如何在不同摄像头里识别行人?多层相似度感知CNN网络解析

阿里妹导读:行人重识别是指给定一个摄像头下某个行人的图片,在其他摄像头对应的图片中准确地找到同一个人。行人重识别技术有十分重要的科研和实际应用价值,近来广泛应用到交通、安防等领域,对于创建平安城市、智慧城市具有重要的意义。可能有人会说“人脸技术”的应用已经很成熟了,然而在复杂的实际场景中,由于低分辨率、遮挡、不同角度等各种原因,“人脸”很难看清。因此,利用人的全身信息来做检索就变得非常有必要。本篇论文收录于ACM MM 2017(多媒体领域世界顶级会议),提出了全新的基于 CNN 的行人重识别方法,接下来,我们一起进行深入思考。
作者:申晨、金仲明、赵一儒、付志航、蒋荣欣、陈耀武、华先胜
摘要
行人重识别(person re-ID)的目的是识别多个摄像头视角中的相关行人,这项任务在计算机视觉社区中已经得到了越来越多的关注。我们在本论文中提出了一种基于卷积神经网络(CNN)和多级相似度感知的全新深度孪生架构。根据不同特征图的不同特性,我们有效地在训练阶段将不同的相似度约束应用到了低层级和高层级特征图上。因此,我们的网络可以有效地学习不同层级的有判别性的(discriminative)特征表征,这能显著提升 re-ID 的表现。
此外,我们的框架还有另外两个优势。第一,可以轻松地将分类约束整合到该框架中,从而形成一个带有相似度约束的统一的多任务网络。第二,因为相似度的信息已经通过反向传播被编码在了该网络的学习参数中,所以在测试时并不必需成对的输入。这就意味着我们可以提取每张图库图像的特征并以一种离线的方式来构建索引,这对大规模真实世界应用而言至关重要。我们在多个有挑战性的基准上进行了实验,结果表明我们的方法相比于当前最佳方法表现出色。
1 引言
行人重识别(person re-ID)的目的是匹配一个行人在多个无交集的摄像头视角中的图像,这项任务凭借其研究和应用价值正获得越来越大的关注。但是,行人重识别仍然是一项非常具有挑战性的任务,因为不同身份实体之间的外观可能差异不大(见图 1(a)),而同一身份实体在不同光照、视角和部分遮挡(见图 1(b)、1(c)、1(d))情况下又可能差异很大。

图 1:行人重识别的各种复杂性示意图,来自 CUHK03 数据集的。绿框表示同一个身份,而红框则表示不同的身份。(d) 中的粉色框标示了一个突出的局部图案(手提袋),由于部分遮挡这很容易丢失。
从技术上讲,行人重识别有两大基本组成:特征表征和距离度量。最近,基于 CNN 的深度学习方法已经在行人重识别上表现出了出色的优越性,因为它能够联合学习复杂的特征表征和可区分的距离度量。
在本论文中,我们提出了一种全新的基于 CNN 的行人重识别方案,称为多级相似度感知卷积神经网络(MSP-CNN)。在训练阶段,我们会使用一种孪生模型(Siamese model),其使用图像对作为输入,并且所有图像都要经过同样的共享参数的深度 CNN 网络的处理。该基准网络是精心设计的,其中使用了非常小的卷积过滤器和 Inception 模块。接下来,我们深入思考了如何有效地将相似度约束应用到不同的特征图上。
图 2 给出了我们提出的网络在训练阶段的整体架构。图 3 给出了该网络在测试阶段的整体架构。
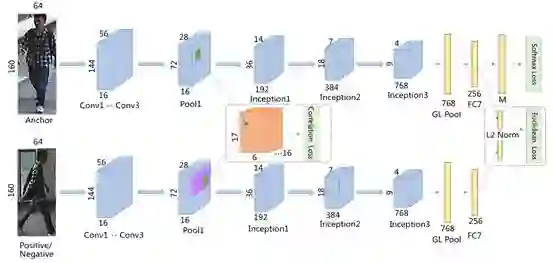
图 2:训练阶段的多任务框架示意图。具体说明一下,我们在低层级的 Pool1 层和高层级的 FC7 层分别优化相似度约束。正例(或负例)图像的 Pool1 层特征图上的紫色区域表示在获取局部形义模式时互相关所使用的宽搜索区域。另外也同时使用了 softmax 损失来优化分类约束,M 表示行人身份实体的数量。
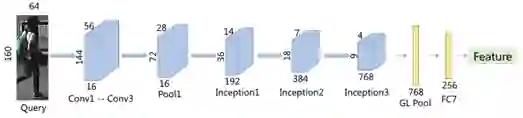
图 3:测试时间的网络架构
因此,我们的工作有三大关键优势和主要贡献。
我们提出了一种用于行人重识别的全新孪生模型,并且创新地在不同的特征图上应用了相应的距离度量。这种多级相似度感知机制能巧妙地匹配不同层级特征图的特性并显著提升表现。
我们使用了一种多任务架构来同时优化分类约束和相似度约束。多任务学习可以在解决多个相关任务的同时实现知识共享,从而将两者的优势组合到一起。
在测试时间,我们可以避免成对输入的时间低效的流程并且可以提取图像特征来事先构建索引,这对于大规模真实世界应用场景而言至关重要。
2 我们提出的方法
2.1 方法概述
借鉴[1]中提出的用于行人重识别的网络结构,我们精心设计了一个基于CNN的基础骨架网络,并期望它能仅使用单个 softmax 损失就得到优于大多数已有深度学习框架的强大基准结果。为了适应大多数行人图像的尺寸(通常很小而且不是正方形的),所有的输入图像都重新调整为 160×64 大小,并且为了数据增强而随机裁剪为 144×56 大小。
然后,我们从一种互补的角度考虑了相似度约束,并构建了一种分类任务的多任务架构。这种设计的目的是兼取二者之长,即充分利用行人重识别标注以及正例负例对之间相似度相当的信息。为了利用不同层级的特征图的相关性信息来更好地描述相似度约束(之前的大多数研究都忽略了这一点),我们可视化了我们的基本 CNN 分类网络所学习到的某些典型层的特征图。
如图 4 所示,低层级特征图的响应通常很密集并且反映了局部形义区域。比如,来自 Conv1 层 #0 通道的特征会强烈响应黑色区域(头发和裤子),而来自 Conv2 层 #9 通道的特征则重点强调明亮的白色区域(短袖衫)。这种现象也可以根据 Pool1 层的特征图进行验证。随着层越来越深,它们的特征图也会逐渐变得稀疏,而且往往会编码更加抽象的全局特征。比如,Inception(1a) 层的某些通道仍然反映的是局部形义区域(红色背包,#11),但大部分通道反映的都非常稀疏(#91)。其内部机制是:低层级卷积层所得到的可区分的局部特征会传播给高层级层(尤其是全连接层),这些特征会变得抽象并形成全局表征。

图 4:我们的基本 CNN 分类网络学习到的特征图的可视化。每一行都表示一个人的图像从低层级到高层级的某些典型特征图。第一行:锚图像;第二行:正例图像;最后一行:负例图像。我们也标注了每个特征图对应的通道号,用 # 号标记。
就低层级特征图而言,典型的局部区域(比如图 4 中的红色背包)在同一个人的图像中都有,这对区分正例对和负例对而言至关重要。因此,我们假设,对于第一张图像的特征图上的特定图块(patch),如果我们可以从另一张正例图像的对应特征图上找到其最相似的图块,那么这样的图块对就非常有可能表示了可区分的局部区域。根据以上假设,我们可以自然而然地设计出寻找和强调这个可区分的区域的目标,这样我们的网络就能向更高层传播更相关的特征。
受 [2] 的启发,我们采用了归一化互相关(normalized cross-correlation)作为一种非精确的匹配技术来匹配广大区域中的像素区域。[2] 中已经证明,使用归一化互相关和在更大区域上进行搜索能在视角变化很大、光照变化或部分遮挡的情况中保持稳健(robust)。归一化互相关分数取值范围为 [-1,1],其中 -1 表示特征向量完全不相似,1 表示特征向量非常相似。
因此,对于第一个特征图的每个局部图块,我们都要通过选择图块来找到第二个特征图中与其最相似的图块——该图块有最大的互相关响应。之后,我们设计了损失函数,其目的是根据正例对(即可区分的区域)来增强互相关分数,同时根据负例对(即某种扰动)减弱互相关分数。
因此,我们的设计可以适应性地更加重点关注正例对之间共有的局部语义可区分区域,并且能够通过前向传播沿更高层的方向放大这种局部相似度。应当指出,正例图像和负例图像之间也有一些共有的语义模式(比如黑发),但这些模式不能看作是可区分的信息。因此,对于负例对而言,我们会忽略这样的情况。
至于高层级特征图,尤其是全连接层的特征图,我们直接在 L2 归一化之后使用欧几里德距离来表示它们的相似度,并设计了用来降低正例对之间的距离并增加负例对之间的距离的损失函数。
2.2 多级相似度感知
低层级相似度。我们在 Pool1 层的特征图上应用了低层级相似度约束,如图 2 所示。
高层级相似度。高层级相似度约束(即优化欧式距离)应用在最后的全连接层的特征上(即图 2 中的 FC7 层)。
2.3 多任务网络架构
联合训练。前面已经提到,我们提出了一种全新的孪生网络,可以在训练阶段将不同的相似度约束应用到对应的特征图上。此外,我们将相似度约束和分类约束结合到一起构建了一个统一的多任务网络。
如图 2 所示,低层级和高层级相似度约束分别应用在 Pool1 层和 FC7 层上。这个选择也是由验证集决定的。
我们提出的训练 MSP-CNN 的流程分为两个阶段。我们首先使用 softmax 损失和欧式距离损失在对应的数据集上从头开始训练一个精心设计的 CNN 多任务网络。然后,我们加入低层级的互相关损失并继续训练该 CNN 几个 epoch。因为低层级层的梯度通常很小,所以直接为低层级层提供梯度的互相关损失应该在相对稳定的阶段得到更好的准确优化。此外,互相关损失收敛速度很快,所以我们只需要优化它少数几个 epoch 来防止过拟合即可。
测试。前面已经提到,每张图库图像的特征都可以按照图 3 给出的过程事先提取出来。当发生查询时,图库中的图像根据它们与探针图像(probe image)的相似度进行排序,其中图像特征之间的相似度是根据欧式距离计算的。我们甚至可以利用某些索引技术(比如倒排索引或哈希)来基于这些图像特征构建索引,从而进一步提升检索效率(尤其是对于大规模数据集)。
3 实验
3.1 数据集和协议
我们在大数据集 CUHK03、Market-1501 和小数据集 CUHK01 上进行了实验。在我们的实验中,我们使用了最常用的累积匹配特征(CMC)top-k 准确度来评估所有方法。我们还为 Market-1501 数据集使用了平均精度均值(mAP)。所有的评估结果都是单次查询的结果。
3.2 实现细节
受 [1] 的启发,我们精心设计了一个基本 CNN 网络,它主要由 3 个 CONV 模块、6 个 Inception 模块和 1 个 FC 模块组成。CONV 模块中有一个卷积(conv)层,后面跟着批归一化(BN)层和 ReLU 层。conv 层使用了一个非常小的过滤器(3×3)(受 VGGNet 的启发),BN 层的作用是加快收敛速度。Inception 模块是指 GoogLeNet,而且我们将每个 5×5 卷积都替换成了 2 个 3×3 卷积,就像 Inception-v3 建议的那样。FC 模块由一个全连接层以及后续的 BN 层、ReLU 层和 dropout 层构成。表 1 给出了详细结构。
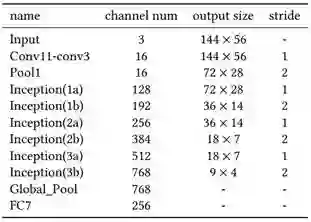
表 1:基本网络结构
我们的算法是基于深度学习框架 Caffe 实现的,运行在配置了一块英伟达 M40 GPU 卡的工作站上。
3.3 训练策略
我们设计了一种训练阶段的采样策略,让负例对的数量和正例对的数量之比为 2:1。如图 5 所示。
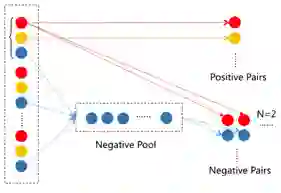
图 5:采样过程示意图。红色圆圈表示锚图像,橙色圆圈表示正例图像,蓝色圆圈表示负例图像。
数据增强。我们遵循了 AlexNet [3] 提出的经典技术。
4 结果和讨论
4.1 与当前最佳方法的比较
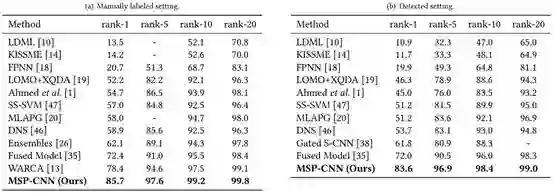
表 2:在 CUHK03 数据集上 CMC rank 分别为 1、5、10、20 时当前最佳方法的表现比较。(a)人工标注人类框的设置。(b)检测得到人类框的设置。
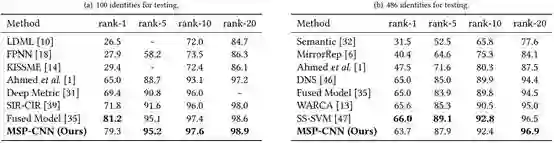
表 3:在 CUHK01 数据集上 CMC rank 分别为 1、5、10、20 时当前最佳方法的表现比较。(a)测试中有 100 个身份。(b)测试中有 486 个身份。
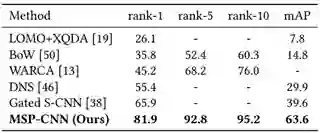
表 4:在 Market-1501 数据集上当前最佳方法的表现比较。
4.2 算法组成部分的有效性
以 CUHK03 有标注数据集为例,我们还详细研究了我们提出的算法中各个模块的效果,包括单独的基本分类深度网络、与高层级或低层级相似度约束相结合的分类约束、以及上述三者的综合。表 5 给出了结果。

表 5:在 CUHK03 有标注数据集上,算法的不同组成部分以及它们的组合所得到的表现比较。cls 是指分类约束(即 softmax 损失),sim_high 是指高层级相似度约束(即欧式距离损失),sim_low 是指低层级相似度约束(即归一化互相关损失)。
5 结论和未来工作
对于未来,我们打算寻找一个用于中层级层的合适优化目标并探索利用更多层特征图的效果。
参考内容:
[1]Tong Xiao, Hongsheng Li, Wanli Ouyang, and Xiaogang Wang. 2016. Learning deep feature representations with domain guided dropout for person reidenti cation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 1249–1258.
[2] Arulkumar Subramaniam, Moitreya Chatterjee, and Anurag Mittal. 2016. Deep Neural Networks with Inexact Matching for Person Re-Identication. In Advances in Neural Information Processing Systems. 2667–2675.
[3]Alex Krizhevsky, Ilya Sutskever, and Georey E Hinton. 2012. Imagenet classication with deep convolutional neural networks. In Advances in neural information processing systems. 1097–1105.
论文原文地址:
https://dl.acm.org/citation.cfm?id=3123452&dl=ACM&coll=DL#URLTOKEN#

每天一篇技术文章,
看不过瘾?
关注“阿里巴巴机器智能”,
发现更多AI干货。

↑ 翘首以盼等你关注

你可能还喜欢
点击下方图片即可阅读



关注「阿里技术」
把握前沿技术脉搏



