【干货】基于注意力机制的神经匹配模型用于短文本检索
【导读】在基于检索的问答系统中,很重要的一步是将检索到的答案进行排序得到最佳的答案。在检索到的答案比较短时,对答案进行排序也成为了一个难题。使用深度学习的方法,如建立在卷积神经网络和长期短期记忆模型基础上的神经网络模型,不需要手动设计语言特征,也能自动学习问题与答案之间的语义匹配,但是缺陷是需要词汇重叠特征和BM25等附加特征才能达到较好的效果。本文分析了出现这个问题的原因,并提出了基于值的权值共享的神经网络,并使用注意力机制为问题中的值赋予不同的权值。专知内容组编辑整理。
论文: aNMM: Ranking Short Answer Texts with Attention-Based Neural Matching Model

论文代码: https://github.com/yangliuy/aNMM-CIKM16
▌摘要
作为基于特征工程的问题答案方法的替代方法,最近已经提出了诸如卷积神经网络(CNN)和长期短期记忆模型(LSTM)的深度学习方法用于问题和答案的语义匹配。然而,为了获得好的结果,这些模型已经结合了词汇重叠或BM25分数等附加特征。没有这种组合,这些模型比基于语言特征工程的方法表现得更差。在本文中,我们提出了一种基于注意力的神经匹配模型来对短的答案匹配。我们采用价值共享权值,而不是位置共享权值方案来组合不同的匹配信号,并且注意力机制来衡量问题中判断问题中重要的部分。使用流行的基准TREC QA数据,我们表明,相对简单的aNMM模型可以显着超越已经用于问答任务的其他神经网络模型,并且与具有附加特征的深度学习模型相竞争。当aNMM与附加特征组合时,它的性能优于所有现有的模型。
▌简介
问答(QA)是一种具有挑战性的任务,它在下一代高级网络搜索中扮演着重要的角色。它将精确的答案组织成简短的事实或长篇段落返回给提出问题的用户。目前问答系统使用排序学习来编码具有复杂语言特征的问题/答案对。他们使用相似性特征,翻译特征,密度/频率特征和网络关联特征等特征,用于答案的排序学习,并使准确性得到显著的提高。然而,这样的方法依赖于手动特征工程,这经常是耗时的,并且需要领域依赖的专业知识和经验。此外,他们可能需要额外的自然语言解析器或外部知识来源,可能不适用于某些语言,泛化能力不强。
最近,研究人员一直在研究深度学习方法,以自动学习问题和答案之间的语义匹配。这种方法建立在神经网络模型(如卷积神经网络(CNN)和长期短期记忆模型之上。所提出的模型具有不需要手工制作的语言特征和外部资源的优点。他们中的一些为TREC QA竞赛的问答任务取得了最佳表现。然而,现有研究的薄弱之处在于,要达到良好的效果,所提出的基于CNN或LSTM的深度模型需要结合词汇重叠特征和BM25等附加特征。如果不把这些附加特征结合起来,它们的性能就会比基于语言特征工程的最先进的方法得到的结果要差得多。这导致我们提出以下研究问题:
1. 如果不结合其他功能,我们是否可以构建深度学习模型,与使用特征工程的方法相比,可以达到相当甚至更好的性能?
2. 通过结合附加功能,我们的模型可以超越问题回答的最先进模型吗?
为了解决这些研究问题,我们分析了现有的深度学习架构,并发现了以下两个事实:
1. 一些深度学习架构,如CNN不是专门为问题/答案匹配而设计的:有些方法使用CNN进行问题/答案匹配。然而,CNN最初是为计算机视觉(CV)设计的,计算机视觉使用位置共享权重和局部感知滤波器来学习,是因为许多CV任务的空间规律性,图片的像素点的分布很大程度上和周围的像素有关。然而,问题与答案之间的语义匹配可能不存在这样的空间规律性,由于自然语言的复杂语言特性,问答词之间的重要相似性信号可能出现在任何位置。同时,基于LSTM的模型依次查看问题/答案匹配问题办法。如果问题和回答之间没有直接的交互作用,模型可能无法捕捉到足够详细的匹配信号。对此,本文提出的改进是,将基于位置的权值共享改变成基于值的权值共享。
2. 缺乏建模问题重点:理解问题的重点,例如问题中的重要术语,有助于正确排列答案。例如,在“汉堡王第一家餐厅在哪里打开”这个问题,关于“汉堡”,“国王”,“开放”等等的答案是至关重要的。大多数现有的文本匹配模型并不明确模型问题的重点。例如,基于CNN的模型在匹配回答术语时将所有问题术语视为同等重要。基于LSTM的模型通常将问题术语模拟得更接近尾声更重要。对此,我们提出了注意力机制,为问题中的词按照重要性赋予不同的权值。
▌模型简介
根据上面的讨论,结合发现的问题和解决方案,我们提出了两种模型,aNNM-1(Attention-Based NeuralMatching Model)和aNNM-2,其中后者是对前者的细微改进。
aNMM-1
模型的构建主要分成三步。
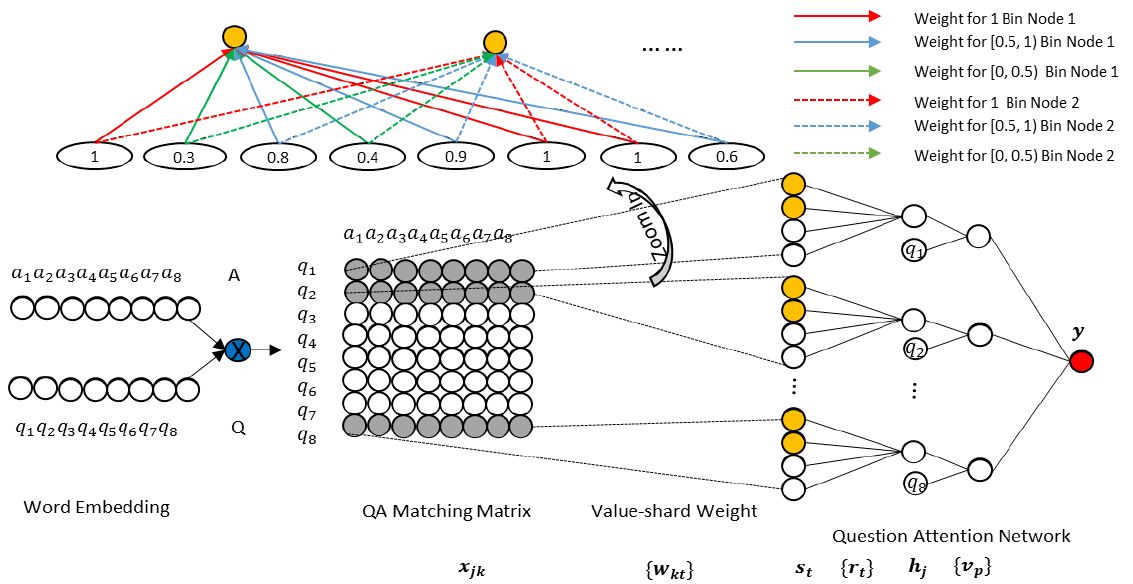
1. 对问题和答案对中的词使用wordEmbedding进行编码,然后使用余弦相似度计算QA 匹配矩阵。假设一个问题对<Q,A> 中,问题Q有M个词,答案A有N个词,问题和答案中的每次词使用embedding后的向量计算余弦相似度,得到M*N的QA匹配矩阵P,每个问答对都有一个匹配矩阵。那么问题来了,同一个问题的不同答案的词的个数不一样,得到的匹配矩阵的大小不一样,不利于后面神经网络中的全连接计算。为了将不一样的矩阵的维度变成一致的,参考了CNN+Maxpooling的做法,对矩阵按行处理,最终的得到M*1的一个向量。
2. 使用基于值的权值共享将匹配矩阵编程相同维度。CNN的关键思想是,相对位置一致的一些结点权值共享,这也是基于图像的像素点和周围像素点关系很大的假设之上的。使用基于位置的权值共享时,可表示成如下所示,其中同样颜色的边表示相同的权值。
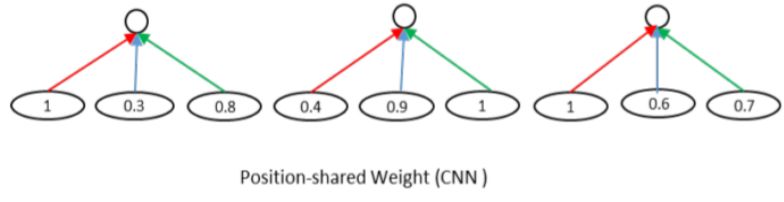
然而,问题与答案之间的语义匹配可能不存在这样的空间规律性,因此,采用相同的值共享权值的方式,来组织网络,如下图所示。其中,匹配矩阵中相似度为1的所有节点共享一个权值,相似度在[0,0.5)之间的节点,共享一个权值,相似度在[0.5,1)之间的节点,共享一个权值。通过这样的方式,可以将计算得到的匹配矩阵转换为相同维度的,并且不管输入矩阵的维度怎么样,隐层节点的个数是固定的。
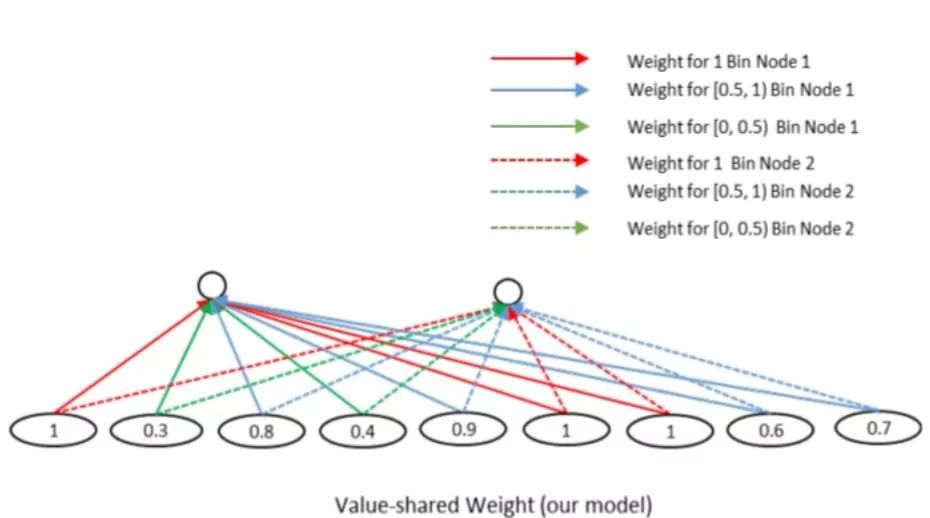
3. 使用问题的注意力机制,学习问题中每个词的重要度,并该问答对最后的分值。经过前两步,每一个QA对都可以计算得到一个M* 1 的向量,向量中的每一个元素代表了这个答案与问题中的每一个词的相似度,为了计算最后的相似度,我们并不是将这些值直接相加,得到整个问题与答案之间的相似度,而是为每个词赋予不同的权值,然后再加权。为了完成这一点,我们增加了一个参数v 并使用作为每个问题的权值加权,最后得到问答对之间的相似度。
aNMM-2
aNNM-2相对于aNMM-1的改进是,使用多个基于值的权值网络,就像CNN有多个滤波器一样,这样做可以提取多方面的特征。因为隐层的结构由M*1 变成了M*k,其中k为 共享权值的组数,为了让网络的结构与aNMM-1 尽可能相似,aNMM-2 多了一个隐层,即将从第一个隐层学到的多个分值合并起来,其他结构没有改变,结构如下所示:
▌总结
在本文中,我们提出了一种基于注意力的神经匹配模型来排序简短的答案。我们采用值共享加权方案,而不是位置共享加权方案来组合不同的匹配信号,并且使用注意力机制完成问题相关词的重要性学习。我们与没有附加特征的使用语言特征工程的状态方法相比,我们的模型可以实现更好的性能。通过简单的附加特征,我们的方法可以实现当前现有方法中最新的最新性能。
参考文献:
https://dl.acm.org/citation.cfm?id=2983818
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!


