微软小冰首席科学家武威解读 EMNLP 论文:聊天机器人的深度学习模型

AI 科技评论按:2018 年度 EMNLP 大会上,微软小冰首席科学家武威和北京大学助理教授严睿就聊天机器人近年来的研究成果作了全面总结,并对未来聊天机器人的研究趋势进行了展望。
近日,在雷锋网(公众号:雷锋网) AI 研习社公开课上,微软小冰首席科学家武威就为大家带来了其在 EMNLP 大会上分享的精华部分。
公开课回放视频地址:
http://www.mooc.ai/open/course/606?=wuwei
分享嘉宾:
武威,微软小冰首席科学家,主要研究方向为自然人机对话、自然语言处理、机器学习以及信息检索;为微软小冰第二代到第六代对话引擎贡献了核心算法,并带领团队研发了第五代小冰的生成模型以及第六代小冰的共感模型。
分享主题:聊天机器人的深度学习模型
分享提纲:
1. 引言
2. 深度学习基本概念
3. 基于检索的聊天机器人
4. 基于生成式的聊天机器人
5. 未来趋势和结论
雷锋网 AI 研习社将其分享内容整理如下:
引言
本次公开课主要分享我和北京大学的严睿老师在 2018 年度 EMNLP 大会上做 tutorial 分享的精华内容。
最近聊天机器人很火。我进行了一个小实验,在 google scholar 的 advanced search 以「聊天机器人」为关键词搜索文章——要求文章的题目必须包含「chatbot」这个单词,经过统计,发现从 2015-2017 年,标题包含「chatbot」这个单词的文章数量呈指数型增长。当然,这个实验是不全面的,一些标题包含「conversation model」的文章虽然标题中没有「chatbot」,但是也是关于「chatbot」的文章。因此,我们可以想象得到它在学术界的火热程度。
另外在工业界,亚马逊和 Facebook 都举办了一些比赛,例如亚马逊就举办了两届 The Alexa Prize,而 Facebook 也在 NIPS 上举办了两次关于 chatbot 的比赛,这些比赛都受到了很多人的关注。同时,大公司基本上都有自己的聊天机器人产品,例如微软有小冰,苹果有 Siri 等等。

我们认为构建聊天机器人引擎有三层:
最底层的是 General Chat;
再上一层是 Informational Chat,涉及到人和机器人进行信息交换、机器人为人提供一些信息,比如问答;
最上面一层是 Task,即机器人通过对话的方式帮助人完成一些任务。
这里我举一个例子:
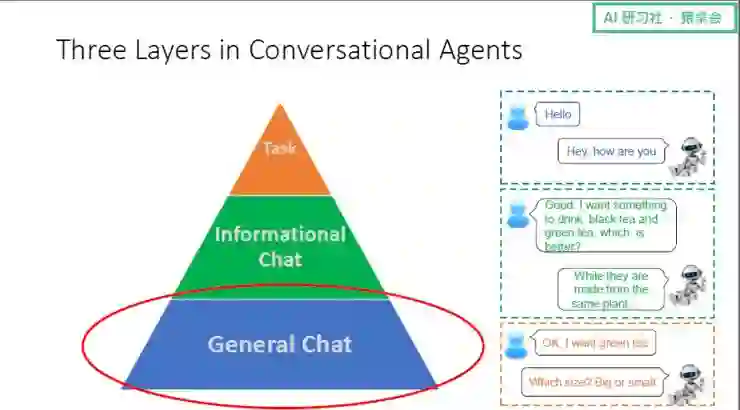
(关于该案例的具体讲解,请回看视频 00: 03:20 处)
今天我们主要讲 General Chat,这就要提到微软小冰在整个业界所产生的影响力。小冰 2014 年在中国发布,之后便以一年落地一个国家的节奏,先后在日本、美国、印度以及印度尼西亚发布。现在,它在全球拥有 6 亿+用户,产生的对话数量超过 3 百亿。
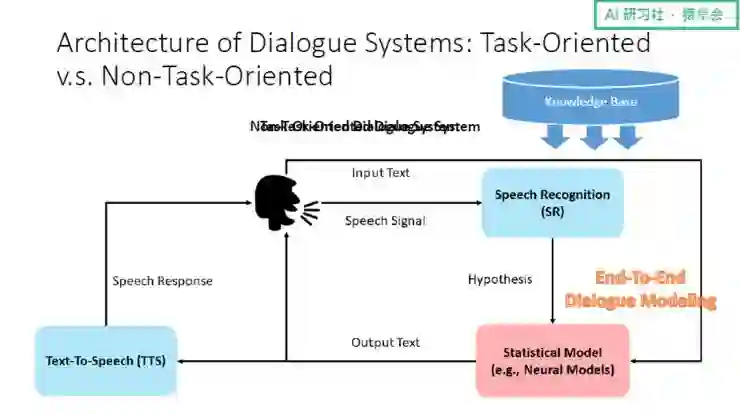
小冰背后最核心的部分就是对话引擎。传统的对话引擎是基于任务导向的,它分为以下几个模块:
第一个是人与机器产生对话后的语音识别模块;
第二个是语言理解模块,该模块对谈话的意图、话题等进行分析;
第三个是对话管理模块,语言理解模块产生的分析输入到对话管理模块后,该模块根据语言理解模块的理解产生一个决策,决定机器人下一步采取怎样的行为;
第四个是语言生成模块,该模块根据所有的信息合成出一个回复,并将回复传送到 TTS 这个模块中,最终变成语言返还给用户。
当然整个过程中也需要跟 Knowledge base 进行互动:如果用户提供的信息充分,对话引擎则需要从 Knowledge base 中为用户找出答案;如果不充分,则需要向用户再次发问获得更多信息。
随着大数据时代的到来和深度学习技术的发展,对话引擎也发生了改变:语言理解、对话管理以及语言生成模块简化成统计模型,可支持端到端的训练。这个统计模型就是我们今天重点介绍的内容。
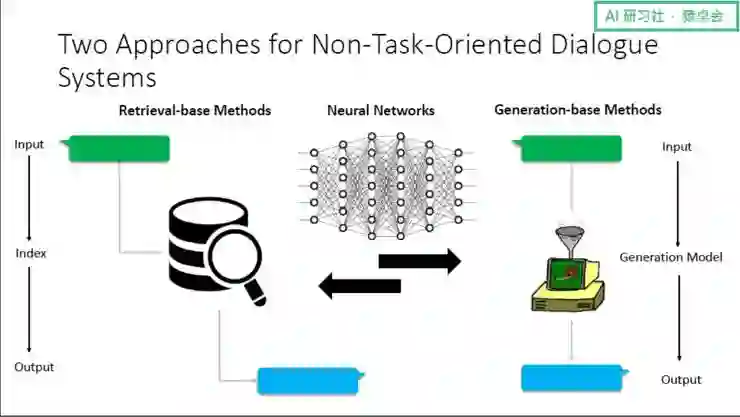
构建非任务导向或者说 General Chat 的对话引擎,现在学术界或业界一般有两种基本的方法:
第一种是基于检索的方法:用户进行输入后,系统通过查询 index,找到所有可能的回复并从中选出最合适的回复返回给用户;
第二种是基于生成式的方法:用户进行输入后,系统通过机器学习的办法合成出一个回复并返回给用户。
不管哪种方法,神经网络都在其中起到了非常重要的作用。
深度学习基本概念
在介绍这两种方法之前,我先给大家简单介绍一下深度学习在 NLP 中的一些基本知识。
Word Embedding:深度学习在 NLP 中应用的基石。

Word Embedding 最经典的方法就是 Word2vec,它有两个模型:
第一个是 Continuous Bag-of-Words(CBOW)
第二个是 Skip-gram

Word Embedding 另一个比较经典的方法是 GloVe:

但是 Word2vec 和 GloVe 都无法处理好词的变形问题,例如英文中的 study、studies 以及 studied 都表示一个意思,但是这两种方法都将这些相同意思不同形态的词当成不同的词,这就会带来信息的冗余或者丢失。对此,Facebook 研究院提出了 FastText 的模型,目的就是对词的变形进行建模:

下面我们对 Word2vec、GloVe 以及 FastText 进行一个对比:
在 NLP 具体任务中应用的效果来看:效果最差的是 CBOW;其次是 Skip-gram(GloVe 跟 Skip-gram 差不多);效果最好的是 FastText。其中,FastText 能很好地处理 OOV 问题,并能很好地对词的变形进行建模,对词变形非常丰富的德语、西班牙语等语言都非常有效;
从效率(训练时间)上来看:CBOW 的效率是最高的,其次是 GloVe;之后是 Skip-gram;而最低的是 FastText。
自然语言处理中的句子可以视为一个字符串,句子的表示可以通词表示来实现,一般来说有两种方法:
一种是基于卷积神经网络(CNN)的方法;

另一种方法是基于循环神经网络(RNN)的方法。

(关于深度学习在 NLP 中这几个基本概念的具体讲解,请回看视频 00:09:00-00:25:05 处)
基于检索的聊天机器人
快速讲了一下这些基础知识后,我们进入基于检索的聊天机器人的构建部分的讲解。
下图给出了基于检索的聊天机器人的架构,该架构分为离线和在线两部分:
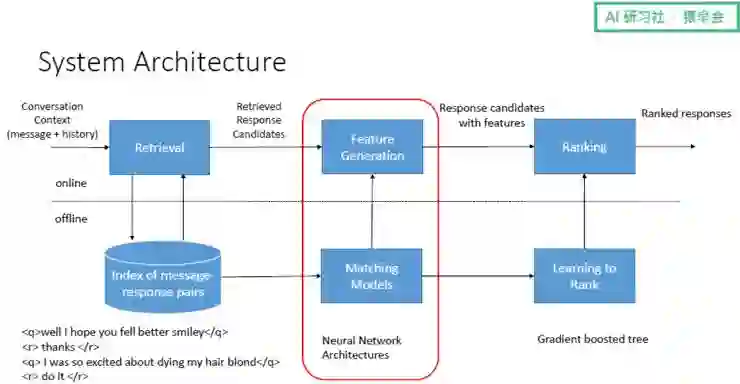
离线部分:首先需要准备存储了大量人机交互数据的 Index;之后 Matching Model 能够评估输入与输出的相似度,并给出一个相似度的评分——Matching Model 越多,相似度得分个数也越多,其可以评估输出对于输入来说是否是一个比较合适的输出;然后这些得分通过分类器(设置一个预值,大于预值的都认为是可作为选择的输出),合成一个最终得分列表,并由排序模型对得分进行排序,选择排在最前面的输出作为对当前输入的回复。
在线部分:有了这些离线准备,我们可以将当前的上下文输入到存储了大量人机交互数据的 Index 中进行检索,并检索出一些候选回复;接着,回复候选和当前上下文一起通过 Matching Model 来进行打分,每一个得分都作为一个 Feature,每一个候选回复和上下文因而就产生了 Feature Vector;之后,这些 Feature Vector 通过排序模型或者分类器变成最后的得分;最终,排序模型对得分进行排序,并从排序列表中选出合适的回复。
其中,基于检索的聊天机器人很大程度上借鉴了搜索引擎的成果,比如 learning to rank,其新的地方主要在于——当给定上下文和候选回复时,通过建立一个 Matching Model 来度量候选回复是否能够作为上下文的回复。目前,检索是聊天机器人领域的一个研究重点,而怎样通过神经网络的方法来构建 Matching Model,则是检索中的重点。
构建 Matching Model 一般面临两个问题:
一个问题是如何设计 Matching Model 的结构,要求该结构能很好地对上下文的语法、语义进行建模,并很好地抓住上下文和候选回复之间的语义关系;
第二个问题是有了这个结构后,怎样在没有标注数据、上下文和候选回复有很多种表示的情况下,从数据中学习这个结构。
后面我将就这两个问题,讲一下目前的研究状况。
目前的 Matching Model 大致可以归类为两个框架:
第一个是Ⅰ 型框架,基于句子的表示来构建上下文和候选回复之间的相似度得分;
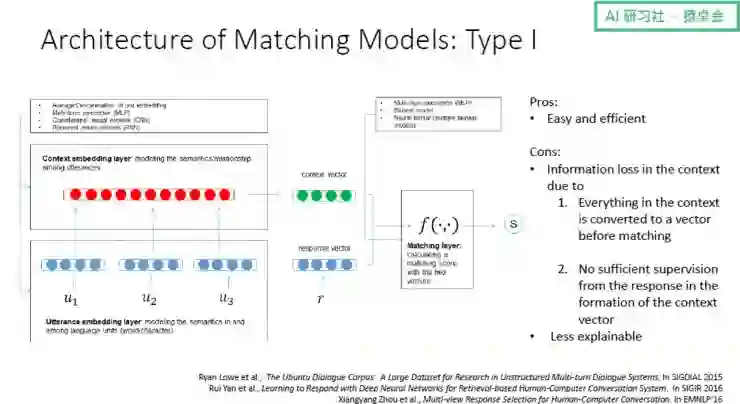
Ⅰ 型框架有其优势,比如简单、容易实现,在线上系统中也比较高效;不过该框架也存在信息丢失、不那么容易解释等问题,而正是这些问题促使提出了第二个 Matching Model 框架——Ⅱ 型框架。
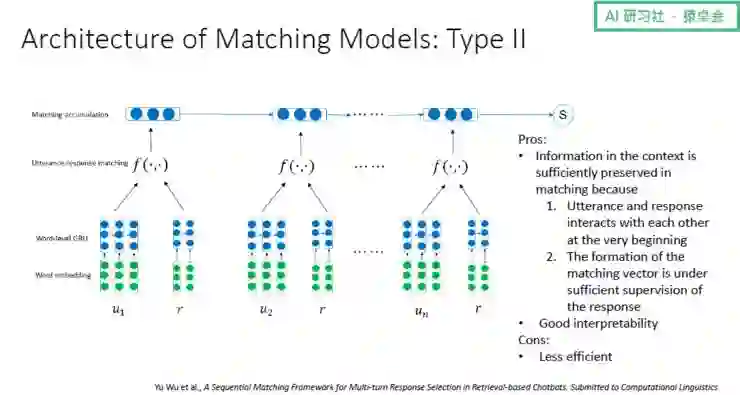
Ⅱ 型框架的想法是:既然信息丢失源于上下文在碰到候选回复前就已经被压缩成了一个小向量,不如就让上下文中的每一句话一开始就与候选回复进行充分交互,之后将交互信息提取出来变成匹配向量,然后用 RNN 在匹配向量这个级别上对句子关系进行建模,最终产生一个匹配得分。
Ⅱ 型框架的优势在于可以将上下文信息充分保存在匹配模型中,同时有很好的可解释性;不过该框架也存在计算复杂度较高等缺点。
(关于这两个框架及其应用案例的具体讲解,请回看视频 00:29:50—00:45:10 处)
下面要讲的是我们即将要在 WSDM 2019 上发表的新工作。这项工作的想法是:既然我们对 Ⅰ 型和 Ⅱ 型已经进行了很好的研究,而深度学习实质上是表示学习,因此是否能优化匹配模型的表示来进一步提升模型的表现呢?对此,我们的基本想法是:当拥有非常多的表示时,怎样利用这么多的表示来产生一个表现更好的模型。结果证明,将这些表示进行合并(fuse)是有用的,但是在实现方式上是有讲究的:
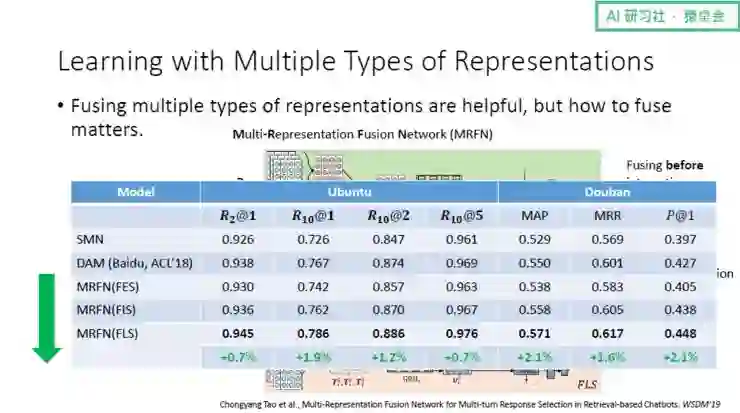
(对于这项新工作的具体讲解,请回看视频 00:46:40 处)
简单总结一下基于检索的聊天机器人:
基于检索的聊天机器人本质上是重用已有的人的回复,来对人的新的输入进行回复;
匹配模型实际上在基于检索的方法中起到了至关重要的作用,深度学习时代大家偏向于关注怎样设计出一个好的模型,但我们认为学习方法至少是与模型设计同等重要的;
基于检索的方法是当前构建聊天机器人的主流方法。
基于生成式的聊天机器人
最后简单介绍一下生成式的方法。
用户输入后,系统通过自然语言生成的方法合成一个回复,即机器人自己生成一个回复作为输出。生成式方法的一个基本的模型就是 Encoder-Attention-Decoder 的结构,该结构实际上是借用了机器翻译的思想。
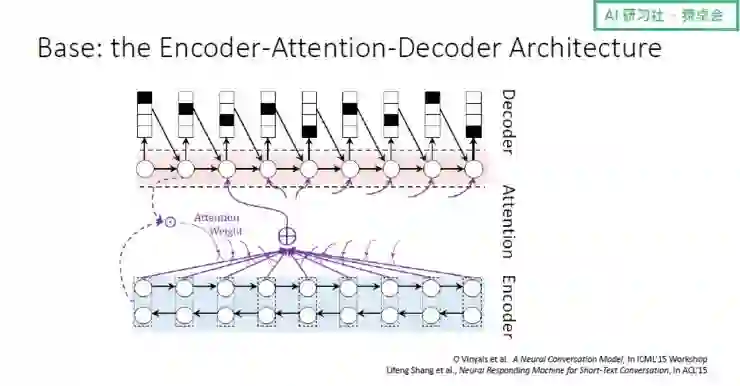
不过,当我们将机器翻译的基本架构借入到对话系统中,我们发现了一些问题:
第一,这个方法非常倾向于记住数据中的「高频回复」,例如「我知道了」「我也是」,然而这些「万能回复」实际上是没什么意义的,会导致整个对话无法进行下去;
第二,机器翻译中一般翻译单句,但对话上下文是有一些结构的,比如层次结构——词到句子到上下文;与此同时,词和句子在上下文中有很多冗余信息,只有一小部分是有用的;
第三,这是在实践中发现的一个问题:生成式模型在对回复一个一个进行解码时,速度非常慢。怎样提高其效率就成为了我们重点关注的一个问题。
生成式对话也是当前非常受关注的主题,现在也有很多相关工作,不过今天由于时间有限,我只介绍这三个问题。
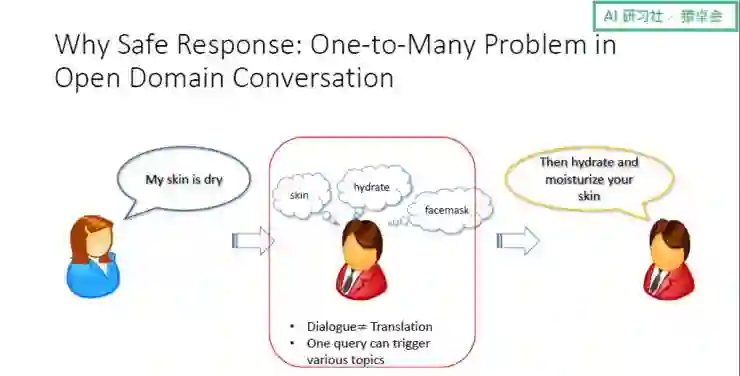
那么,为什么会产生「万能回复」?实际上,对话是一个「一对多」的问题,即一个输入可能有非常多的回复,整个对话过程也不像机器翻译那样直来直去,机器人会根据对话产生联想,再根据这些联想合成回复。
基于这个想法,我们使用神经网络进行建模,在 Encoder、Decode 的架构上,加入了一个 Topic Attention。
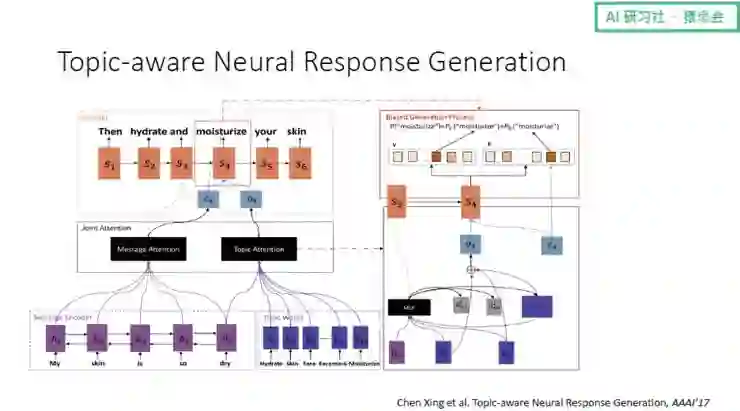
(关于这一模型的具体讲解,请回看视频 00:56:25 处)
在 AAAI 2018 的一项工作中,我们对上下文进行建模。想法是:既然上下文具有层次结构,那我们就分别用一个句子级别的 GRU 和一个词级别的 GRU 对词和句子间的序列关系进行建模;同时在生成过程中,还有一个句子级别的 Attention 和一个词级别的 Attention,分别考虑哪些句子中的哪些词、整个上下文中哪些句子是比较重要的。除了效果非常好,这个模型还有非常强的可解释性。
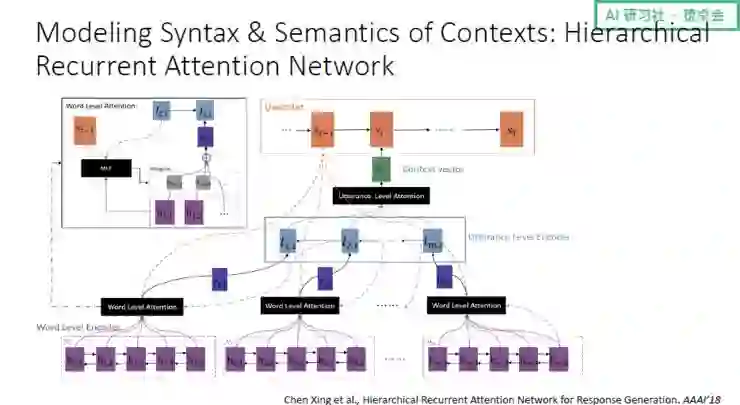
(关于 AAAI 2018 这项对上下文进行建模的工作的具体讲解,请回看视频 00:58:00 处)
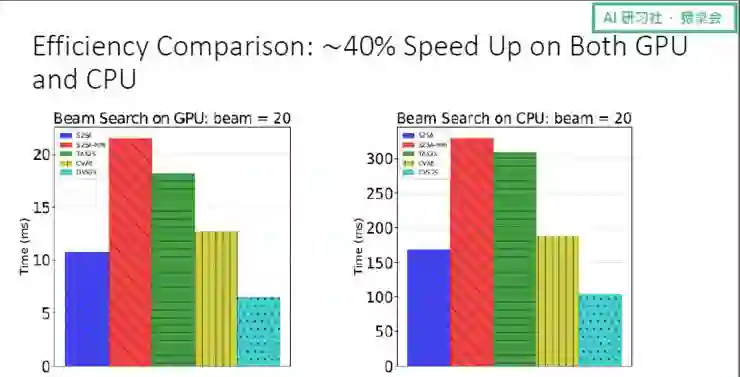
最后我们谈谈在对话中怎么解决解码效率的问题。我们观察到系统解码效率低的原因在于,其每预测一个词都需要扫一遍整个词表,但实际可以用来对输入进行回复的只有一小部分。

对此,我们的想法是,先用过滤器将大部分可能无关的词过滤掉,在生成回复中只考虑剩下的一小部分词,从而将一个静态词表变成了一个动态词表,针对每一个输入,词表都不一样。
我们在 CPU 和 GPU 上都测试了这个模型,发现效率都有 40% 左右的提升。
在这里介绍一下生成模型在小冰(印度尼西亚)中的实际应用:

(关于解决解码效率问题以及生成模型在小冰(印度尼西亚)中的实际应用的具体讲解,请回看视频 1:00:00 处)
最后对基于检索和基于生成式的方法进行一个对比:
基于检索的方法的优点包括能找出很有趣、多样性很高的回复;大量借鉴了搜索引擎上的方法,可以直接采用搜索引擎上的方法(learning to rank)来进行评估。其缺点在于对话的质量完全取决与 index 的质量。
基于生成式的方法的优点包括支持端到端的学习;由于不受到 Index 的束缚,生成模型可以进行更多的变形,比如将风格、情感引入到生成式对话中,对生成式对话进行控制等。不过其缺陷也很明显:一是该方法不太好评估,现在的评估方法依赖于大量标注,但各自的标注不一,针对目前的生成式文章也无法判断谁提出的方法更好一些;二是相对于检索模型,它的多样性还是要差一些。
总结
在聊天机器人时代,对话引擎扮演着非常重要的角色,目前其两个主流的方法就是基于检索和基于生成式的方法,现在针对二者的研究也非常多。然而实现真正的人机对话,我们还有很长的路要走。
分享结束后,嘉宾还对听众的提问进行了解答,大家可回看视频 1:04:35。
以上就是本期嘉宾的全部分享内容。更多公开课视频请到雷锋网 AI 研习社社区(http://ai.yanxishe.com/)观看。关注微信公众号:AI 研习社(okweiwu),可获取最新公开课直播时间预告。
【AI求职百题斩 - 每日一题】
来看看今天的题目吧!

想知道正确答案?
点击今日推文【第4条】或 在公众号回复“0108挑战”即可答题获取!




