数百层的 Transformer 模型实现稳定化,然而以往的方法没有能够成功地扩展至 1000 层。
微软亚研在一篇新论文《DeepNet: Scaling Transformers to 1,000 Layers》中终于将 Transformer 的深度扩展到了 1000 层。
![]()
论文地址:https://arxiv.org/pdf/2203.00555.pdf
研究者的目标是提升 Transformer 模型的训练稳定性,并将模型深度进行数量级的扩展。为此,他们研究了不稳定优化的原因,并且发现爆炸式模型更新是造成不稳定的罪魁祸首。基于这些观察,研究者在残差连接处引入了一个新的归一化函数 —— DEEPNORM,它在将模型更新限制为常数时具有理论上的合理性。
这一方法简单但高效,只需要改变几行代码即可。最终,该方法提升了 Transformer 模型的稳定性,并实现了将模型深度扩展到了 1000 多层。
此外,实验结果表明,DEEPNORM 能够将 Post-LN 的良好性能和 Pre-LN 的稳定训练高效结合起来。研究者提出的方法可以成为 Transformers 的首选替代方案,不仅适用于极其深(多于 1000 层)的模型,也适用于现有大规模模型。
值得指出的是,在大规模多语言机器翻译基准上,文中 32 亿参数量的 200 层模型(DeepNet)比 120 亿参数量的 48 层 SOTA 模型(即 Facebook AI 的 M2M 模型)实现了 5 BLEU 值提升。
有知乎网友疑问:就实现效果来说,1000 层是否有必要?论文作者之一董力(Li Dong)表示,1000 层更多地是为了探究上限,实际跑的过程中并非一定要上千层。此外,训练代码很快就会公开。
如下图 2 所示,使用 PostLN 实现基于 Transformer 的方法很简单。与 Post-LN 相比,DEEPNORM 在执行层归一化之前 up-scale 了残差连接。
![]()
图 2:(a) DEEPNORM 的伪代码,例如可以用其他标准初始化代替 Xavier 初始化 (Glorot and Bengio, 2010) ,其中 α 是一个常数。(b) 不同架构的 DEEPNORM 参数(N 层编码器,M 层解码器)。
此外,该研究还在初始化期间 down-scale 了参数。值得注意的是,该研究只扩展了前馈网络的权重,以及注意力层的值投影和输出投影。此外,残差连接和初始化的规模取决于图 2 中不同的架构。
该研究分析了深度 Transformer 不稳定的原因。
首先,研究者观察发现:更好的初始化方法可以让 Transformer 的训练更稳定。之前的工作(Zhang et al., 2019a; Huang et al., 2020; Xu et al., 2021)也证实了这一点。
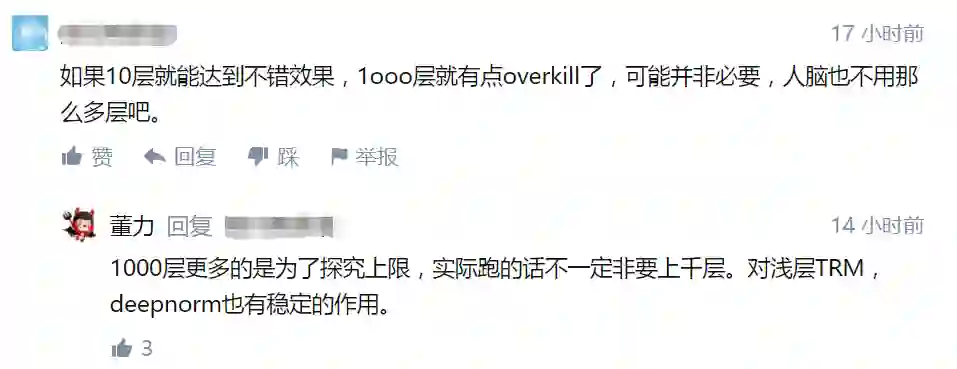
因此,研究者分析了有无适当初始化的 Post-LN 的训练过程。通过更好的初始化,在执行 Xavier 初始化后通过
![]() down-scale 第 l 层的权重。
例如,第 l 层 FFN 的输出投影
down-scale 第 l 层的权重。
例如,第 l 层 FFN 的输出投影
![]() 被初始化为
被初始化为
![]() 其中 d’是输入和输出维度的平
均值。
研究者将此模型命名为 Post-LN-init。
请注意,与之前的工作(Zhang et al., 2019a)不同, Post-LN-init 是缩窄了较低层的扩展而不是较高层。
研究者相信这种方法有助于将梯度扩展的影响与模型更新区分开来。
此外,Post-LN-init 与 Post-LN 具有相同的架构,从而消除了架构的影响。
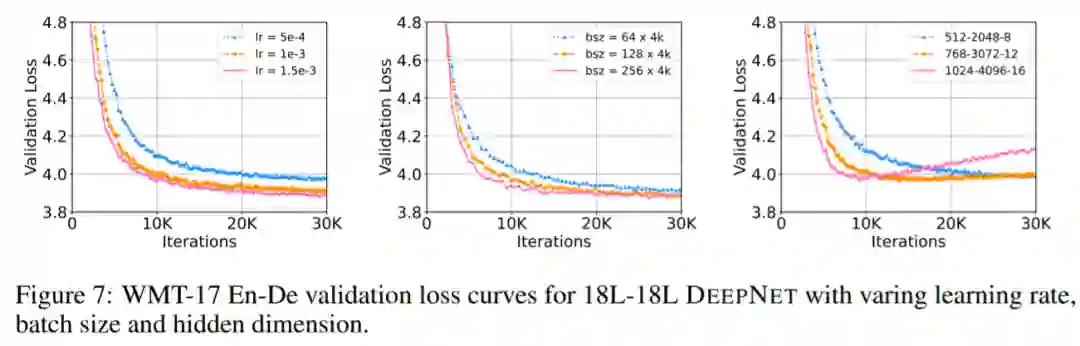
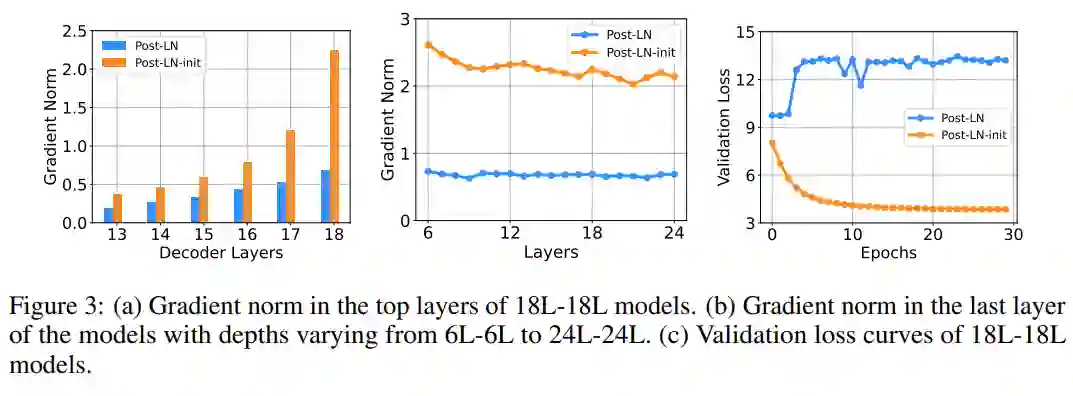
该研究在 IWSLT-14 De-En 机器翻译数据集上训练了 18L-18L Post-LN 和 18L-18L Post-LN-init。图 3 可视化了它们的梯度和验证损失曲线。如图 3 (c) 所示,Post-LN-init 收敛,而 Post-LN 没有。Post-LN-init 在最后几层中具有更大的梯度范数,尽管其权重已按比例缩小。此外,研究者可视化最后一个解码器层的梯度范数,模型深度从 6L-6L 到 24L-24L。
下图 3 显示,无论模型深度如何,最后一层 Post-LN-init 的梯度范数仍远大于 Post-LN 的梯度范数。得出的结论是,深层梯度爆炸不应该是 Post-LN 不稳定的根本原因,而模型更新的扩展往往可以解释这一点。
其中 d’是输入和输出维度的平
均值。
研究者将此模型命名为 Post-LN-init。
请注意,与之前的工作(Zhang et al., 2019a)不同, Post-LN-init 是缩窄了较低层的扩展而不是较高层。
研究者相信这种方法有助于将梯度扩展的影响与模型更新区分开来。
此外,Post-LN-init 与 Post-LN 具有相同的架构,从而消除了架构的影响。
该研究在 IWSLT-14 De-En 机器翻译数据集上训练了 18L-18L Post-LN 和 18L-18L Post-LN-init。图 3 可视化了它们的梯度和验证损失曲线。如图 3 (c) 所示,Post-LN-init 收敛,而 Post-LN 没有。Post-LN-init 在最后几层中具有更大的梯度范数,尽管其权重已按比例缩小。此外,研究者可视化最后一个解码器层的梯度范数,模型深度从 6L-6L 到 24L-24L。
下图 3 显示,无论模型深度如何,最后一层 Post-LN-init 的梯度范数仍远大于 Post-LN 的梯度范数。得出的结论是,深层梯度爆炸不应该是 Post-LN 不稳定的根本原因,而模型更新的扩展往往可以解释这一点。
![]()
然后研究者证明 Post-LN 的不稳定性来自一系列问题,包括梯度消失以及太大的模型更新。如图 4 (a) 所示,他们首先可视化模型更新的范数 ||ΔF|| 在训练的早期阶段:
其中 x 和 θ_i 分别代表输入和第 i 次更新后的模型参数。Post-LN 在训练一开始就有爆炸式的更新,然后很快就几乎没有更新了。这表明该模型已陷入虚假的局部最优。
warm-up 和更好的初始化都有助于缓解这个问题,使模型能够顺利更新。当更新爆炸时,LN 的输入会变大(见图 4 (b) 和图 4 (c))。根据 Xiong 等人 (2020) 的理论分析,通过 LN 的梯度大小与其输入的大小成反比:
相比于没有 warm-up 或正确初始化的情况,图 4 (b) 和图 4 (c) 表明 ||x|| 的明显大于
![]() 。
这解释了 Post-LN 训练中出现的梯度消失问题(见图 4 (d))。
。
这解释了 Post-LN 训练中出现的梯度消失问题(见图 4 (d))。
最重要的是,不稳定性始于训练开始时的大型模型更新。它使模型陷入糟糕的局部最优状态,这反过来又增加了每个 LN 的输入量。随着训练的继续,通过 LN 的梯度变得越来越小,从而导致严重的梯度消失,使得难以摆脱局部最优,并进一步破坏了优化的稳定性。相反,Post-LN-init 的更新相对较小,对 LN 的输入是稳定的。这减轻了梯度消失的问题,使优化更加稳定。
DeepNet:极深的 Transformer 模型
研究者首先介绍了极深的 Transformer 模型 ——DeepNet,该模型可以通过缓解爆炸式模型更新问题来稳定优化过程。
DeepNet 基于 Transformer 架构。与原版 Transformer 相比,DeepNet 在每个子层使用了新方法 DEEPNORM,而不是以往的 Post-LN。DEEPNORM 的公式如下所示。
![]()
其中,α 是一个常数,G_l (x_l , θ_l) 是参数为 θ_l 的第 l 个 Transformer 子层(即注意力或前馈网络)的函数。DeepNet 还将残差内部的权重 θ_l 扩展了 β。
接着,研究者提供了对 DeepNet 模型更新预期大小(expected magnitude)的估计。
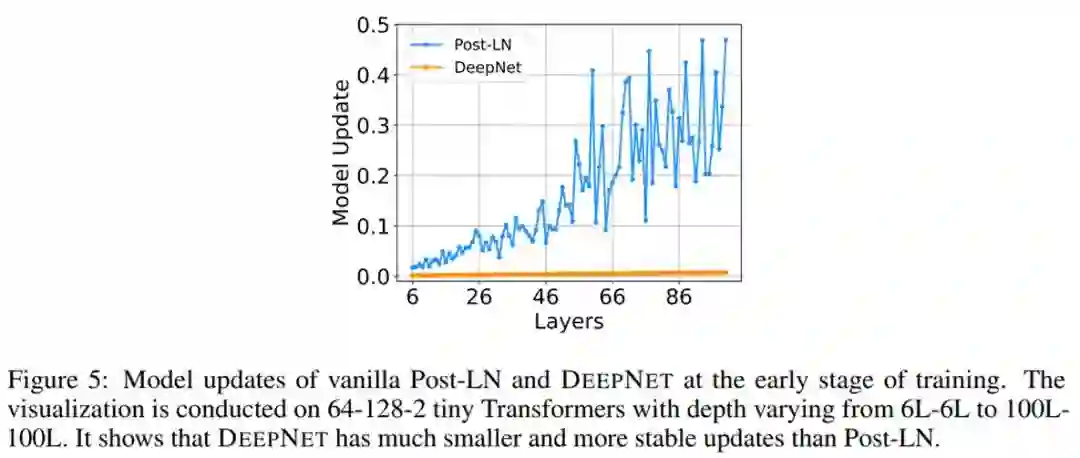
他们可视化了 IWSLT-14 De-En 翻译数据集上,Post-LN 和 DeepNet 在早期训练阶段的模型更新情况,如下图 5 所示。可以看到,相较于 Post-LN,DeepNet 的模型更新几乎保持恒定。
![]()
最后,研究者提供理论分析,以表明 DeepNet 的更新受到了 DEEPNORM 的常数限制。具体地,他们展示了 DeepNet 的预期模型更新受到了适当参数 α 和 β 的常数限制。研究者的分析基于 SGD 更新,并通过实证证明对 Adam 优化器效果很好。
研究者提供了对编码器 - 解码器架构的分析,它能够以相同的方式自然地扩展到仅编码器和仅解码器的模型。具体如下图所示,他们将模型更新的目标设定如下:
![]()
仅编码器(例如 BERT)和仅解码器(例如 GPT)架构的推导能够以相同的方式进行。研究者将步骤总结如下:
![]()
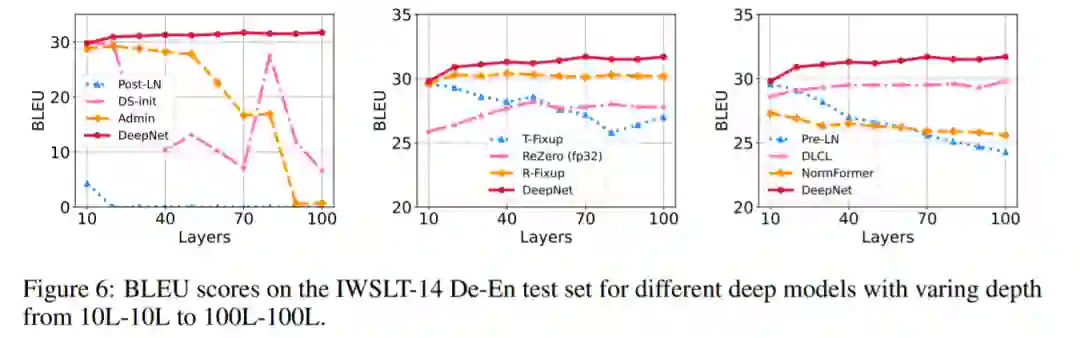
该研究验证了 DeepNet 在流行的机器翻译基准上的有效性,包括 IWSLT-14 德语 - 英语 (De-En) 数据集和 WMT-17 英语 - 德语 (En-De) 数据集。该研究将 DeepNet 与多个 SOTA 深度 Transformer 模型进行比较,包括 DLCL 、NormFormer 、ReZero 、R- Fixup 、T-Fixup 、DS-init 和 Admin。
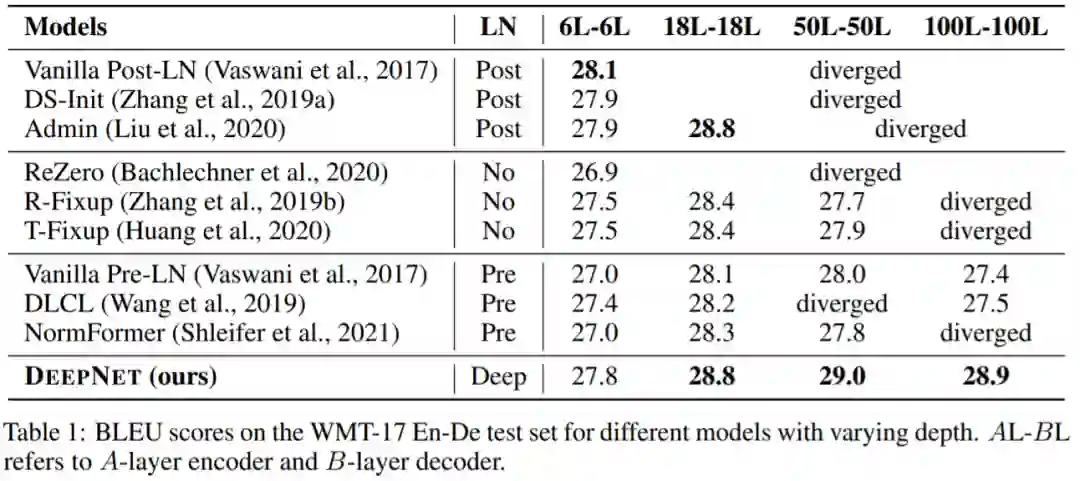
下表 1 报告了 WMT-17 En-De 翻译数据集上的基线和 DeepNet 的结果:
![]()
该研究首先使用 OPUS-100 语料库来评估模型。OPUS100 是一个以英语为中心的多语言语料库,涵盖 100 种语言,是从 OPUS 集合中随机抽取的。该研究将 DeepNet 扩展到 1,000 层,该模型有一个 500 层的编码器、 500 层的解码器、512 个隐藏大小、8 个注意力头和 2,048 维度的前馈层。
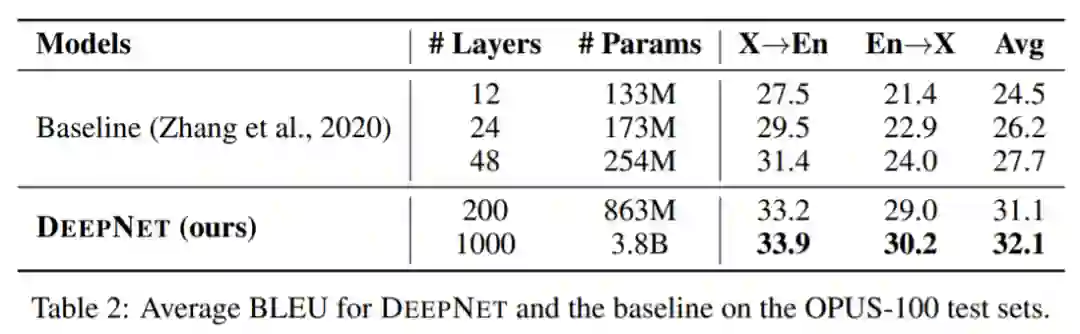
下表 2 总结了 DeepNet 和基线的结果。结果表明,增加网络深度可以显着提高 NMT 的翻译质量:48 层的模型比 12 层的模型平均获得 3.2 点的提高。DeepNet 可以成功地将深度扩展到 1,000 层,比基线提高 4.4 BLEU。值得注意的是,DeepNet 只训练了 4 个 epoch,并且在计算预算更多的情况下,性能可以进一步提高。
![]()
深度扩展规律:该研究在 OPUS100 数据集上训练具有 {12,20,100,200,1000} 层的 DeepNet,下图 8 显示了深度扩展曲线。与双语 NMT 相比,多语 NMT 从扩展模型深度受益更多。可以观察到多语 NMT 的 BLEU 值呈对数增长,规律可以写成:L (d) = A log (d) + B,其中 d 是深度,A, B 是关于其他超参数的常数。
![]()
更多数据和语言说明:为了探索 DeepNet 在多语 NMT 上的局限性,该研究随后使用 Schwenk 等人提出的 CCMatrix 扩展训练数据。此外,该研究还扩展了 CCAligned 、OPUS 和 Tatoeba 的数据,以涵盖 Flores101 评估集的所有语言。最终的数据由 102 种语言、1932 个方向和 12B 对句子组成。利用这些数据,该研究用 100 层编码器、100 层解码器、1024 个隐藏维度、16 个头、4096 个前馈层中间维度对 DeepNet 进行训练。
该研究将 DeepNet 与 SOTA 多语 NMT 模型 M2M-100 进行了比较。M2M-100 有一个 24 层的编码器、一个 24 层的解码器和 4,096 个隐藏大小,从而产生高达 12B 的参数。与 M2M-100 相比,DeepNet 深而窄,参数只有 3.2B。
在 M2M-100 之后,该研究在几个多语言翻译评估数据集上评估模型,包括 WMT、OPUS 、TED、 Flores。WMT 的语言对是以英语为中心的。包括英语在内的 10 种语言,其中大部分是高资源语言。对于 OPUS 数据集,该研究从包含 30 个评估对的测试集中选择非英语方向。TED 评估集有 28 种语言和 756 个方向,数据来自口语领域。Flores 数据集包含 102 种语言之间的所有翻译对。该研究使用涵盖 M2M-100 和 DeepNet 支持的语言的子集,产生 87 种语言和 7,482 个翻译方向。
下表 3 报告了结果,为了公平比较,该研究使用与基线相同的评估方法。结果表明 DeepNet 在所有评估数据集上的性能都明显优于 M2M-100,表明深化模型是提高 NMT 模型质量的一个非常有前景的方向。
![]()
时在中春,阳和方起——机器之心AI科技年会
机器之
心AI科技年会将于3月23日在北
京举办,在分享交流对人工智能的判断与思考外,更重要的是与读者、合作伙伴和好友们真实的见一面。
这是一次注重交流与见面的聚会,所以叫「年会」,没叫「大会」。
在这场年会上,有三个方向我们希望和大家分享:人工智能、AI for Science和智能汽车。
人工智能论坛关注高性能计算、联邦学习、系统机器学习、强化学习、CV与NLP发展、RISC-V等。
AI x Science论坛关注AI与蛋白质、生物计算、数学、物理、化学、新材料和神经科学等领域的交叉研究进展。
首席智行官大会关注智能汽车、汽车机器人、无人驾驶商业化、车规级芯片和无人物流等。
当然,按以往的惯例,我们还将邀请行业内最具代表性与专业的权威嘉宾带来他们的思考与判断。
欢迎大家点击「阅读原文」报名活动,「中春」见。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com



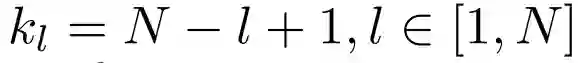 down-scale 第 l 层的权重。
例如,第 l 层 FFN 的输出投影
down-scale 第 l 层的权重。
例如,第 l 层 FFN 的输出投影
 被初始化为
被初始化为
 其中 d’是输入和输出维度的平
均值。
研究者将此模型命名为 Post-LN-init。
请注意,与之前的工作(Zhang et al., 2019a)不同, Post-LN-init 是缩窄了较低层的扩展而不是较高层。
研究者相信这种方法有助于将梯度扩展的影响与模型更新区分开来。
此外,Post-LN-init 与 Post-LN 具有相同的架构,从而消除了架构的影响。
其中 d’是输入和输出维度的平
均值。
研究者将此模型命名为 Post-LN-init。
请注意,与之前的工作(Zhang et al., 2019a)不同, Post-LN-init 是缩窄了较低层的扩展而不是较高层。
研究者相信这种方法有助于将梯度扩展的影响与模型更新区分开来。
此外,Post-LN-init 与 Post-LN 具有相同的架构,从而消除了架构的影响。

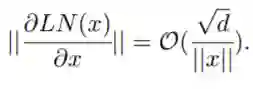
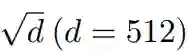 。
这解释了 Post-LN 训练中出现的梯度消失问题(见图 4 (d))。
。
这解释了 Post-LN 训练中出现的梯度消失问题(见图 4 (d))。