AAAI 2020 论文解读:关于生成模型的那些事
提到生成模型,每个人首先要考虑的问题应该都是这两个——生成什么,如何生成。本文介绍的三篇论文就包含了三种生成模型(GNN、RL、VAE,即怎么生成),同时也介绍了这些生成模型各自当前的应用场景(场景图生成、序列生成、任务型对话生成,即生成什么)。
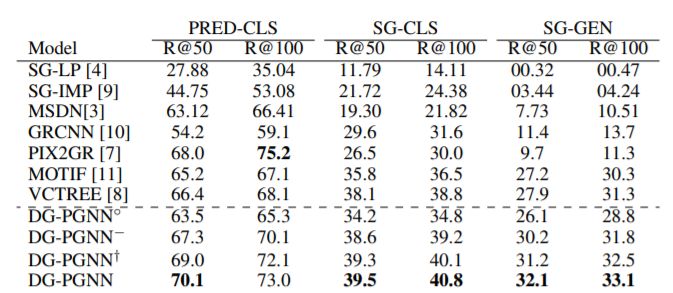
Probabilistic Graph Neural Network(PGNN):Deep Generative Probabilistic Graph Neural Networks for Scene Graph Generation
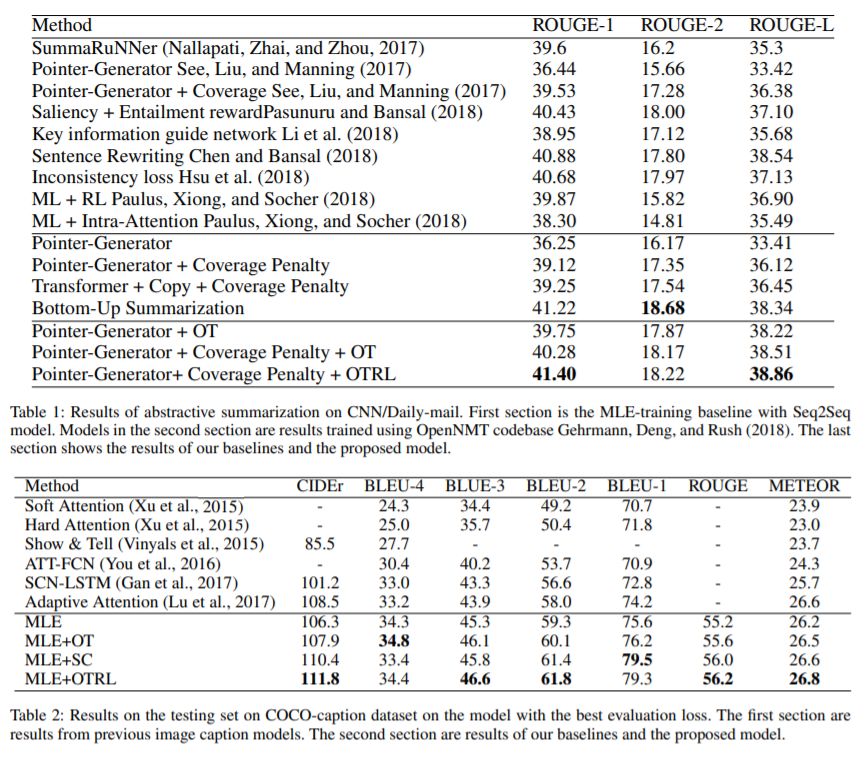
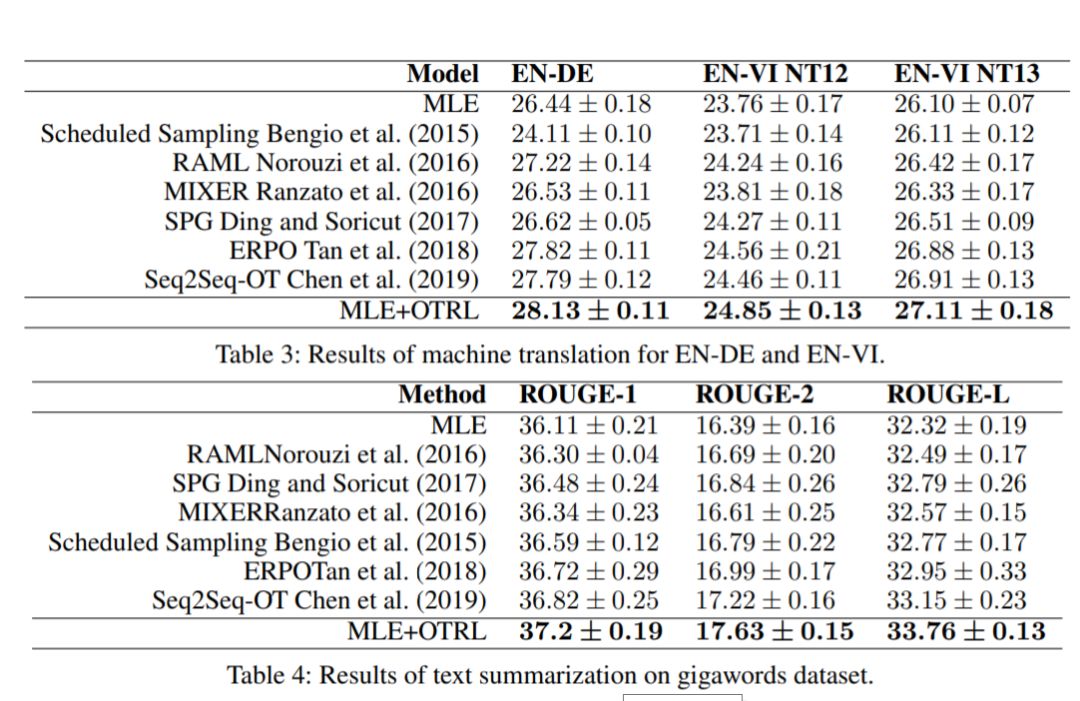
Reinforcement Learning(RL): Sequence Generation with Optimal-Transport-Enhanced Reinforcement Learning
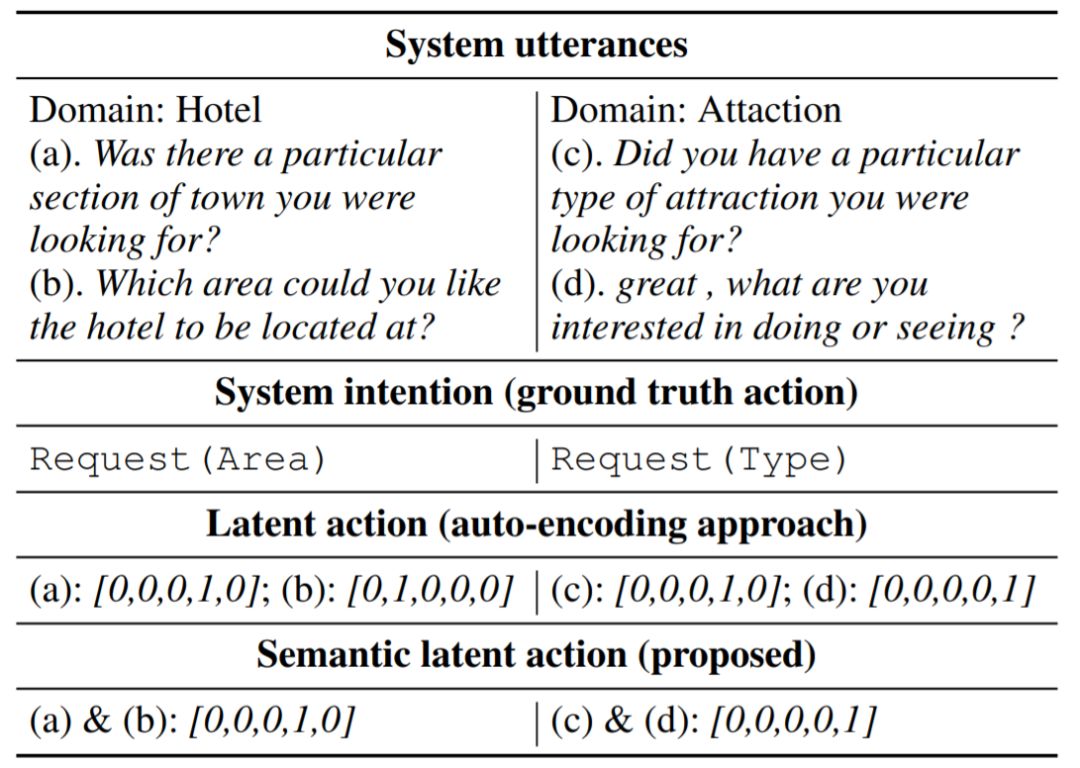
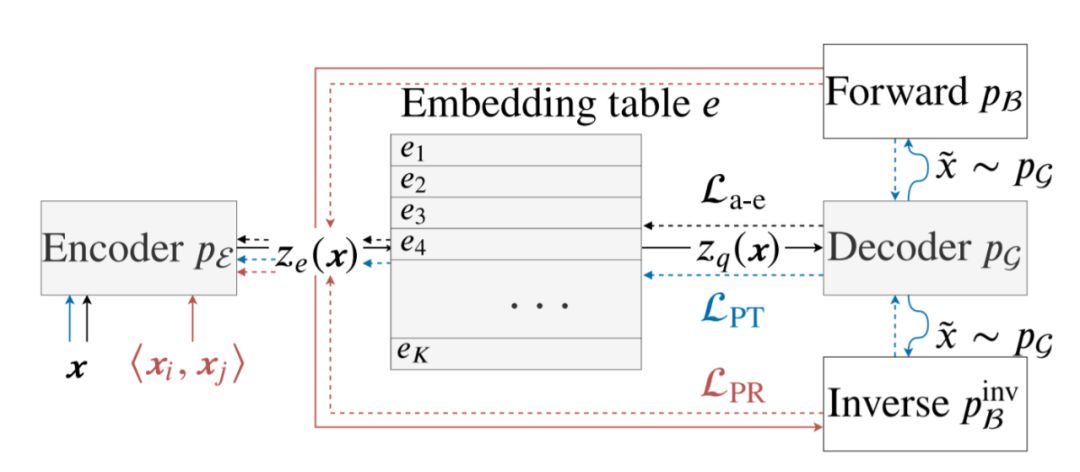
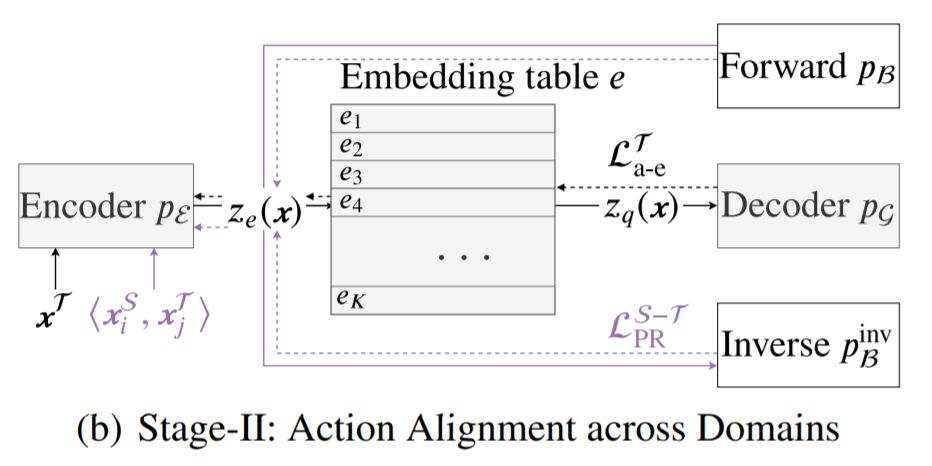
Action Learning: MALA: Cross-Domain Dialogue Generation with Action Learning

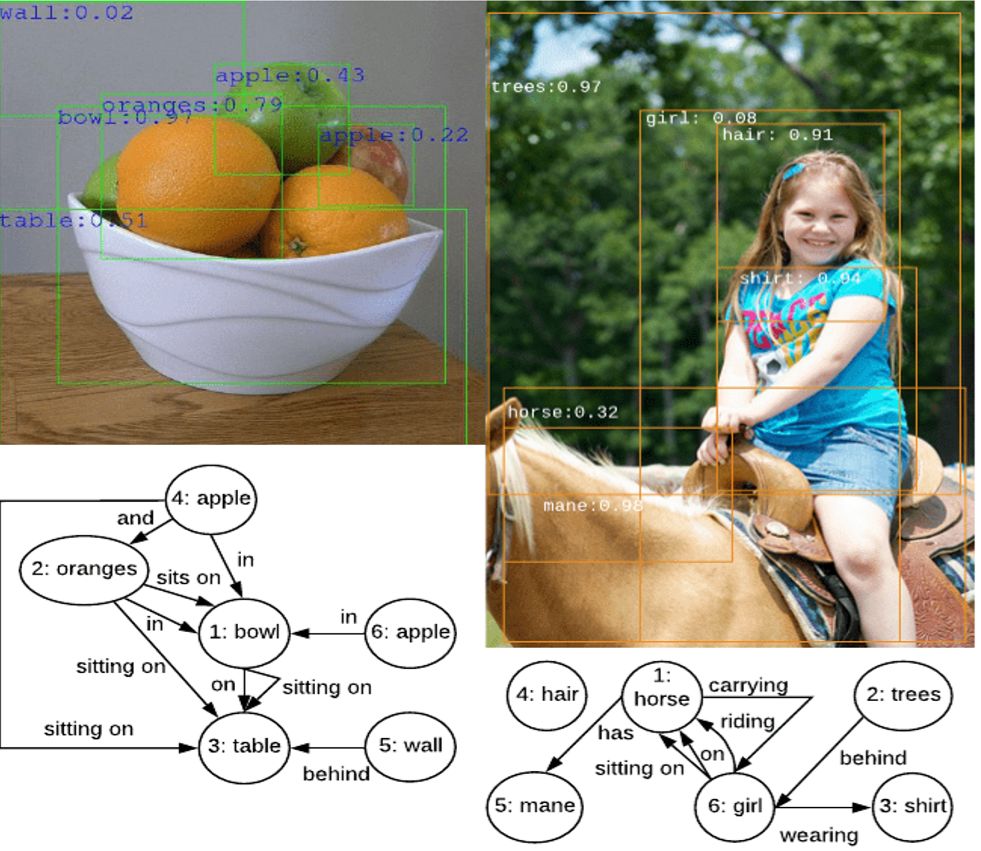
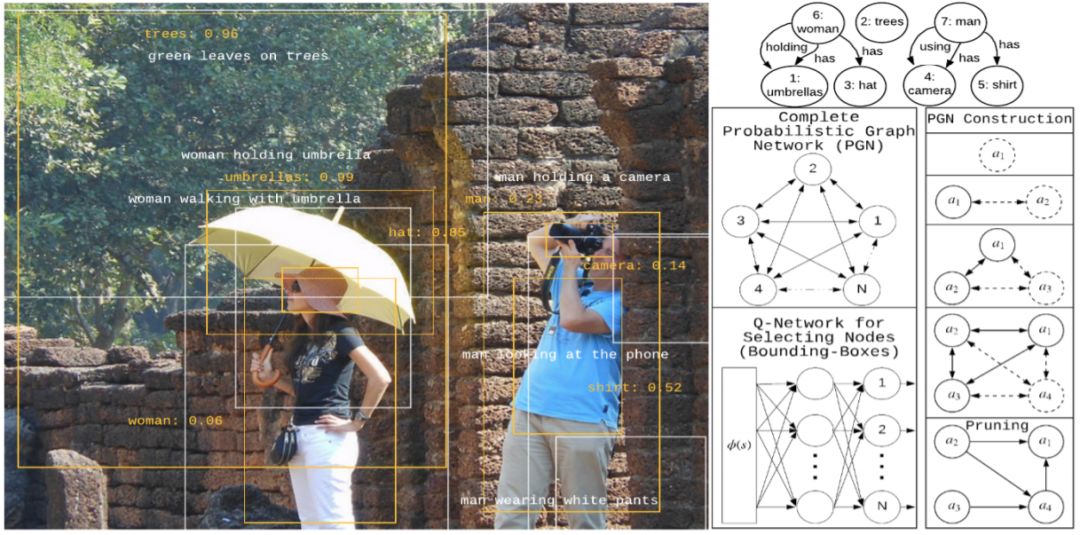
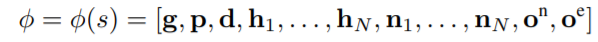
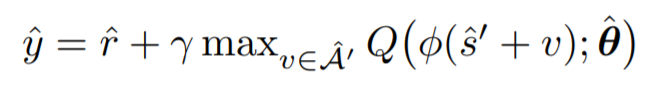
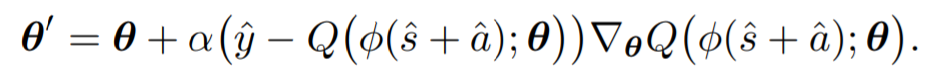

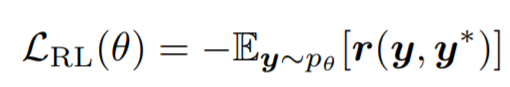
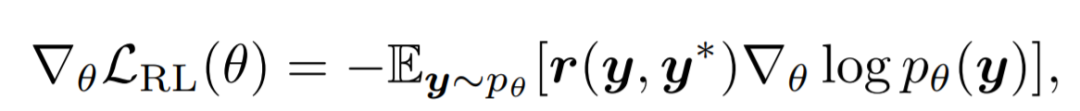
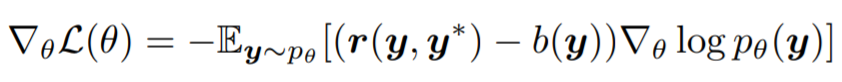
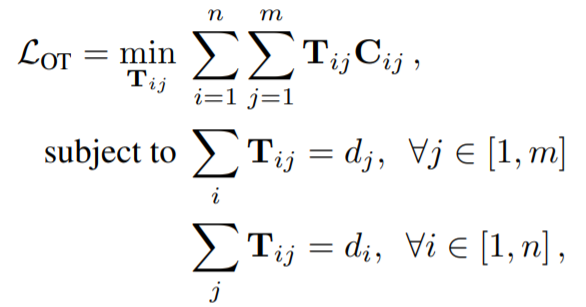
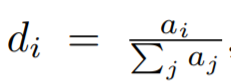

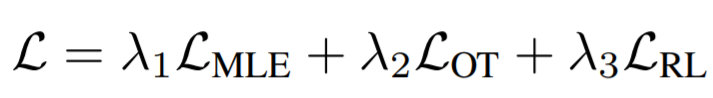

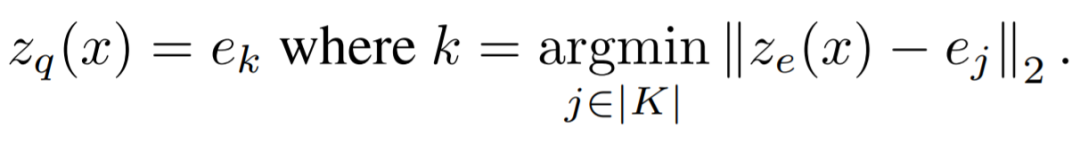
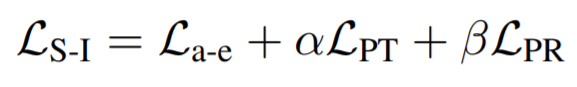
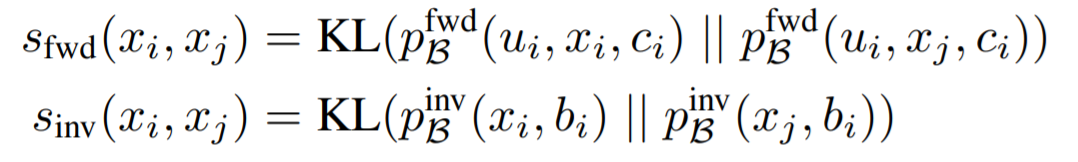
登录查看更多
相关内容
Arxiv
9+阅读 · 2018年4月22日




相关VIP内容
相关资讯
相关论文
Arxiv
9+阅读 · 2018年4月22日