来源丨https://zhuanlan.zhihu.com/p/312443905
本文是对NeurPS2020 Oral中收录的一篇关于利用像素级别循环一致性来解决域适应语义分割问题论文的解读,这篇论文充分利用像素间的相似度来消除域差异,同时提高 feature 的辨别性。作者详细解读了文中列举语义分割的五个方法,让大家对该篇文章更深刻的理解。>>加入极市CV技术交流群,走在计算机视觉的最前沿
论文题目:Pixel-Level Cycle Association: A New Perspective for Domain Adaptive Semantic Segmentation
作者:Guoliang Kang, Yunchao Wei, Yi Yang, Yueting Zhuang, Alexander Hauptmann
论文链接:
https://papers.nips.cc/paper/2020/file/243be2818a23c980ad664f30f48e5d19-Paper.pdf
语义分割近年来获得非常大的进步和发展。但是当分割网络执行跨域 (cross-domain) 预测任务时,性能还远不能令人满意。例如,分割网络在易于获得标注的 synthetic data 上训练,在真实场景图片上进行分类,性能会发生大幅下跌。这种性能下降是由于目标域 (target domain)和 源域 (source domain) 图片的分布 (风格,布局,等) 不同所造成的的。域适应语义分割 (Domain Adaptive Semantic Segmentation) 就是利用带标注的源域数据和无标注的目标域数据来减小或者消除域漂移 (Domain shift) 带来的性能损失。
对于域适应语义分割,以前的方法通常基于 adversarial training,让图片或者 feature map 在不同 domain 之间变得不可区分。但是这些方法更多地关注全局或者整体的相似度,忽略了域内和域间的像素间关系,尽管能够在一定程度上消除域差异,其导致的 feature 并不具备非常好的辨别性,因而影响分类性能。这篇论文充分利用像素间的相似度来消除域差异,同时提高 feature 的辨别性。
1.Pixel-Level Cycle Association
![]() Pixel-Level Cycle Association
如上图所示,对于随机采样的 source 和 target 图片,我们首先建立他们像素级别的关联。我们利用像素级别的循环一致性 (pixel-level cycle consistency) 来建立这种关联。具体来说,对于任一 source 图片中的像素 S1,我们在 target 图片中选择与之相似度最高的像素 T。然后,对于选择的 target 像素 T,我们反过来选择与之最接近的 source 图片中的像素 S2。如果 S1 和 S2 属于同一个类别,我们则建立 S1--> T --> S2 的关联,否则,关联不成立。
对于建立起关联的像素,我们 contrastively 增强他们之间 (S1--> T 和 T--> S2) 的联系。我们通过 minimize 如下 loss 来实现这一目的 (
Pixel-Level Cycle Association
如上图所示,对于随机采样的 source 和 target 图片,我们首先建立他们像素级别的关联。我们利用像素级别的循环一致性 (pixel-level cycle consistency) 来建立这种关联。具体来说,对于任一 source 图片中的像素 S1,我们在 target 图片中选择与之相似度最高的像素 T。然后,对于选择的 target 像素 T,我们反过来选择与之最接近的 source 图片中的像素 S2。如果 S1 和 S2 属于同一个类别,我们则建立 S1--> T --> S2 的关联,否则,关联不成立。
对于建立起关联的像素,我们 contrastively 增强他们之间 (S1--> T 和 T--> S2) 的联系。我们通过 minimize 如下 loss 来实现这一目的 (
![]() 对应于 S1,
对应于 S1,
![]() 对应于 T,
对应于 T,
![]() 对应于 S2):
对应于 S2):
![]() 其中,
其中,
![]() 表示建立起循环关联的起始 source 像素点集合。
表示建立起循环关联的起始 source 像素点集合。
![]() 代表像素 feature 的相似度,这里采用 cosine similarity。
简而言之,就是让关联的 source 和 target 像素对的相似度相比于其他可能的像素对更高。
2. Gradient Diffusion via Spatial Aggregation
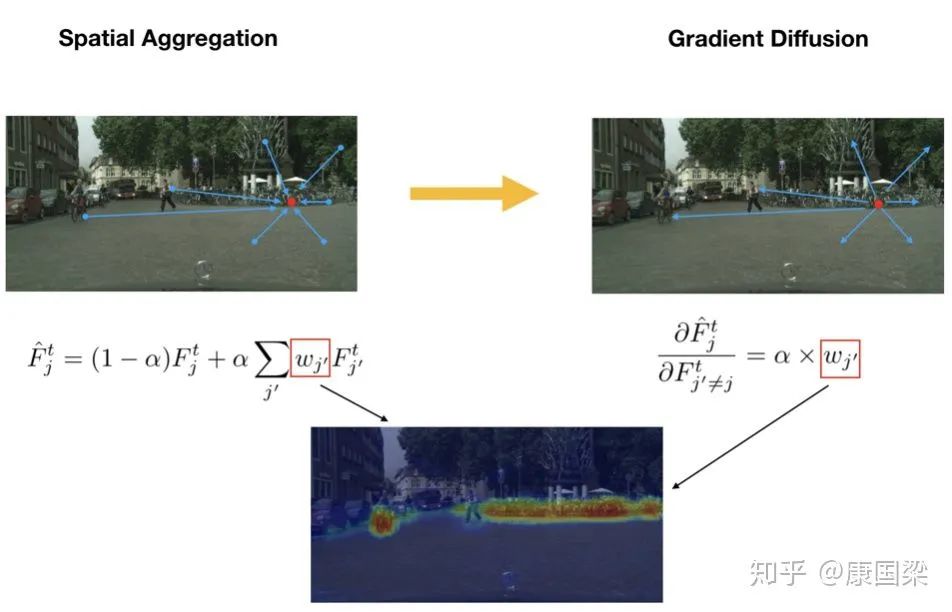
通过循环关联,我们可以建立 source 和 target 像素之间的联系。但是,通常只有部分 target 像素可以和 source 像素成功地建立起关联。原因有两个,一是循环关联倾向于选择最容易关联到的 target 像素;二是由于域差异,对于当前 source 图片的部分像素,target image 中在本质上可能就不存在应该与之关联的像素。为了给更多样化的 target 像素提供 supervision,对每个 target 像素点,我们采取 spatial aggregation 生成新的 feature,然后基于 aggregated feature 建立循环关联,如下图所示。通过这种方式,在 backward 的过程中,每个关联到的 target 像素点作为 seed 把传递给它的 gradients ”分发给“ 图片中的其他像素,其大小取决于其他像素点和 seed 像素点之间的相似度。
代表像素 feature 的相似度,这里采用 cosine similarity。
简而言之,就是让关联的 source 和 target 像素对的相似度相比于其他可能的像素对更高。
2. Gradient Diffusion via Spatial Aggregation
通过循环关联,我们可以建立 source 和 target 像素之间的联系。但是,通常只有部分 target 像素可以和 source 像素成功地建立起关联。原因有两个,一是循环关联倾向于选择最容易关联到的 target 像素;二是由于域差异,对于当前 source 图片的部分像素,target image 中在本质上可能就不存在应该与之关联的像素。为了给更多样化的 target 像素提供 supervision,对每个 target 像素点,我们采取 spatial aggregation 生成新的 feature,然后基于 aggregated feature 建立循环关联,如下图所示。通过这种方式,在 backward 的过程中,每个关联到的 target 像素点作为 seed 把传递给它的 gradients ”分发给“ 图片中的其他像素,其大小取决于其他像素点和 seed 像素点之间的相似度。
![]() 3. Multi-Level Cycle Association
除了在 feature 层建立和增强循环关联以外,我们还在分割网络预测的像素的 probability distribution 上建立循环关联。方法跟在 feature 上的做法一样。唯一不同的是,我们采取负的 Kullback-Leibler (KL) divergence 作为相似度度量, 即
3. Multi-Level Cycle Association
除了在 feature 层建立和增强循环关联以外,我们还在分割网络预测的像素的 probability distribution 上建立循环关联。方法跟在 feature 上的做法一样。唯一不同的是,我们采取负的 Kullback-Leibler (KL) divergence 作为相似度度量, 即
![]()
![]() 除了 association loss,我们最后的 objective 还包括 cross-entropy loss,lovász-softmax loss, adaptive 的 Linear Smooth Regularization (LSR) loss。其中,lovász-softmax loss 用来缓解 class imbalance 的影响,LSR 用来促进 smooth 的 prediction,以便于利用类间的关系建立起关联。
对于 Objective,我在这里不多做赘述,感兴趣的小伙伴可以去看我们的 paper。
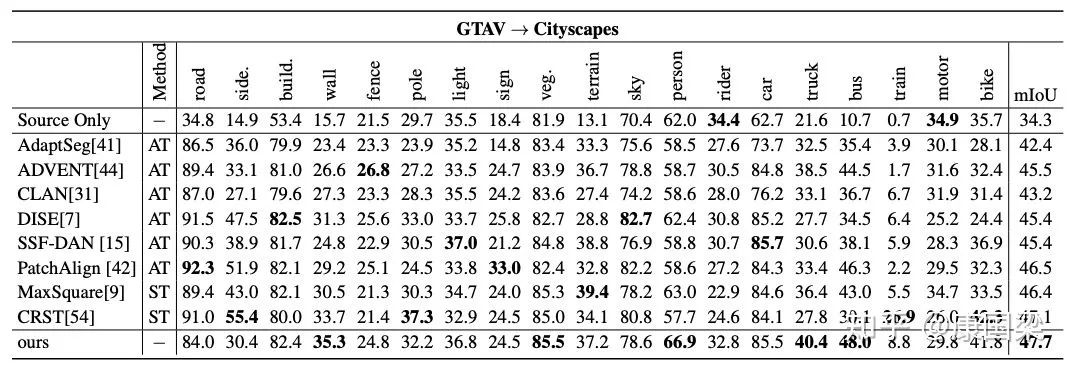
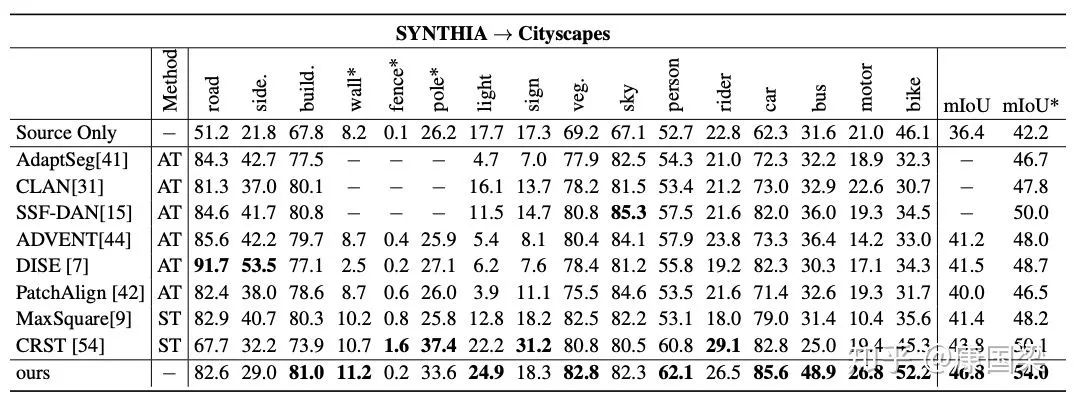
我们在 GTAV
除了 association loss,我们最后的 objective 还包括 cross-entropy loss,lovász-softmax loss, adaptive 的 Linear Smooth Regularization (LSR) loss。其中,lovász-softmax loss 用来缓解 class imbalance 的影响,LSR 用来促进 smooth 的 prediction,以便于利用类间的关系建立起关联。
对于 Objective,我在这里不多做赘述,感兴趣的小伙伴可以去看我们的 paper。
我们在 GTAV
![]() Cityscapes 和 SYNTHIA
Cityscapes 和 SYNTHIA
![]() Cityscapes 上验证了我们方法的有效性。
Cityscapes 上验证了我们方法的有效性。
![]() 其中,"Sim-PLCA" 指的是直接增强关联像素对相似度的方式,”PLCA w/o. SAGG" 指的是不采用 spatial aggregation 建立关联。
其中,"Sim-PLCA" 指的是直接增强关联像素对相似度的方式,”PLCA w/o. SAGG" 指的是不采用 spatial aggregation 建立关联。
![]()
![]() 详细的实验结果和分析,感兴趣的小伙伴可以去看我们的 paper。
本文提出的方法在跨域语义分割方面,取得了不错的结果。我们相信,本文的方法可以延伸到其他相关领域,比如说 weakly-supervised learning, unsupervised feature learning 等。
感谢大家耐心看完,欢迎批评指正,喜欢的话可以点赞分享 ~
详细的实验结果和分析,感兴趣的小伙伴可以去看我们的 paper。
本文提出的方法在跨域语义分割方面,取得了不错的结果。我们相信,本文的方法可以延伸到其他相关领域,比如说 weakly-supervised learning, unsupervised feature learning 等。
感谢大家耐心看完,欢迎批评指正,喜欢的话可以点赞分享 ~
推荐阅读
![]()
添加极市小助手微信(ID : cvmart2),备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳),即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群:每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~
![]()


 对应于 S1,
对应于 S1,
 对应于 T,
对应于 T,
 对应于 S2):
对应于 S2):
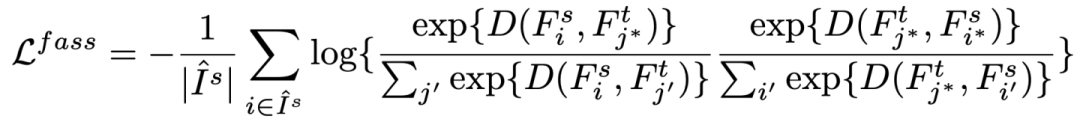
 表示建立起循环关联的起始 source 像素点集合。
表示建立起循环关联的起始 source 像素点集合。
 代表像素 feature 的相似度,这里采用 cosine similarity。
代表像素 feature 的相似度,这里采用 cosine similarity。
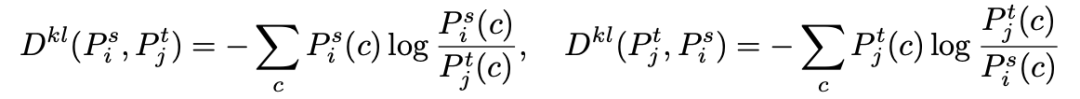
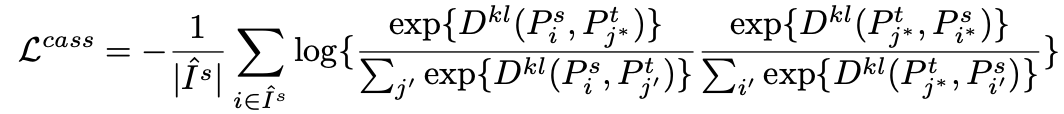
 Cityscapes 和 SYNTHIA
Cityscapes 和 SYNTHIA