探索无限大的神经网络

作者 | Simon Du、Wei Hu
编译 | 杨晓凡
平时难住我们的是,有再多资源也承载不了无限大的网络。但其实可以证明无限宽的网络和核方法是等效的,给了我们揭开无限宽网络面纱的机会。另外我们还有一些额外的收获——原来核方法和神经网络也沾亲带故。
被推翻的「复杂度甜点」
机器学习界有一条流传已久的规矩:你需要在模型的训练误差和泛化能力之间谨慎地做出取舍。衡量泛化能力,有一个很便捷的指标是看看模型在训练集和测试集上的误差相差多大,那么,一个较小的模型通常很难在训练集上做到很小的训练误差,不过这个误差和测试集上的测试误差在同一水平;换用更大的模型以后一般都可以得到更小的训练误差,但是测试误差往往会比训练误差大不少;也就是说,太大、太小的模型都无法得到较好的测试误差。所以大家总结,要寻找模型复杂度的甜点(「sweet spot」),复杂度要足够大,能够达到足够低的训练误差;复杂度也不能太大,避免测试误差比训练误差大太多。下面这个经典的 U 型曲线就是根据这个理论绘制的 —— 测试误差随着模型复杂度的增加而先减小、再增大。
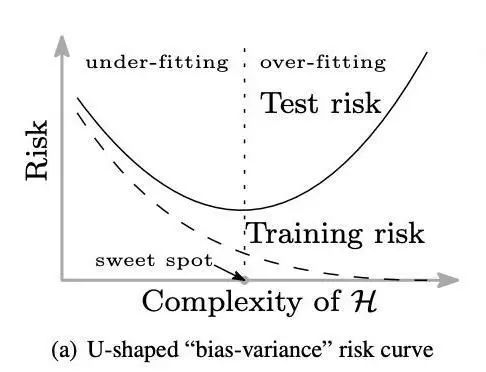
不过,随着深度神经网络之类的高度复杂、高度过参数化(over-parameterized)的模型得到广泛研究和使用,大家发现它们经常可以在训练数据集上做到接近 0 的误差,然后还能在测试数据上发挥出令人惊讶地好的表现,如今的网络大小也就随着越来越大。Belkin 等人(https://arxiv.org/abs/1812.11118 )用一种新的双峰曲线描述了这个现象,他们在经典的 U 型曲线的右边继续延伸,描绘出:当模型的复杂度继续增大,越过了「模型复杂度足以完全拟合训练数据」(比如可以用模型为数据点取差值)的那个点之后,测试误差就可以持续下降!有趣的是,越大的模型往往能给出越好的结果,已经跳出了以往的「复杂度甜点」的考虑范畴。如下图。
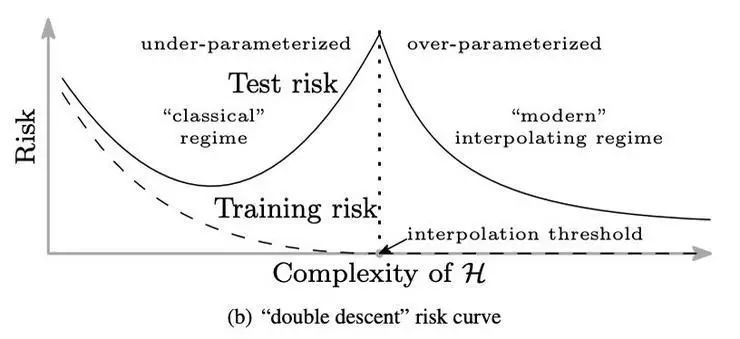
有人怀疑深度学习中使用的优化算法,比如梯度下降、随机梯度下降以及各种变体,其实起到了隐式地限制模型复杂度的效果(也就是说,虽然整个模型中的参数很多,但其中真正独立有效的参数只有一部分),也就避免了过拟合,避免了测试误差和训练误差相差过大。
另外,「越大的模型往往能给出越好的结果」,所以很自然地有人会问「如果我们有一个无限大的网络,它的表现会如何?」按照上面那张双峰图,答案就对应着隐藏在图像的最右侧的东西。上一年中这是一个热门的研究问题:神经网络的宽度,也就是卷积层中的通道数目、或者全连接隐层中的神经元数目,趋近于无穷大的时候会得到怎样的表现。
核方法带来一个契机
乍看上去这个问题是无解的,要做实验的话,有再多的计算资源也无法训练一个真正「无限大」的网络;而要理论分析的话,有限大小的网络都还没有研究清楚呢。不过,数学和物理领域一直都有研究「趋于无限大」从而得到新的见解的惯例,研究「趋于无限大」也在理论上更容易一点。
研究深度神经网络的学者们可能还记得无限宽的神经网络和核方法之间的联系,25 年前 Neal (https://www.cs.toronto.edu/~radford/pin.abstract.html)阐述过,Lee 等(https://openreview.net/forum?id=B1EA-M-0Z)和 Matthews 等(https://arxiv.org/abs/1804.11271)近期也做了拓展。这些核可以对应所有参数都随机选择、且只有最上层(分类器层)用梯度下降训练过的的无限宽的深度神经网络。具体来说,如果我们用 θ 表示网络中的参数集,x 表示网络的输入,就可以把输出表示为 f(θ,x);接着,W 是 θ 之上的初始化分布(通常是带有一定缩放的高斯分布),那么对应的核就是
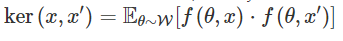
,其中 x、x' 是两个输入。
那么更常见的「网络中所有的层都是训练过的」这种情况呢?Jacot 等(https://arxiv.org/abs/1806.07572)近期发现这也和一种核有关系,他们把它称为 neural tangent kernel(NTK,神经正切核),它的形式可以写作
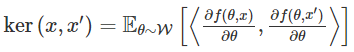
NTK 和之前提出的核的关键区别在于,NTK 是由网络的输出相对于网络参数的梯度之间的内乘积来定义的;其中的梯度来自训练网络时使用的梯度下降算法。概括地说,对于一个梯度下降训练出的足够宽的深度神经网络,下面这个结论是成立的:
一个正确地随机初始化的、足够宽的、由具有无穷小步长大小(也就是梯度流 gradient flow)的梯度下降训练的深度神经网络,和一个带有 NTK 的确定性核回归预测器是等效的。
这个结论在 Jacot 等最初的论文(https://arxiv.org/abs/1806.07572)中就基本确立了,不过他们要求网络的各个层依次趋近于无限大。在 Sanjeev Arora, Zhiyuan Li, Ruslan Salakhutdinov and Ruosong Wang 等人最新的论文(https://arxiv.org/abs/1904.11955)中,他们把这个结果做了进一步的改进,让它对非对称环境也适用,也就是每层的宽度不用依次变大,只需要都高过某个有限的阈值就可以。
NTK 是如何出现的?
详细的推导过程在论文(https://arxiv.org/abs/1904.11955)中有介绍,这里我们只简单提一下。作者们在标准的有监督学习环境下考虑这个问题,通过最小化训练数据上的二次方损失的方式训练神经网络。经过一系列推导,作者们得到了含有网络梯度项的核矩阵的表达式。
不过到这里为止作者们还没有使用「网络非常宽」的这个条件。当网络足够宽时,他们推导的核可以逼近某个确定性的固定核,也就是前面提到的 neural tangent kernel(NTK,神经正切核)。不过,确定「到底多宽才是足够宽」需要一些假设和技巧,在这篇论文中作者们最终得到的是只要网络的每一层的宽度各自大于某个阈值就可以,要比更早的结果中要求每一层宽度逐渐更趋近于无穷大的限制更弱一些。
最终作者们推导出训练后的无限宽神经网络和 NTK 是等效的。详细的推导过程请见论文原文。
无限宽的神经网络实际表现如何?
在证明了无限宽的神经网络和 NTK 等效之后,我们就有机会实际看看无限宽的神经网络的表现 —— 只要测试对应的使用 NTK 的核回归预测器就可以了!作者们在标准的图像分类测试集 CIFAR-10 上进行了测试。由于这是基于图像的任务,想要得到好的结果一定少不了卷积结构的参与,所以作者们也推导了卷积 NTK,并和标准的卷积网络进行对比。分类准确率对比如下:
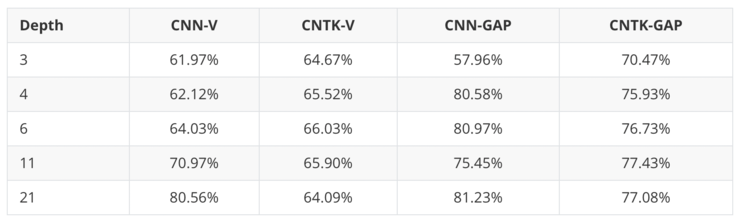
图中 CNN-V 是不带有池化的、正常宽度的 CNN,CNTK-V 是对应的卷积 NTK。作者们也测试了带有全局平均池化(GAP)的网络,也就是 CNN-GAP 和 CNTK-GAP。在所有实验中都没有使用批量标准化(batch normalization)、数据增强等等训练技巧,只使用 SGD 训练 CNN,以及 CNTK 使用核回归的解析方程。
实验表明 CNTK 其实是很强的核方法。实验中最强的是带有全局平均池化的、11 层的 CNTK,得到了 77.43% 的分类准确率。目前为止最强的完全基于核的方法来自 Novak 等(https://openreview.net/forum?id=B1g30j0qF7),而 CNTK 要比他们的准确率高出超过 10%。而且 CNTK 和正常 CNN 的表现都很接近,也就是说在 CIFAR-10 上超宽(无限宽)的 CNN 是可以取得不错的表现的。
另外有趣的是,全局池化不仅(如预期地)显著提升了正常 CNN 的准确率,也同样明显提升了 CNTK 的准确率。也许提高神经网络表现的许多技巧要比我们目前认识到的更通用一些,它们可能也对核方法有效。
结论
想要理解为什么过度参数化的深度神经网络还能有好得惊人的表现的确是一个很有挑战的理论问题。不过现在起码我们已经对一类非常宽的神经网络有了更多的了解:可以用 NTK 来表示它们。不过还有一个未解的困难是,关于核方法的经典泛化理论没法给出泛化能力的现实上下界。好在我们至少知道对核方法的更深的理解也可以帮助我们理解神经网络了。
另外我们还算探索出了一个新的方向,那就是把不同的神经网络架构、训练技巧转换到核方法上来,并检查它们的表现。作者们发现全局平均池化可以大幅提升核方法的表现,那很有可能 BN、drop-out、最大池化之类的方法也能在核方法中发挥作用;反过来,我们也可以尝试把 RNN、图神经网络、Transformer 之类的神经网络转换成核方法。
以及那个核心的问题:有限宽和无限宽的神经网络之间确实有性能区别,如何解释这种区别的原因也是重要的理论研究课题。
原论文:On Exact Computation with an Infinitely Wide Neural Net,无限宽的神经网络的精确计算
论文地址:https://arxiv.org/abs/1904.11955
本文编译自技术博客 http://www.offconvex.org/2019/10/03/NTK/, AI 科技评论编译。



点击“阅读原文”查看如何教神经网络玩 21 点游戏(附代码)?


