KDD 2018 | 腾讯提出用于文本匹配的多信道信息交叉模型,在真实任务中表现优异
选自腾讯
机器之心编译
参与:张倩、路
来自腾讯 MIG 移动浏览产品部和阿尔伯塔大学的研究者提出一种用于文本匹配的新模型 MIX,这是一个多信道信息交叉模型,大大提升了文本匹配的准确率,在 QQ 浏览器搜索直达业务使用中也表现出了优秀的性能,相对提升点击率 5.7%。目前,这篇长论文已经被 KDD 2018 接收。
1 引言
短文本匹配在信息检索、问答、对话系统等自然语言处理任务中起着至关重要的作用。早期的文本匹配方法包括基于检索知识库的自动问答,以及基于词匹配和特征交叉(feature crossing)的 ad-hoc 检索 [17, 24]。然而,这些方法都依赖于手动定义的模板和规则,限制了调整良好的模型的泛化能力及其面向不同任务需求的可移植性。近年来深度神经网络模型的发展为提高自然语言处理能力带来了新的机遇。通过减少对人工特征工程的需求,深度网络模型可以更好地泛化,处理多种任务。近年来,研究者提出大量基于卷积神经网络和循环神经网络的深度网络结构,用于短文本匹配 [2, 3, 6, 7, 9, 11–15, 19–21, 23]。
本文对近年来出现的大量文本匹配深度学习技术进行了现实检验,发现尽管各种深度网络模型都有创新之处,但在实际应用中,尤其是在深度模型与语言结构和语义特征分析相结合的情况下,这些模型仍有很大的改进空间。本论文作者设计了一个多信道信息交叉模型(Multi-Channel Information Crossing,MIX),这是一个用于文本匹配的多信道卷积神经网络(CNN)模型,它在腾讯的线上流量中表现出了优秀的性能。
MIX 是 CNN 在多种粒度下的一种新型融合,并具有精心设计的注意力机制。MIX 的基本思想可以概括为:首先,MIX 使用在不同粒度下提取的特征来表征文本片段,这些特征是从实验观察到的与短语、词组、句法和语义、词频和权重,甚至语法信息相关的多个粒度中提取的,这是充分挖掘深层模型潜力的必要实践。文本匹配在多级特征上的组合会将深层架构表达所有级别的局部依赖性的能力最大化,并将卷积过程中的信息损失最小化。
其次,MIX 还提出了一种新型融合技术来组合来自多信道的匹配结果。MIX 中有两种类型的信道,两个文本片段的特征可以通过这些信道进行交互。其中一种是语义信息信道,它表示文本的意义,如一元分词、二元分词和三元分词。另一种信道包含 term 权重、词性和命名实体等结构信息以及交互的空间相关性。在 MIX 中,语义信息通道的作用是相似度匹配,而结构信息通道发挥注意力机制的作用。此外,MIX 使用 3D 卷积核来处理这些堆叠层,从多个信道提取抽象特征,并通过多层感知器来组合输出 [5]。信道组合机制使得 MIX 能够轻松地将新信道合并到其学习框架中,从而使 MIX 能够适用于广泛的任务。
研究者在腾讯的 Venus 分布式信息处理平台上实现并部署了 MIX,基于多个数据集和在腾讯 QQ 移动浏览器中的在线 A/B 测试对 MIX 进行了评估。在线评估部分中,研究者在英文问答数据集 WikiQA [25] 和一个从 QQ 移动浏览器收集的中文搜索结果数据集上测试了 MIX。WikiQA 是一个可公开访问的数据集,包含微软提供的开放域问答对。在 WikiQA 数据集上,MIX 在 NDCG@3 上的表现比多种当前最优方法至少高 11.1%,NDCG@3 是衡量排名质量的常用指标,在搜索引擎评估中被广泛采用。
另一个中文搜索结果数据集是在用户同意的情况下从腾讯 QQ 浏览器收集的,并从每天 1000 万活跃用户产生的在线搜索流量中采样得来。该数据集包括 12 万个 query-document 条目和审核者生成的标签,这些标签显示数据集中每个 query-document 对的匹配程度。在此数据集上,MIX 在 NDCG@3 方面的表现至少比所有其他当前最优方法高出 8.2%。
此外,在腾讯 QQ 浏览器的在线 A/B 测试中,与未使用 MIX 的设置相比,MIX 实现了 5.7% 的点击率增长。评估结果展示了 MIX 在生产环境中提升文本匹配准确率方面的优秀性能,以及它可以泛化至不同语言数据集的能力。
3 MIX 模型
本章介绍 MIX 模型的细节。研究者将全局匹配定义为两个句子之间的匹配,将局部匹配定义为句子中文本元素之间的匹配。受基于互动的模型的启发,MIX 模型组合使用全局匹配和局部匹配技术,对两个文本片段之间的相关性进行建模。依赖于深度神经网络强大的表征学习能力,MIX 模型能够有层次、多维度地描绘文本匹配问题的本质。如图 1 所示,MIX 模型将文本匹配问题高效分割为以下子问题:
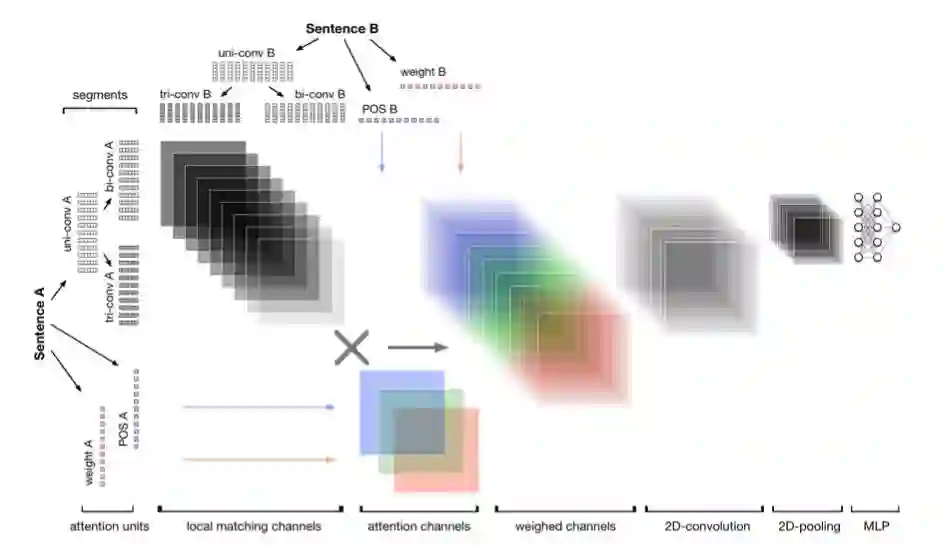
图 1:MIX 模型架构图示。
首先,如图 1 左上方所示,句子被解析成不同粒度的文本片段,如一元分词、二元分词和三元分词。用这种方式,MIX 通过找到文本片段最合适的语义表征(可以是单词、短语或词组)来改善局部匹配的准确率。这里的目标是尽可能多地捕捉不同互动级别上的信息。
其次,如图 1「attention units」部分所示,研究者提取语法信息,如相对权重和词性标注,据此在注意力信道中设计注意力矩阵,以封装丰富的结构模式。研究者使用该方法首先研究了全局匹配和局部匹配之间的关系,然后证明其注意力机制能够基于局部匹配构建全局匹配,从而增强整体匹配的质量。
第三,如图 1「weighed channels」和「2D-convolution」部分所示,研究者将局部匹配信道和注意力信道交叉起来,以为局部匹配提取有意义的特征组合。

图 7:空间注意力层的元素对应亮度。
4 性能评估
4.1 离线测试
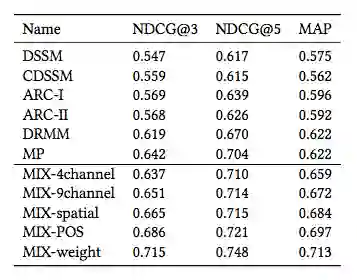
表 1:在 WikiQA 数据集上的单机测试评估结果。
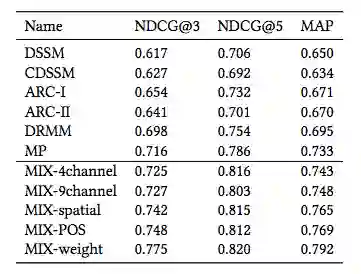
表 2:在 QBSearch 数据集上的单机测试评估结果。
4.2 在线测试
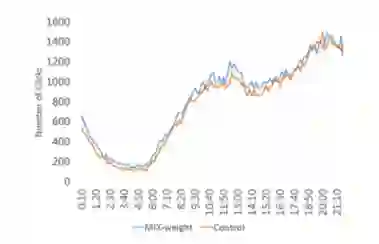
图 8:在线 A/B 测试中返回搜索结果上的点击数。
图 9:在线 A/B 测试中两组的反射率(每小时点击数)及对应箱线图。
论文:MIX: Multi-Channel Information Crossing for Text Matching

摘要:短文本匹配在信息检索、问答和对话系统等多项自然语言处理任务中发挥重要作用。传统的文本匹配方法依赖于预制模版和规则。但是,对于只有有限单词的短文本来说,这些规则无法很好地泛化至未观测数据中。随着深度学习在计算机视觉、语音识别和推荐系统领域中的成功运用,近期很多研究致力于将深度神经网络模型应用于自然语言处理任务,以降低人工特征工程的成本。
本论文提出了 MIX 模型(Multi-Channel Information Crossing),该多信道卷积神经网络模型可用于生产环境中的文本匹配,它具备针对句子和语义特征的额外注意力机制。MIX 在不同粒度上对比文本片段,以形成一系列多信道相似度矩阵,它们与另一组精心设计的注意力矩阵交叉起来,将句子的丰富结构展示给深度神经网络。
我们实现了 MIX,并将该系统部署在腾讯 Venus 分布式计算平台上。由于 MIX 具备工程设计极佳的多信道信息交叉,因此在 WikiQA 英文数据集上的评估结果显示:MIX 在归一化折扣累计增益(normalized discounted cumulative gain,NDCG@3)指标上优于大量当前最优深度神经网络模型,至少高出 11.1%。
此外,我们还利用腾讯 QQ 浏览器的搜索服务使用户执行了在线 A/B 测试。结果显示 MIX 将返回结果点击量提高了 5.7%,原因在于 query-document 匹配准确率有所提高,这展示了 MIX 在现实生产环境中的优秀性能。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


