【CQA论文笔记】基于卷积深度相关性计算的社区问答方法,建模问题和回答的匹配关系
【导读】将基于社区的问答(CQA)网站变得越来越火,用户通过它们可以从其他用户那里获取更为复杂、细致和个性化的答案。但是现有的方法主要是基于词包,但在短文本匹配任务中,词包不足以捕获重要的词序列信息。这篇论文提出使用了一个相似性矩阵,来同时捕捉词汇和序列信息,建模问题和回答之间复杂的匹配关系,这些信息被放入深度网络,来预测匹配的回答。这篇论文使用了一个类似LeNet的卷积网络,通过QA相似性矩阵来计算问题与回答之间的匹配度,这种思路值得借鉴。
【AAAI2015 论文】
Question/Answer Matching for CQA System via Combining Lexical and Sequential Information

▌摘要
基于社区的问答(CQA)网站变得越来越火,用户通过它们可以从其他用户那里获取更为复杂、细致和个性化的答案。社区里积累了大量的问题和相关的答案,如何从这些历史问题中检索最相关的回答是CQA中很重要的一个组件。现有的很多方法基于词包,词包在许多文本匹配任务中被证明很有效果。但在短文本匹配任务重,词包不足以捕获重要的词序列信息。本文提出一种新的架构,它可以建模问题和回答之间复杂的匹配关系。它使用了一个相似性矩阵,来同时捕捉词汇和序列信息。这些信息被放入深度网络,来预测匹配的回答。实验结果表明,我们的方法提升了匹配的准确性。
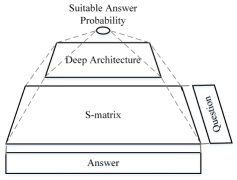
▌相似性矩阵
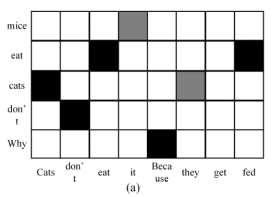
下图是文章算法的核心,QA相似性矩阵。垂直方向代表问题,水平方向代表回答。矩阵中的每个元素代表问题中的某个词的词向量与回答中的某个词的词向量的Cosine相似度。
注意,问题和回答中的单词都是按照原始顺序摆放的,这使得当问题和回答中有相同或相似序列时,矩阵中Cosine相似度的分布会呈现一定的规律性。
因此QA相似性矩阵既能捕捉问题和回答中词与词之间的关系,还能捕捉到词序列的信息。从下图可以直观地看出,相关问答的相似性矩阵和不相关回答的相似性矩阵可能会呈现出不同的分布。可以通过一个深度网络来捕获相似性矩阵的分布并用它来预测问题和回答之间的相关性。
▌深度相关性计算
与普通的特征向量不同,QA相似性矩阵是2维的特征(矩阵),另一方面,算法希望能够捕捉到QA相似性矩阵中的序列信息。因此,卷积网络在这里是非常合适的用来捕捉QA相似性矩阵包含的信息的模型。文章中的算法使用了一个类似LeNet的卷积网络,通过QA相似性矩阵来计算问题与回答之间的匹配度:
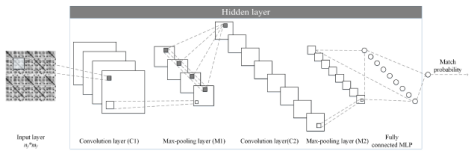
注意网络的结构与LeNet有一定的差别,LeNet的最后一层是一个用来做分类的Softmax层,神经元的个数等于类别数。而图中网络的最后一层只有一个神经元,用于做回归,计算问题与回答之间的相似度。 在训练时并不是输入QA相似度矩阵来拟合他们之间的相关性,而是对于一个三元组(x, y+, y-)(x是一个问题,y+是相关的回答,y-是不相关的回答),利用Triplet Loss来学习如何预测问答之间相关性:
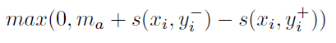
这个Loss也被称为Max-Margin Loss,其中ma表示边界距离。
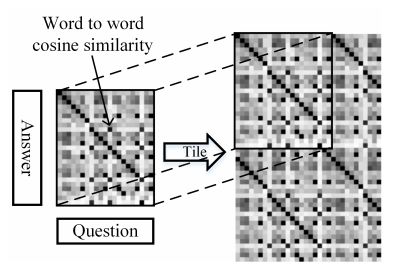
目前还存在一个问题,对于不同的QA对,QA相似性矩阵的形状是不一样的,这样的矩阵很难放到通用的深度学习框架中进行学习,因此需要对QA相似性矩阵进行一定的处理。该算法将QA相似性矩阵进行平铺和裁剪(如下图),使得每个QA相似性矩阵最后都变为统一的大小。
▌总体流程
训练完成后,输入一个QA对,计算它们的QA相似性矩阵,再通过深度网络即可计算它们的相关度。
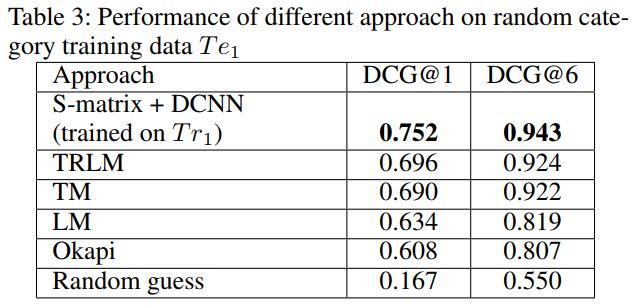
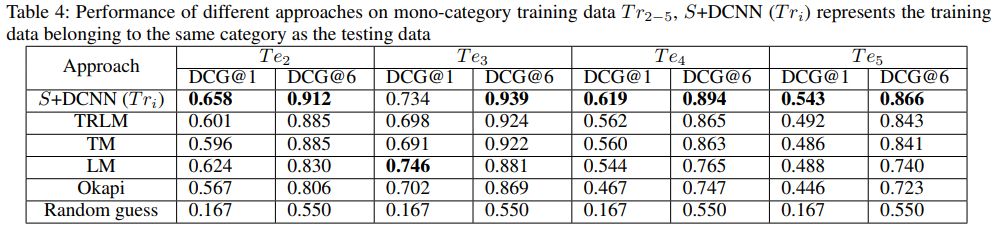
▌性能
该算法在实验中表现出不错的性能:
参考链接:
https://pdfs.semanticscholar.org/81eb/0a1ea90a6f6d5e7f14cb3397a4ee0f77824a.pdf
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

点击“阅读原文”,使用专知!

