如何瞬间找到视频中的目标片段?这篇顶级论文帮你详解CDC网络如何实现视频的精准定位

作者|周翔
据寿政介绍,哥大最近两年的视频分析主要是做 Temporal Video Localization(视频时间定位)方面的工作:
给定一段长视频,里面可能发生了一些我们感兴趣的 action,event,或者 activity,剩下的部分则是背景内容,如何能够让机器自动找到我们感兴趣的部分在视频中的开始时间和结束时间呢?
去年,寿政所在小组——“数字视频多媒体实验室”的论文“Segment-CNN:Temporal Action Localization in Untrimmed Videos via Multi-stage CNNs”也被 CVPR 2016 收录,该论文应用端到端的深度学习方法进行了初步尝试。今年,也就是他们 CVPR 2017 的工作,则尝试了新型的卷积逆卷积(CDC)网络。
以下是论文简介:

参与 | 周翔
时序动作定位是一个非常重要但又极具挑战的问题。给定一段未剪辑的长视频,里面包含多个动作实例和复杂背景内容,我们不仅要识别动作类别,还要定位每个动作实例的开始时间和结束时间。许多先进的系统都使用片段级别的分类器(segment level classifier),来选择和排列预确定边界(predetermined boundaries)的候选片段(proposal segment)。但是,理想的模型不应只停留在片段级别,而要能在精细的时间粒度上作出密集的预测,以确定精确的时序边界。
为此,我们设计了一种新型的卷积逆卷积(CDC)网络,它在 3D 卷积网络的顶层上安置了 CDC 过滤器,试验证明 3D 卷积网络在提取动作语义时效果很好,但是却减小了输入数据的时序长度。我们设计的 CDC 过滤器可以同时执行必要的时序增采样(temporal upsampling )和空间降采样(spatial downsampling ),以此预测帧数级别的时间粒度上的行动。这种网络的独到之处在于它可以同时在时空级和粒度级的时序动态中对动作语义进行建模。我们用端对端的方式对CDC网络进行了高效的训练。我们的模型不仅在检测每一帧中的动作时表现出色,而且极大地提升了对时序边界的定位精度。结果证明,CDC 网络在处理视频时效率非常高,在单一GPU服务器的驱动下它每秒可以处理500帧。点击https://bitbucket.org/columbiadvmm/cdc 获取源代码和训练后的模型。
最近,时序动作定位在计算机视觉界引起了极大的关注。时序动作定位涉及两个主要问题:
确定一段视频是否包含特定动作(例如跳水、跳跃等);
确定每个动作实例的时序边界(开始时间和结束时间)。
许多优秀的系统使用的都是这样一种典型的框架:融合大量的特征 + 训练可以在滑动窗(sliding window)或 segment proposals 上运行的分类器。不久前,一种基于 3D 卷积网络的“分段卷积网络(Segment-CNN ,S-CNN)”在 THUMOS’14 这样的基准数据集上表现出了卓越的效率和精确度。
S-CNN包含一个用于生成候选视频片段的候选网络(proposal network)和一个用于预测动作类别的片段级别分数的定位网络(localization network)。尽管定位网络经过优化之后可以选出与实际视频动作实例重叠度较高的片段,但是检测出的动作边界仍然存在,因此候选网络只能识别出一组固定候选片段的预确定边界。
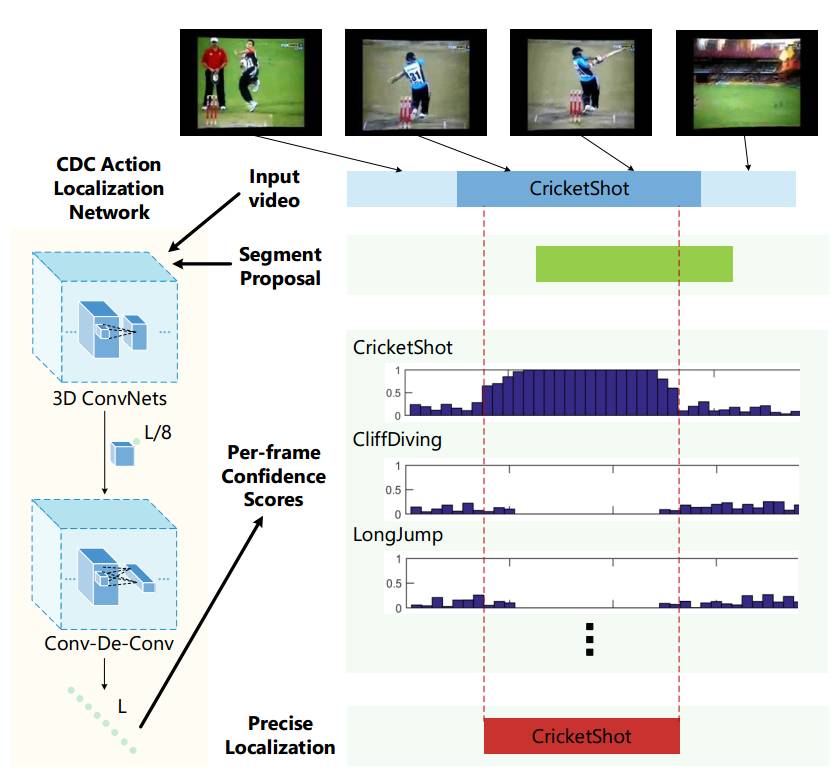
图1. 精确定位时序动作的框架
给定一段原始输入视频,将其输入到我们的 CDC 定位网络中,其中 3D 卷积神经网络用于提取语义,新型 CDC 网络用于对密集的帧数级分数作出预测。结合此类粒度级分数序列和候选视频片段(segment proposals),对动作实例的时间边界进行精确识别。
如图 1 所示,我们的目标是从进一步细化候选片段的时序边界,以准确地定位动作实例的边界。我们不满足于基于片段级预测的现有系统,而着力钻研对时间进行粒度级的密集预测。为了实现该目标,我们应用了一些现有的方法:
用单帧数分类器单独处理每一帧;
再用递归神经网络(RNN)确定不同帧数之间的时序依赖性。
但是这两种方法都无法对原始视频中的时空(spatio-temporal)信息进行清晰的建模。
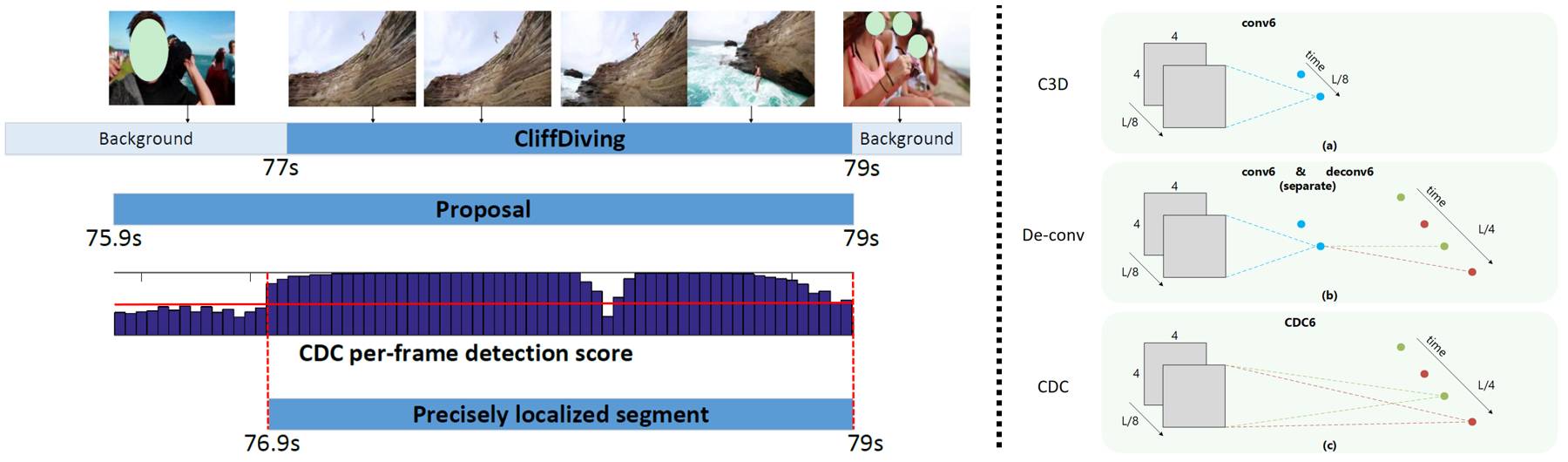
试验证明,3D CNN 可以直接从原始视频中学习高级语义的时空信息,但是在时间上会存在粒度损失,正如上文所述这对精确定位十分重要。例如,在我们所熟知的 C3D 架构中,conv1a 与 conv5b 之间的卷积层会将输入视频的时序长度减少到 1/8。在像素级别的语义分段中,事实证明在对图像和视频行处理以得出与输入图像分辨率相同的输出图像时,逆卷积不失为一种高效的增采样(upsampling)方法。对于时序定位问题,输出视频的时序长度应和输入视频的时序长度相同,但是空间尺寸应缩小至 1x1。
因此,我们不仅需要对时间进行增采样,而且还要对空间进行降采样。为此,我们设计了一种新型的卷积逆卷积(CDC)过滤器,它可以同时对空间进行卷积(以提取语义),并对时间进行逆卷积(以得到帧数级别的分辨率)。CDC 的独到之处在于它可以同时对空间的高级语义归纳和时间的粒度级动作态势推断之间的时空相互作用进行建模,在 3D 卷积神经网络上,我们堆叠了多个 CDC 层以构建我们的 CDC 网络,这种网络可以实现上文所述的时序增采样和空间降采样目标,进而可以确定动作类别以及提取候选片段的时间。
总的来说,本文有三大贡献:
据我们了解,我们的工作最先结合两种反向操作来构成 CDC 过滤器,同时对空间和时间分别进行增采样和降采样,以此推断高级动作语义和时间粒度级别的时序动态。
我们使用自行设计出的 CDC 过滤器构建了一个 CDC 网络,专门用于对时序动作进行精确的定位。可以使用原始视频对该 CDC 网络进行高效的端对端训练,以得出密集的分数,用以预测动作实例的精确时间边界。
我们的模型在视频逐帧动作标记上优于目前最先进的方法,它极大地提高了时序动作定位的精度。
总的来说,该篇论文尝试了帧率级别(frame-level)的时序动作检测,先获取每帧的得分序列(per-frame score sequence),然后用它来调整候选片段,从而找到更准确的边界。
寿政表示,前些年大家主要还是做视频分类或者已编辑短视频里面的定位,随着一个叫THUMOS'14 数据集的出现,16年大家逐渐开始做未剪辑里面检测的问题,也就是 Temporal Localization。最近也出现了 ActivityNet,Charades 等等新的各具特色数据集,为这个课题提供了更多新的探索方向。相对于目标检测已经取得的成果,目前 Temporal Localization 还有很多工作需要做。
在AI科技大本营微信公众号(rgznai100)会话回复“目标”,下载《在未分割视频中对时序动作进行精确定位的卷积—逆卷积神经网络》论文
关注AI科技大本营,进入公众号,回复对应关键词打包下载学习资料
回复:CCAI,下载《CCAI 2017嘉宾演讲PPT 》
回复:路径,下载深度学习Paper阅读路径(128篇论文,21大领域)
回复:法则,下载《机器学习的四十三条经验法则》
回复:美团,下载《深度学习在美团外卖的应用,NLP在美团点评的应用》,《NLP在美团点评的应用》pdf
回复:沙龙,下载CSDN学院7月15日线下沙龙PPT(蒋涛、孟岩、智亮)
回复:对抗,下载台大李宏毅老师关于生成对抗学习视频教程(附PPT)
回复:AI报告,下载麦肯锡、波士顿、埃森哲咨询公司AI报告
回复:银行,下载银行和证券公司的AI报告
回复:人才,下载 2017 领英《全球AI领域人才报告》
回复:发展,下载2017 全球人工智能发展报告_框架篇
回复:设计,下载人工智能与设计的未来
回复:1986,下载李开复1986年论文《评价函数学习的一种模式分类方法》和1990年论文《The Development of a World Class Othello Program》

人类感知外界信息,80%以上通过视觉得到。2015年,微软在ImageNet大赛中,算法识别率首次超越人类,视觉由此成为人工智能最为活跃的领域。为此,AI100特邀哈尔滨工业大学副教授、视觉技术研究室负责人屈老师,为大家介绍计算机视觉原理及实战。扫描上图二维码或加微信csdn02,了解更多课程信息。




